
 March 27th, 2025
March 27th, 2025 

The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

Build an Agile Data Warehouse with an Iterative Approach
If you have had a discussion with a data engineer or architect on building an agile data warehouse design or maintaining a data warehouse architecture, you’d probably hear them say that it is a continuous process and doesn’t really have a definite end. And that, in essence, is pretty much the truth.
A successful data warehouse design generally uses an agile approach, iterative development methods that ensure delivering quality insights to end-users based on current business data.
Fortunately, cloud data warehouse providers, like Microsoft Azure and Amazon Redshift, offer rapid flexibility and scalability options that make adopting this approach relatively easier than the rigid traditional frameworks. And consequently, having a constantly evolving architecture means you will have access to accurate, up-to-date data to fuel your analytics, allowing teams and departments to meet their respective goals.
As Geoffrey Moore rightly said:
“Without big data analytics, companies are blind and deaf, wandering out onto the web like deer on a freeway.”
So, how can you build your own agile data warehouse design, how does this iterative data warehousing solution work, and what results can a data warehouse team of engineers and business analysts expect from it?
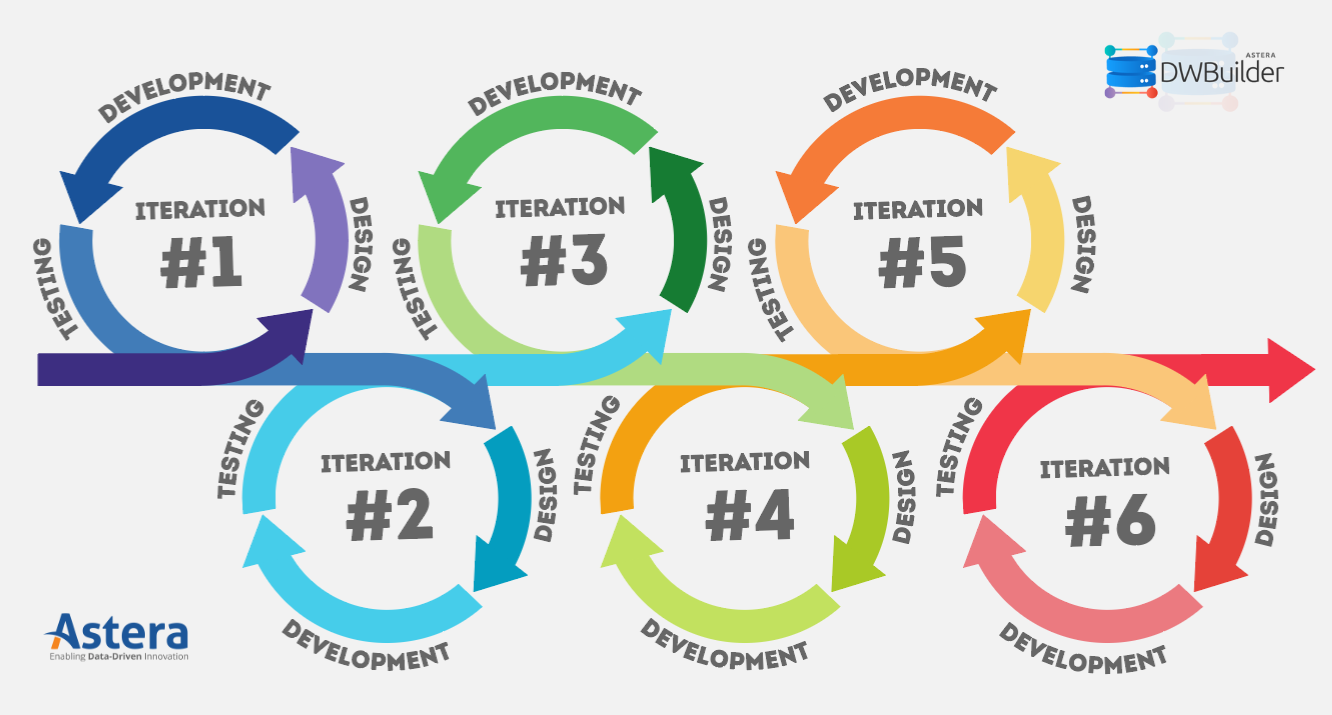
Steps to Build a Data Warehouse
Creating a More Adaptable, Responsive Data Warehouse Infrastructure
In an iterative development model, the data warehouse is in a constant state of improvement and evolution. Instead of creating an architecture that answers all the queries on day one, your team focuses on the information that matters to your business users the most. You need to prioritize what’s important, put them into small manageable segments, and then take several rounds to modify your data warehouse architecture based on your business requirements.
This agile methodology, with its iterative cycles and adaptability, is key. For a deeper understanding of this approach, delve into what is Agile methodology and its core principles.
To achieve this, data teams work in multiple sprints and cycles, making changes to the ETL flows, dimensional models, and other data processes after taking feedback from business analysts and other stakeholders. After every cycle, continuous feedback ensures that these implementations provide a true picture of business performance and effectively address pain points and gaps.
What do you need to build an agile data warehouse?
Aside from a dedicated team of data architects and analysts, you’ll essentially need a data warehousing tool that offers a codeless development environment to facilitate rapid changes, allowing you to kick the rigidity out of the architecture.
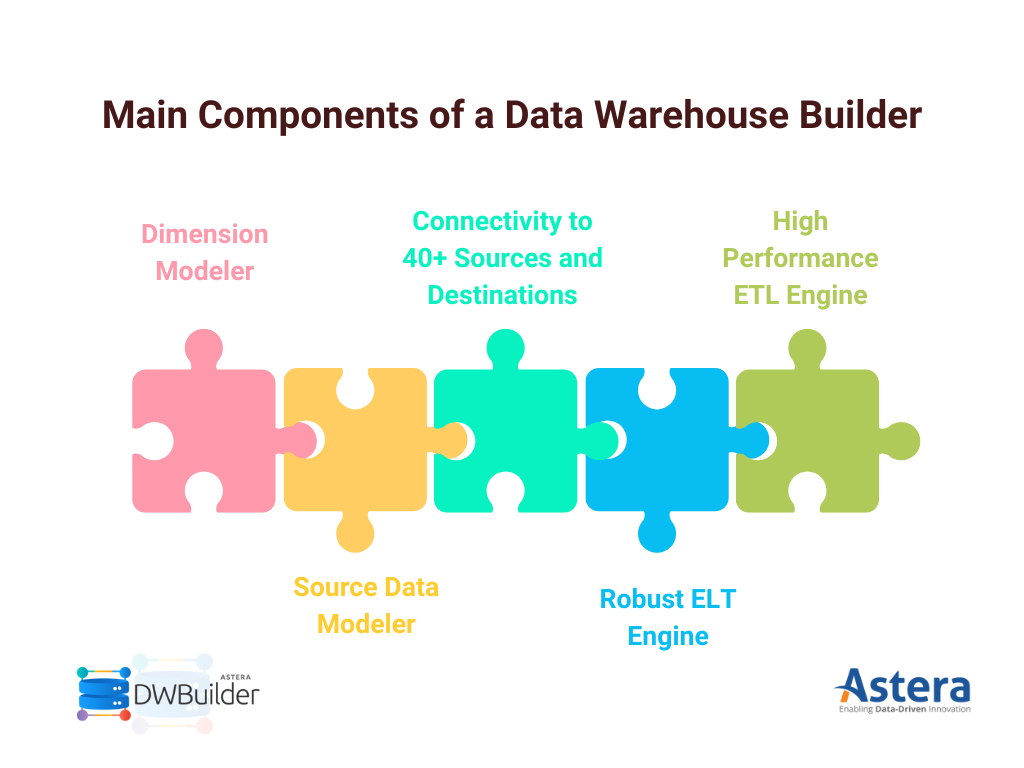
Main Components of Astera’s Data Warehouse Builder
With that said, almost any organization can deploy an agile data warehousing solution, provided that it has the right technology stack fueling the initiative. In essence, a data warehousing tool should provide:
- Source data modeling capabilities that can easily map and build relationships among your data sources
- Dimensional modeling functionality that can help determine facts and dimensions based on the source data and generate the schema and tables that would fit into your destination warehouse
- A high-performance ETL engine to simplify and accelerate data aggregation and offer an array of transformation options, like normalization, denormalization, merge, join, and more
- The option to switch to ELT or pushdown mode to reduce time to transform and access business data quickly
- Data quality modules to ensure each byte of data meets the quality standards of your organization
- A wide range of web applications, databases, and cloud connectors to connect and bring your business data to your data warehouse
- Slowly Changing Dimensions (Types 1-6) to control how different data fields are populated in database tables
- Support for OData service to provide secure ways to end-users to access data for reporting and analyses
This is not an exhaustive list but just an overview of the major features and functionalities required. Now, you may find many solution providers that patch together several tools and build a customized package to close the functionality gaps. However, the recommended way is to opt for a unified platform that checks all these boxes to meet your data warehousing needs.
Okay, Sounds Great. But Why Should I Consider This Approach?
Well, here is why:
The main purpose of any agile data warehouse design implementation is to provide answers backed by trustable data based on the current business scenario.
But the problem is that growing companies acquire new data sources and make changes to the information flow within apps and databases to match the pace of their increasing business needs. All these new sources and structural updates naturally have to be factored in the existing data models and reflected in the centralized repository to supply accurate, trusted data to end-users.
As such, the iterative approach follows the agile methodology that allows you to design, develop, and deploy the most flexible, result-oriented architecture to build your enterprise data warehouse. You can easily include new data streams without having to revisit or rewrite ETL scripts, and that too in a matter of a few hours, if not minutes. That’s largely because modern data warehousing tools provide a code-free development environment and end-to-end process automation, allowing you to make quick changes to your flows and build better ETL processes.
Not only that, you can enjoy the benefits in various scenarios as well. Whether it is planning and strategizing the data warehousing process, deploying prototypes to test its feasibility, or performing ETL testing to ensure consistent results, this agile methodology facilitates the development process at every stage.
Perhaps, the real value of this approach is seen in the business benefits organizations can yield with its implementation. These include but not limited to:
- Faster results to meet end-user Data Warehouse business intelligence (DW BI) & analytics requirements
- Better alignment with the evolving business needs
- Ability to speed up prototyping and feasibility analysis
- Lower TCO due to streamlined development processes
- Higher quality, up-to-date insights into robust decision making
- Reduced project complexity due to smaller, more manageable cycles
- The ability to identify shortcomings faster, leading to better risk management
- Greater transparency into the progress, performance, and challenges in each iteration
A Solution that Fits the Bill
“The traditional architecture is much too slow. We no longer have the luxury of two to three months. We need to be able to tell users, ‘We can have that for you — in two to three days.'” – Rick van der Lans
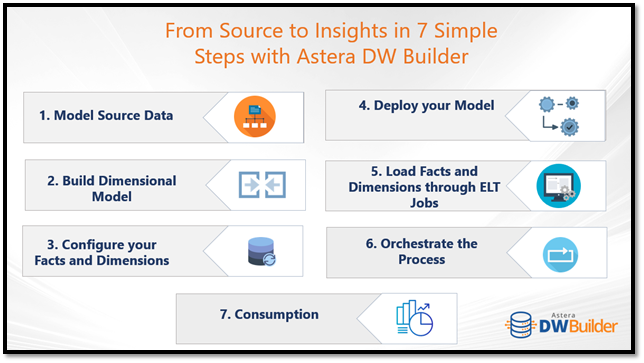
From source to insights – 7 steps
And this is where modern data warehousing solutions, like Astera DW Builder, come in that are known to cut down development time significantly through end-to-end automation. It provides a unified data warehousing framework that enables a business to go from gathering requirements all the way to analytics via direct integration with data visualization software.
Interested in creating your own data warehouse based on an agile, iterative development method? Take the first step and get a personalized live demo of Astera DW Builder.
Authors:
Junaid Baig



