
The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

Star Schema Vs. Snowflake Schema: 4 Key Differences
Organizations rely on high-performance data warehouses for storing and analyzing large amounts of data. An important decision in setting up a data warehouse is the choice between Star Schema vs. Snowflake Schema.
The star schema simplifies the structure of a database by directly connecting dimension tables to a central fact table. The star shaped design streamlines data retrieval and analysis by consolidating related data points, thereby enhancing the efficiency and clarity of database queries. Conversely, the snowflake schema takes a more detailed approach, breaking down dimension tables into additional tables, resulting in more complex relationships where each branch represents a different aspect of the data.
Since a chosen schema sets forth the blueprint for organizing and structuring data within the data warehouse, it’s important to understand the key differences between snowflake schema vs. star schema to make the right choice. So, in this blog, we will discuss all about star and snowflake schema, including their important characteristics, example queries, and when to use which. Let’s delve in and see what each of these schema types offer and how they differ.
What is a Star Schema?
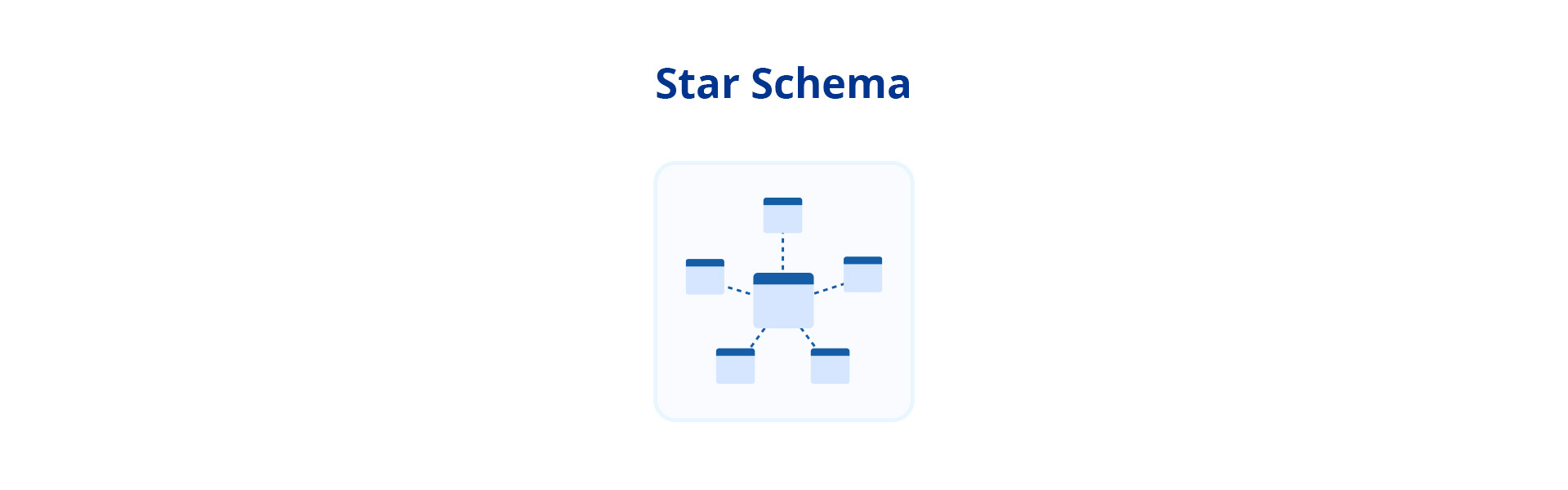
Star schema is a type of data warehouse schema that consists of one or more fact tables referencing multiple dimension tables. This schema revolves around a central table called the “fact table.” It’s surrounded by several directly connected tables called the “dimension tables.” Additionally, there are foreign keys that link data from one table to another, establishing a relationship between the two by using the primary key of another table. This process serves as a means of cross-referencing, ensuring connectivity and coherence within the database structure.
The fact table contains quantitative data, often called measures or metrics. The measures are typically numeric, like speed, cost, quantity, and weight, and they can be aggregated. The fact table contains foreign key references to the dimension tables, which contain non-numerical elements. These are descriptive attributes like product details (name, category, brand), customer information (name, address, segment), time indicators (date, month, year), etc. Each dimension table represents a specific aspect or dimension of the data. A dimension usually has a primary key column and is referenced by the fact table through foreign key relationships.
In a star schema:
- The fact table, which holds the primary metrics, is located at the center.
- Each dimension table is directly linked to the fact table but not to the other dimension tables, hence having a star-like structure.
The simplicity of Star schema facilitates aggregated reporting and analysis and streamlines data retrieval operations. This is because the queries typically involve fewer joins compared to more normalized schemas. The reduced complexity and simple structure optimize data access and processing, which is well-suited for cloud-based data warehousing solutions.
Moreover, it’s clear delineation between dimensions and facts enables users to analyze information across various dimensions easily. This makes star schema a foundational model in business intelligence applications, too.
Characteristics of Star Schema
Some main characteristics of a star schema are as follows:
- Central fact table: There’s a primary fact table containing metrics in the center. It represents activities, events, and business transactions.
- Dimension tables: They surround the fact table and represent the specific aspect of the business context. Dimension tables show descriptive attributes.
- Primary-foreign key relationships: The link between the fact and dimension table is established through primary-foreign key relationships, allowing for the aggregation of data across different dimensions.
- Connection with dimension tables: There are no connections made between the dimension tables. All the dimension tables are connected to the central fact table only.
- Denormalized structure: The dimension tables are often denormalized, which is beneficial in reducing the need for joins during queries as the necessary attributes are included within a single dimension instead of splitting them across multiple tables.
- Optimized query performance: Features like direct relationships between fact and dimension tables and the denormalized structure contribute to optimized query performance. This enables star schemas to handle complex analytical tasks and is thus a good fit for data analysis and reporting.
Star schemas are ideal for applications involving multidimensional analysis of data, such as OLAP (Online Analytical Processing). OLAP tools support the star schema structure efficiently to perform roll-up, drill-down, aggregation, and other analytical operations across different dimensions.
What is a Snowflake Schema?

A snowflake schema is an extension of the star schema model, where dimension tables are normalized into multiple related tables resembling the shape of a snowflake.
In the snowflake schema, there’s a central fact table that holds quantitative measures. This fact table is directly linked to dimension tables. These dimension tables are normalized into sub-dimensions that hold specific attributes within a dimension. Compared to a star schema, snowflake schema reduces data redundancy and improves data integrity, but it introduces additional complexity to the queries due to the need for more joins. This complexity often affects the performance and understandability of the dimension model.
Characteristics of Snowflake Schema
The following are the main characteristics of a snowflake schema:
- Normalization: In a snowflake schema, dimension tables are normalized, unlike in a star schema, where the tables are denormalized. This means that attributes within dimension tables are broken down into multiple related tables.
- Hierarchical structure: The normalization of dimension tables creates a hierarchical structure that gives a snowflake-like appearance.
- Relationship between tables: Normalization leads to additional join relationships between the normalized tables that increase the complexity of queries.
- Performance: Joining multiple normalized tables in a snowflake schema necessitates more computing power due to increased query complexity, potentially impacting performance.
- Data integrity: Snowflake schemas reduce redundancy and eliminate update anomalies. This ensures data is stored in a consistent and normalized manner.
- Flexibility: Snowflake schemas provide flexibility in organizing and managing complex data relationships that give a more structured approach to data analysis.
Key differences between Star and Snowflake Schema
1. Architecture
The dimension tables are denormalized in the star schema. This means they are represented as single tables having all attributes contained within them. The structure of this schema resembles a star, showcasing a fact table in the center and dimension tables radiating out from it.
A snowflake schema, on the other hand, has normalized dimension tables. This means they are broken down into multiple related tables. Such a normalization creates a hierarchical structure that resembles a snowflake, having additional levels of tables branching off from the main dimension tables.
2. Normalization
Star schemas are denormalized, where all attributes are within a single table for each dimension. This denormalization is done intentionally to speed up performance. However, its downside is that there might be data redundancy, i.e., the same data appearing in multiple dimension tables, requiring more storage.
A snowflake schema represents a normalized dimension table, with attributes broken down into multiple related tables. Snowflake schema design avoids data redundancy, improves data quality, and uses less storage space than a star schema.
3. Query Performance
Considering there are fewer join operations and a simpler table structure in a star schema, the query performance is usually better compared to the snowflake schema.
On the other hand, snowflake schema has complex join operations, which require access to data across multiple normalized tables. As a result, snowflake schema generally results in slower query performance.
4. Maintenance
Depending on several factors, such as data complexity and updates and storage space, maintaining both star and snowflake schemas can be challenging.
However, star schemas are generally easier to maintain compared to snowflake schemas due to their fewer join operations that simplify query optimization. However, the denormalized structure contributes to some level of redundancy, which requires careful management to improve the accuracy of data analysis and insights.
The normalization process in snowflake schemas increases complexity and makes it difficult to maintain. The joins require additional attention to maintain acceptable performance levels. Moreover, managing updates and inserts in the snowflake schema is more complex as there’s a need to propagate changes across multiple related tables. This can be compared to a star schema, where data is more concentrated in fewer tables. Updates typically affect only one or a few tables, making them simpler to manage.
Example Query
Let’s take the example of “Employee Performance Evaluation by Department and Training Courses Attended” to see how snowflake and star schemas are formed.
Star Schema: This query involves querying the fact table containing performance evaluation data and joining it with the dimension tables that represent departments, employees, and training courses. This fact table typically has a foreign key relationship with dimension tables. For instance, the dimension tables can include department dimensions (department ID, manager, name, etc.), employee dimensions (employee ID, job, title, etc.), and training course dimensions (course ID, name, duration).
Star schema is commonly used for simpler analytical needs where denormalization is preferred for performance reasons.
Snowflake Schema: In a snowflake schema, the dimension tables are further normalized into sub-dimensions, such as department hierarchy, training course categories, and employee details. The additional joins needed to access the normalized data slow down the execution times.
Star Schema Vs. Snowflake Schema: Choosing the Right Schema for Your Organization
Both the star schema and snowflake schema offer unique advantages, but choosing the right one for your enterprise data warehouse requires careful consideration. Here are some important factors to keep in mind when deciding between a star and snowflake schema:
Analytical needs: Evaluate the types of analyses and queries that your business requires, considering whether they lean towards more complex hierarchies or simple, straightforward analyses. If your business requires straightforward analyses with minimal complexity, a star schema might be preferable due to its simpler structure and fewer join operations.
On the other hand, if your analyses involve complex hierarchies and relationships between dimensions, a snowflake schema may be more suitable for its ability to represent these intricate relationships in a more organized manner.
Scalability: Consider future growth and scalability requirements to ensure the chosen schema can accommodate the changing data needs and scale effectively. For smaller data sets and simpler queries star schema’s denormalized structure performs better. In contrast, snowflake schema’s normalized approach may provide greater scalability and flexibility to handle larger datasets and more complex queries as your data needs grow over time.
Data Volume: Assess the effect of massive datasets on storage costs and capabilities before making your schema selection. Star schema’s denormalized design may lead to higher storage costs due to redundancy, whereas a snowflake schema’s normalized structure can help optimize storage efficiency by reducing redundancy. If storage costs are a significant concern, a snowflake schema may be a more cost-effective option for managing large volumes of data.
Understand your data: Analyze the structure and complexity of your data, including the relationships between different analyses. This will help in picking the right schema for your business. If your data exhibits a high degree of normalization and requires detailed analysis with many-to-many relationships between dimensions, a snowflake schema may be more appropriate. However, if your data is relatively simple and can be represented with fewer dimensions and straightforward relationships, a star schema may suffice.
Goals: Determine whether you require quick insights or comprehensive details. Opt for star schema for quick reporting and snowflake schema for detailed analysis. A star schema is well-suited to faster reporting and simple analysis, making it ideal for organizations that prioritize speed and agility in decision-making. In contrast, a snowflake schema offers more granularity and detail, making it suitable for organizations that require in-depth analysis and a deeper understanding of their data.
Conclusion
Star schema and snowflake schema have their merits and demerits. One of the reasons the star schema is more common is its simplified structure. While star schema is less complex and has a quicker query execution, it can result in data redundancy and scalability limitations, which the snowflake schema addresses through its normalization of dimension tables.
Whether you choose star schema or snowflake schema, you can significantly simplify your data warehouse development journey with automation. Astera Data Warehouse Builder automates every aspect of building a data warehouse. From schema design to data integration and beyond, Astera DW Builder enables you to build and deploy a fully functional data warehouse for your organization—all without writing a single line of code.
Experience hassle-free data warehouse development with Astera. Start your free trial today and see how it smooths out the process.
Explore how Astera Data Warehouse Builder transforms data integration, enabling businesses to leverage the power of their data without needing technical expertise. Simplify complex data integration with a user-friendly, no-code approach.




