
 March 27th, 2025
March 27th, 2025 

The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

The Change Data Capture (CDC) Guide for PostgreSQL
This article serves as a comprehensive guide to change data capture (CDC) in PostgreSQL, also known as Postgres. It will take you through the different ways of implementing Postgres CDC, including the pros and cons, as well as an automated alternative to all the manual methods.
It will also touch upon the importance of PostgreSQL CDC. Before we start, let’s get some basics out of the way.
What is PostgreSQL?
PostgreSQL is an open-source relational database management system (RDBMS). Its versatility allows for its usage both as a database and as a data warehouse when needed.
PostgreSQL is also completely free, and its users consistently enjoy extensive open-source development and reliable support. These are some of the major reasons for its impressive longevity—PostgreSQL has been around for over two decades and continues to rank among the most widely used relational databases for data management today.
Features and Applications of PostgreSQL
- Besides being free, PostgreSQL has also earned a great reputation for its adaptability and extensibility. It integrates seamlessly with your existing systems and adheres to SQL standards, so you know what to expect.
- With built-in support for change data capture, Postgres provides a robust mechanism for tracking and capturing changes to the database.
- It is ACID-compliant, highly secure, and capably handles processing faults, so you can count on data validity.
- It supports both JSON and SQL queries.
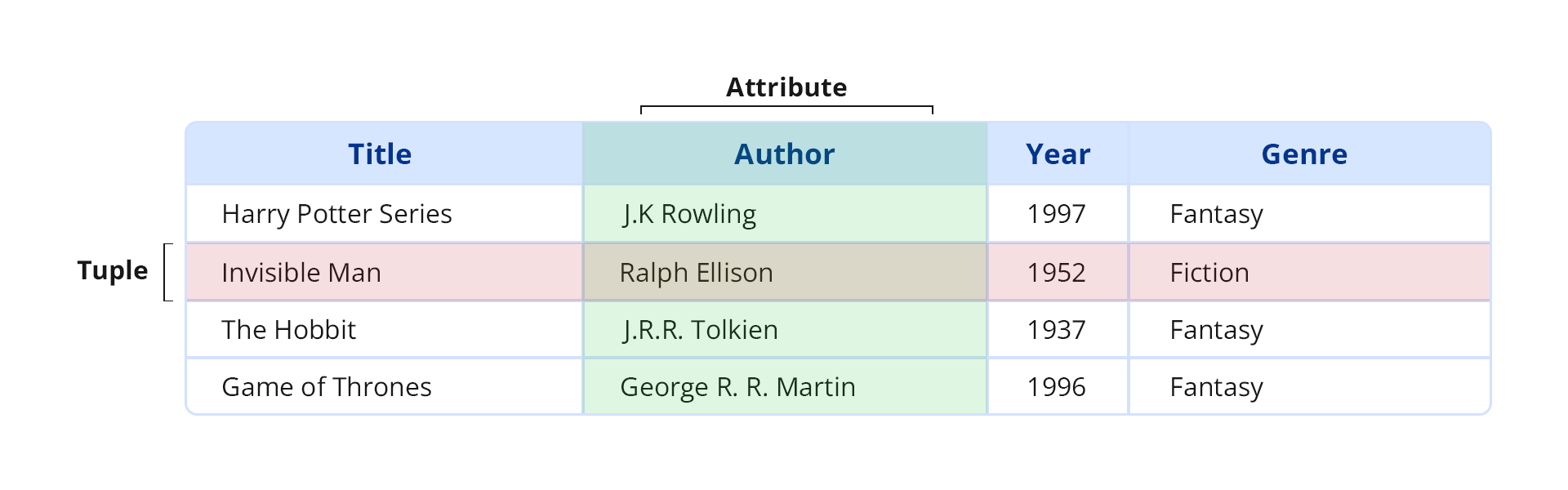
- As a relational database, PostgreSQL stores data elements in the form of tables where the rows are also called tuples, and each tuple is identified with a unique key. The columns store the attributes for each corresponding data element.
These features make PostgreSQL the right choice for many applications, a few of which include:
- Transactional Database: When you frequently need quick access to information to use in a product or an application, PostgreSQL is the right choice of database since its relational structure fetches relevant data at high speeds.
- Data Warehousing: A database works well for transactional data operations but not for analysis, and the opposite is true for a data warehouse. The two complement each other so you can leverage your data more easily. PostgreSQL’s compatibility with Business Intelligence tools makes it a practical option for fulfilling your data mining, analytics, and BI requirements.
- Location-Based Services: Using the PostGIS extension, you can use PostgreSQL to store, index, and query geospatial data as needed. This makes it a smart choice for location-based services and Geographic Information Systems (GIS).
- OLTP Transactions: PostgreSQL is commonly used for Online Transaction Processing (OLTP) transactions in many industries, including e-commerce (online purchases and stock updates), banking (funds transfers, ATM withdrawals, and balance checks), sales (retail transactions, invoice generation, and loyalty points), and services (booking appointments, service updates, and payments for services rendered).
Why Do You Need Postgres CDC?
Let’s say you require the most up-to-date data for reporting purposes right now, except you cannot have it yet since the next sync is scheduled for hours from now. Manual sync is one option, but if yours is a massive enterprise dealing with vast volumes of data, batch processing can quickly become a hurdle. It can lead to mistakes, the use of outdated information, and incorrect reporting.
Ultimately, your decision-making will be affected as you won’t have the updated data you need to take the steps you should.
This is exactly the kind of scenario that you can avoid with Postgres CDC.
Postgres CDC methods help you track and handle changes in your databases. The most common action in such cases is the replication of changes in the source to a destination data store. This lets you keep your data synchronized between multiple databases.

How Does PostgreSQL CDC Work and What Does It Do?
Postgres CDC ensures that all systems have consistent access to the most updated version of your data, so you are always working with up-to-date information. Postgres change data capture also has some additional benefits, such as:
- Postgres CDC can help you lower your network usage costs since only the latest changes will be processed during each sync instead of the entire dataset.
- Analytics and similar tasks require more resources to execute, so frequent batch processing impacts the Postgres database’s performance over time and disrupts its functionality. Postgres CDC initially makes copies of the database and then incrementally updates them with changed data. This process is much lighter than batch processing, keeping your database faster and more efficient.
- Your Master Data Management (MDM) System will operate more smoothly with Postgres CDC in effect. With changed data from disparate sources continually updated in the MDM system, all your teams will use the same updated data. This can improve collaboration and coordination and speed up better business decisions.
- You can even use change data capture with Postgres as a disaster recovery mechanism for your data. Real-time CDC helps you back up critical databases and create redundancies that can be useful in instances of system failure, malware attacks, human errors, and other similar situations.
Methods to Implement PostgreSQL Change Data Capture

As discussed above, Postgres CDC will track and replicate any data changes across multiple databases. Your CDC method of choice can be either batch or real-time since CDC does not have any time-related requirements.
You can implement Postgres CDC in a few distinct ways based on your operational requirements, and we will take a closer look at them below:
Triggers
Trigger-based Postgres CDC is also known as “event sourcing.” In this method, a dedicated event log is created to serve as the primary source of information. As its name suggests, this method relies heavily on triggers, which are crucial in each database transaction and capture events in real-time.
A trigger programs the database to behave in a particular way whenever a specified event occurs. This event could be the introduction of new data, updates to existing data, or the removal of existing data from the database.
Postgres CDC triggers are highly customizable. You can configure them to run before or after the events mentioned above, to run for every individual change, or to run once for a group of changes. You can even impose operating conditions on triggers—having them run only when a specific tuple is modified or run only as a response to certain actions.
Triggers in Postgres CDC work well for tracking changes in tables, recording them in a different table, and creating a log of every change. To implement trigger-based Postgres change data capture, you can make audit triggers on your Postgres database that will track all events related to actions like INSERT, UPDATE, and DELETE.
Since this method operates at the SQL level, you can refer to the Change Data Capture table and identify all changes. Here is an example of a trigger function:
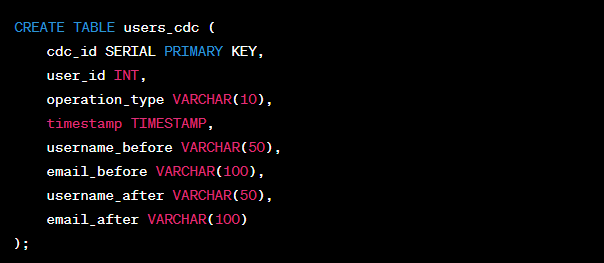
This code will create a table named ‘users_cdc’ for storing change data capture information, capturing information such as the user ID, operation type (INSERT, UPDATE, DELETE), timestamp of the change, and the user’s pre- and post-change information.
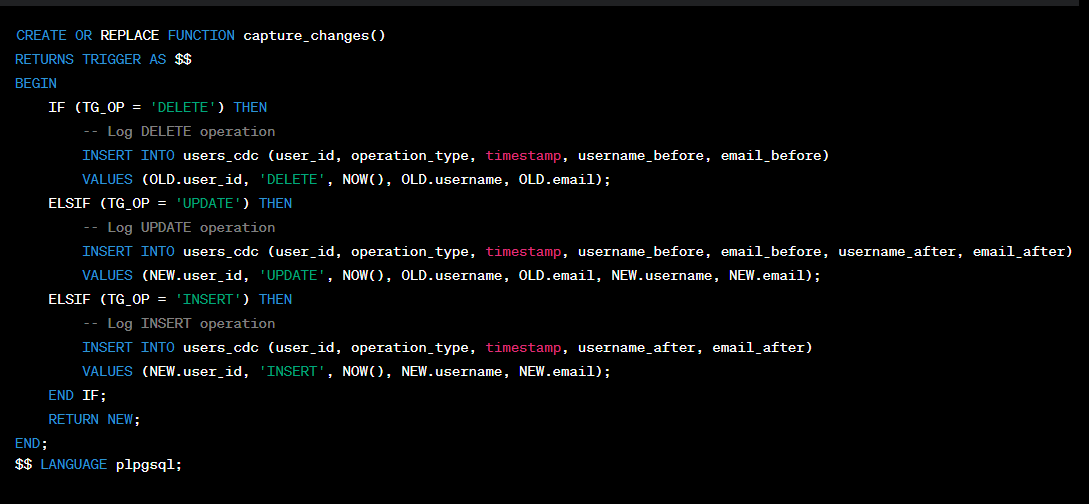
This code defines a PL/pgSQL function (‘capture_changes’) triggered after INSERT, UPDATE, OR DELETE operations on the ‘users’ table. The ‘CASE’ statement determines the operation type based on the value of ‘TG_OP’ (trigger operation).
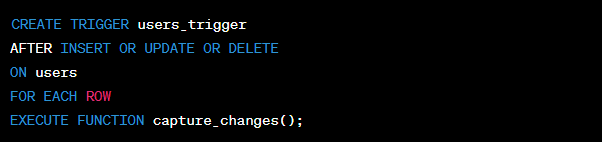
This code creates a trigger named ‘users_trigger’ on the ‘users’ table that will fire following any INSERT, UPDATE, or DELETE operations.
In the above Postgres CDC example, any time a change occurs in the ‘users’ table, the corresponding trigger will activate the ‘capture_changes’ function, which will log the changes to the ‘users_CDC’ table. The CDC table will capture the operation type, timestamp, and relevant data before and after the change.
Together, these elements will help you track all modifications in the original table over time.
Pros of Trigger-Based Postgres CDC
- Trigger-based Postgres CDC is reliable and comprehensive.
- All change captures and record-keeping occur within the SQL system.
- Instantaneous change capture enables the real-time processing of events.
- You can create triggers for diverse types of events.
Cons of Trigger-Based Postgres CDC:
- Since any triggers you create run on your primary Postgres database, they can slow the database down. Like any other operation, executing Postgres CDC via triggers also requires resources and increases the pressure on the database.
- Minimizing the impact on the database resources involves creating another table mirroring the primary table and using this secondary table for trigger implementation. However, you will also need to make a separate pipeline to mirror any changes in any destination that lies outside of the trigger’s applicable Postgres instance.
Queries
Queries-based Postgres CDC requires more manual effort than using triggers. You must actively query your Postgres database to identify any changes instead of relying on pre-configured triggers. You need a timestamp column in your table to use this custom method. Whenever a record is added or modified, the timestamp column will be updated to include the date and time of the change.
Any query you make to your Postgres database will use this timestamp column to obtain all modified records since your last query and then display those captured changes.
You can also use scripts to monitor your Postgres database for changes and record them in a destination database, but this option is even more labor-intensive than simply querying the database.
Continuing the Postgres change data capture example above, here is how you will query a ‘users’ table:
![]()
This query fetches all records from the ‘users‘ table where the ‘last_updated‘ timestamp is greater than ‘2024-01-01’. It is used to retrieve user records that have been updated since the specified date.
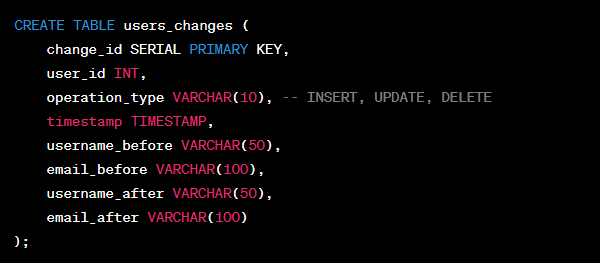
This code will create the table ‘users_changes‘ with information on each change—such as the type of operation (INSERT, UPDATE, or DELETE), its timestamp, and relevant data before and after the change.
Pros of Queries-Based Postgres CDC
- It’s easier than setting up Postgres change data capture via triggers.
- It gives you more control over the CDC process.
- You don’t need any external tools for query-based CDC.
Cons of Queries-Based Postgres CDC
- Requires a more proactive approach than the set-it-and-forget-it trigger-based Postgres CDC. You will need to regularly query the database to ensure accurate and on-time change tracking.
- The query layer is crucial for data extraction in this method, which can put an additional load on the Postgres database.
PostgreSQL Logical Replication
Postgres CDC with logical replication is also called Logical Decoding. Think of it as a streaming representation of a Write-Ahead Log (WAL). Since WAL captures and records all data changes in the Postgres database, these changes are considered logical decoding streams and are categorized as a logical replication slot at the database level.
In other words, a replication slot is nothing more than a stream of changes occurring in a database. Each database can have multiple slots or streams of changes.
Implementing PostgreSQL logical replication requires a logical decoding plugin. Postgres versions 10 and later feature the default ‘pgoutput’ plugin. It allows Postgres database changes to be processed as streams. However, if you are using a version older than 10, you will need to manually install a plugin such as ‘decoderbufs‘ or ‘wal2json‘.
The ‘pgoutput‘ plugin is useful for replicating data between two or more PostgreSQL instances. Still, it can be difficult to transfer Postgres change stream data into another platform or database.
If you want to move change stream data to a non-Postgres platform, you can use the ‘wal2json‘ plugin to transform the change stream data into JSON. This will allow your destination platforms to read it in JSON format—which is easier than reading pgoutput’s binary output.
Besides a plugin, the other vital component in CDC via PostgreSQL logical replication is a subscription model with publishers and subscribers. This subscription model allows one or more subscribers to subscribe to one (or more than one) publications using the publisher node. Subscribers pull data from the publications, and they can republish it for replication or further reconfigurations.
Follow the steps below to implement Postgres CDC with logical replication from a source database (we will use the ‘users’ table from the previous examples) to a destination database, which we will call the ‘users_changes’ table.
Remember to replace placeholders such as ‘source_db’ and ‘replication_user’ with your actual database information.

First, enable logical representation in the Postgres configuration file ‘postgresql.conf‘. Use the above settings and restart Postgres once these changes are made.
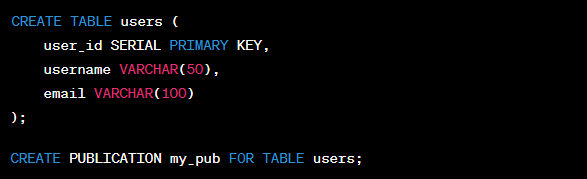
This section will create a table named ‘users’ and a publication named ‘my_pub‘ for the ‘users‘ table. This publication is the source of the changes to be replicated.
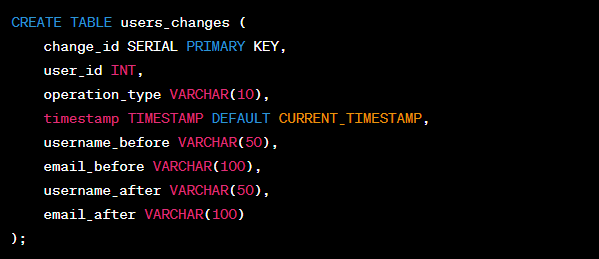
This section will make a table named ‘users_changes‘ in the destination database to store the changes from the source.

This code will establish the subscription ‘my_sub‘, which will connect to the source database and subscribe to the ‘my_sub‘ publication.
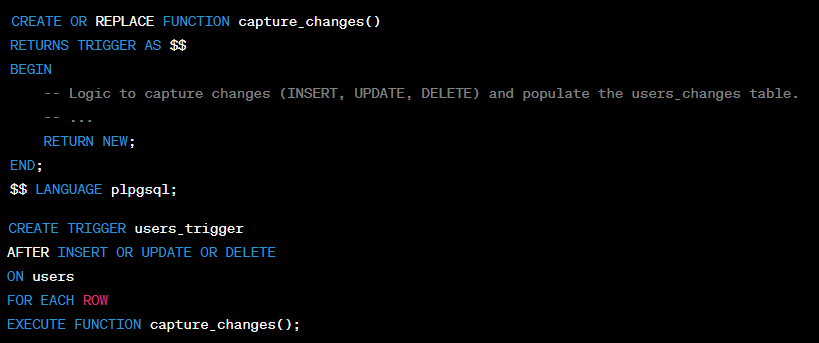
This code defines a trigger function ‘capture_changes‘ to capture changes in the ‘users’ table. It inserts relevant information into the ‘users_changes‘ table depending on the operation type (INSERT, UPDATE, DELETE). It also creates the trigger ‘users_trigger‘ to execute this function after each row-level change in the ‘users’ table.
![]()
This is an SQL statement for monitoring changes in the logical replication slot named ‘my_sub‘ and fetching them. Replace ‘my_sub‘ with your specific subscription name.
Pros of Postgres CDC with Logical Replication:
- Log-based CDC allows real-time data change capture using an event-driven mechanism. This enables downstream applications to access updated data from a Postgres database consistently.
- This CDC method can identify all kinds of change events in a Postgres database.
- Since this method accesses the file system directly, it puts less strain on the database.
Cons of Postgres CDC with Logical Replication:
- Logical replication is not available for PostgreSQL versions older than 9.4.
- Depending on the use case, the complex logic required to process these events and their eventual conversion into statements for the target database can potentially affect project completion.
Postgres CDC Using the Write-Ahead Log (WAL)
Both triggers-based and queries-based Postgres CDC can create latency and affect your database’s performance over time. If, you’d rather leverage Postgres’ built-in features and repurpose them for CDC processes instead of using the techniques discussed above, you can use the WAL.
The WAL is a transaction log that notes all changes in the database. Its primary purpose is recovery and ensuring data integrity, making it useful for event-based CDC. Since this is a built-in feature, you will mainly be working with the Postgres database’s own settings to set it up for CDC.
Below are the steps you need to take to implement Postgres change data capture using transaction log:
First, enable WAL in your Postgres configuration. While this is typically the default setting, check the ‘postgresql.conf’ file to confirm. Postgres allows users to examine the WAL’s contents. As an example, we will use the ‘pg_waldump’ tool. Replace the placeholder ‘<path_to_wal_file>’ with the actual path of your WAL file when you use this code.
![]()
Next, query the WAL contents using SQL queries. The ‘pglogical’ extension package includes the ‘pg_decode’ extension, which is the most frequently used extension for this purpose.

- ‘CREATE EXTENSION’ will create and install the ‘pglogical’ extension which provides logical replication capabilities for Postgres.
- The ‘SELECT’ SQL statement creates a logical replication slot named ‘my_slot‘ using the ‘pg_create_logical_representation_slot‘ function.
- ‘pgoutput‘ specifies the output plugin to use for decoding changes and here it’s a built-in output plugin for logical replication.
- ‘pg_logical_slot_peek_changes’ is used to examine the changes captured in a logical replication slot
- ‘my_slot‘ is the logical replication slot being queried. This name is a placeholder and you should replace it with the name of the actual slot you want to query
- ‘NULL, NULL‘ is where you can place parameters specifying the range of changes to retrieve. Using ‘NULL, NULL‘ here means retrieving all available changes without any specific range.
Note that you may need to do some coding, particularly if you are planning to automate change extraction and handling.
Pros of Using WAL for Postgres CDC
- While some coding is still involved in using the WAL, overall it requires less coding than the other Postgres CDC methods we have discussed.
- Third-party solutions and platforms such as ‘pglogical’ are available to simplify the more complex steps in the process.
Cons of Using WAL for Postgres CDC
- The data you extract from the WAL may be in a raw format. Transforming it to align with your application’s data structure requires additional work.
- Monitoring changes in the WAL could require further scripting or automation.
- Comprehension and interpretation of the WAL records require an in-depth understanding of your Postgres database’s internal workings.
Automating Postgres CDC with Astera
The following example explains how you can automate trigger–based Postgres CDC using Astera. Let’s assume you’re working with a PostgreSQL database and have configured a Database Table Source to read information from this database.
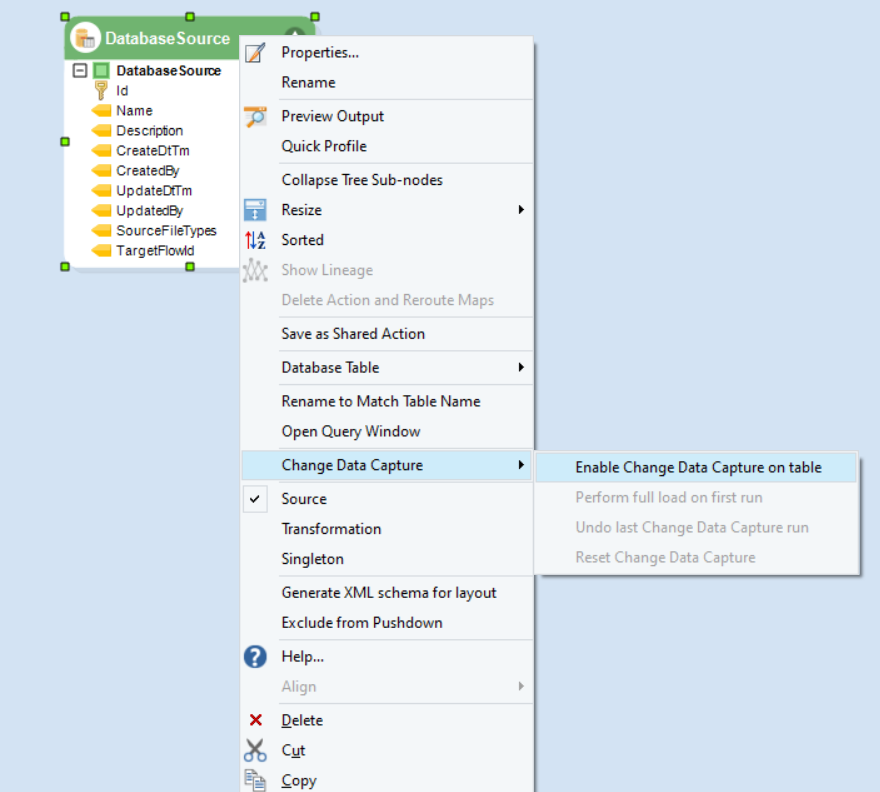
First, you’ll enable CDC on this database by selecting Enable Change Data Capture on table.
Then, select which fields you want to enable the CDC on, through the Select Columns dialog box.
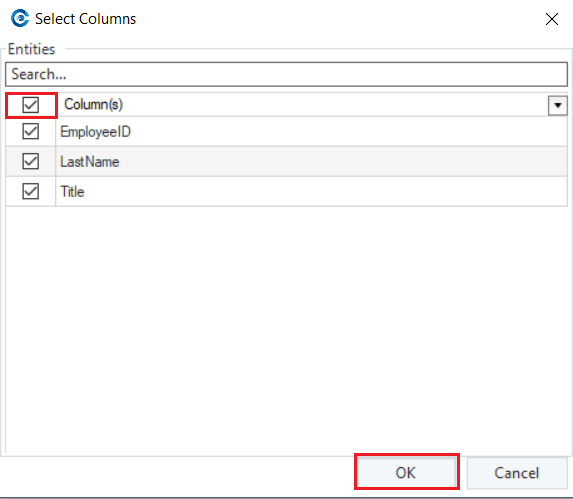
While you can select one or all the fields in a database, it’s mandatory to choose a primary key. In this case, you can choose EmployeeID.
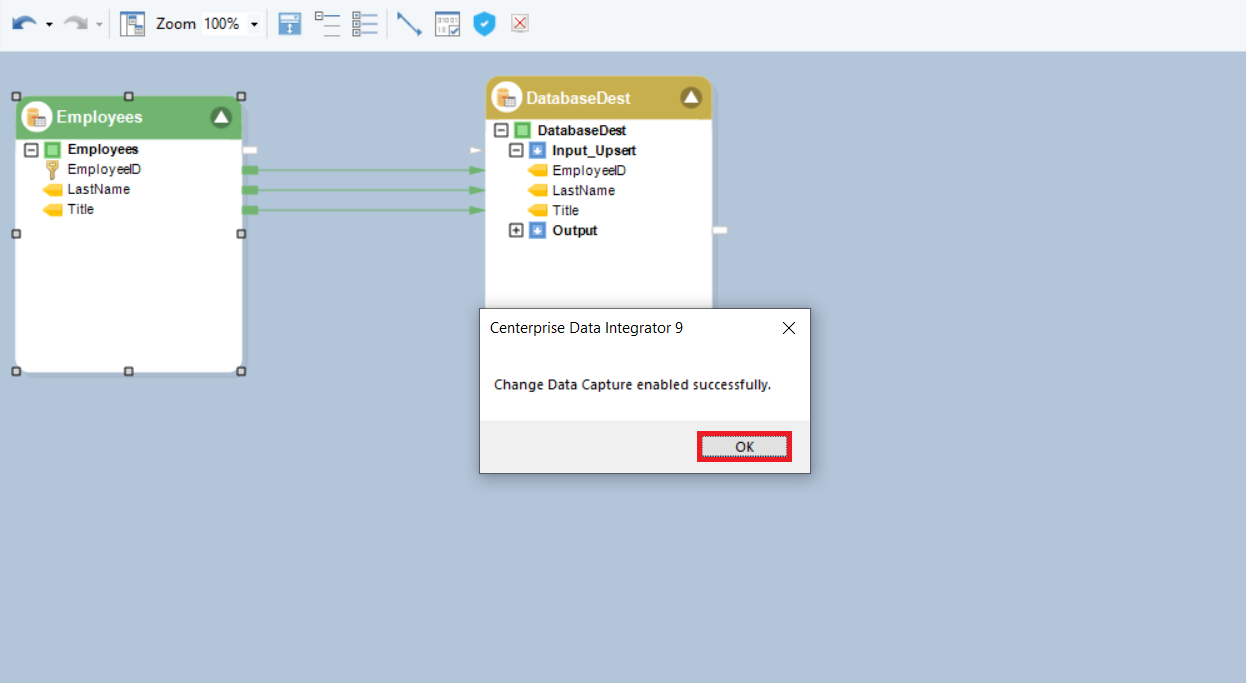
Once you’ve chosen the fields, click ‘OK’. You’ll see the dialog box indicating that you have successfully enabled CDC on this database.
Next, set up the destination table for storing the updated data from the source table. Add a database destination object from the Toolbox to your left.
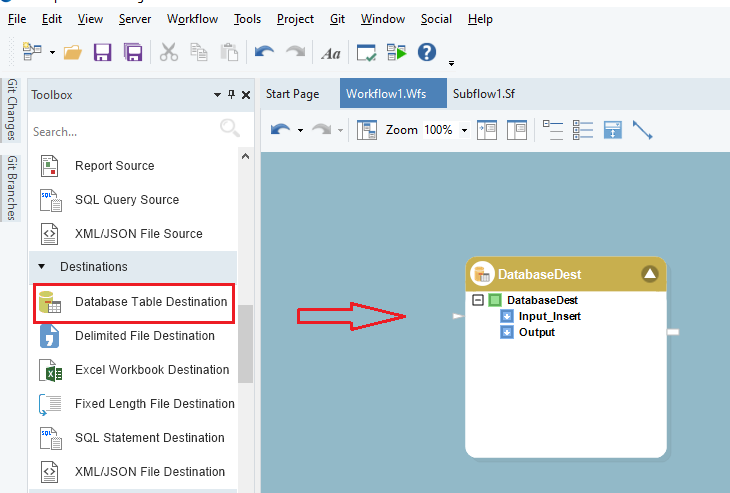
Configure the destination object by opening its properties. In the Define Input Ports for Mapping section, select the Upsert checkbox with a CDC source as the incoming data will likely contain both new and updated records. In Select Fields for Matching Database Record, choose EmployeeID since it’s the primary key and unique for each record in the source database.
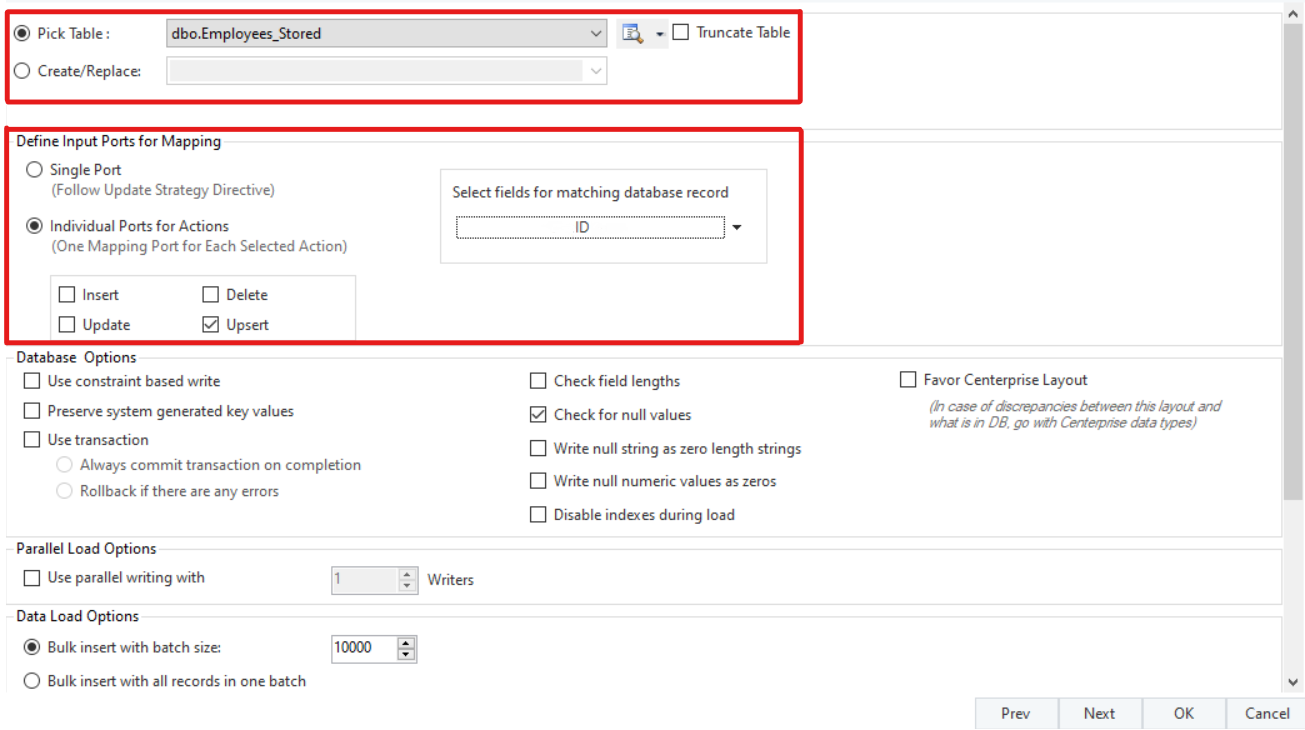
Next, use drag-and-drop to map all the fields from the database source object to the destination object. The dataflow to implement Postgres CDC is now complete.
When you run the dataflow and check the job progress window, you’ll find that Astera has read and written the entries from the source table to the destination table.

Incremental Postgres CDC
It’s easy to set up Incremental CDC in a PostgreSQL database using Astera, enabling you to load the data from your database table incrementally instead of complete loads with every run.
Let’s assume that we’re working with shipping companies’ data in this use case and want to store this data in a new database table. We want to be able to update the new table any time there’s a change in the source, without having to load the source table completely.
We’ll use a pre-configured database table source with the pertinent information.
Access the properties of the source object by right-clicking its header and selecting Properties.
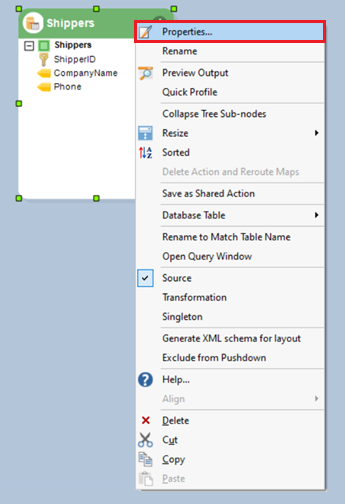
Connect with the database and click ‘Next’ to proceed.
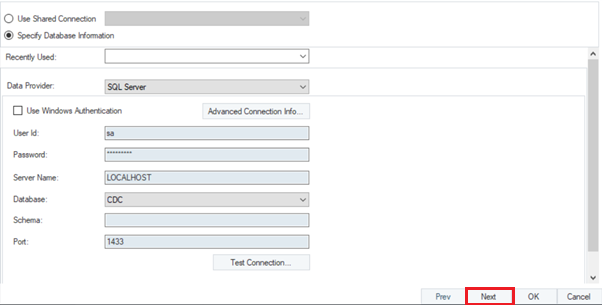
On the next screen you’ll see the Incremental Read Options section.
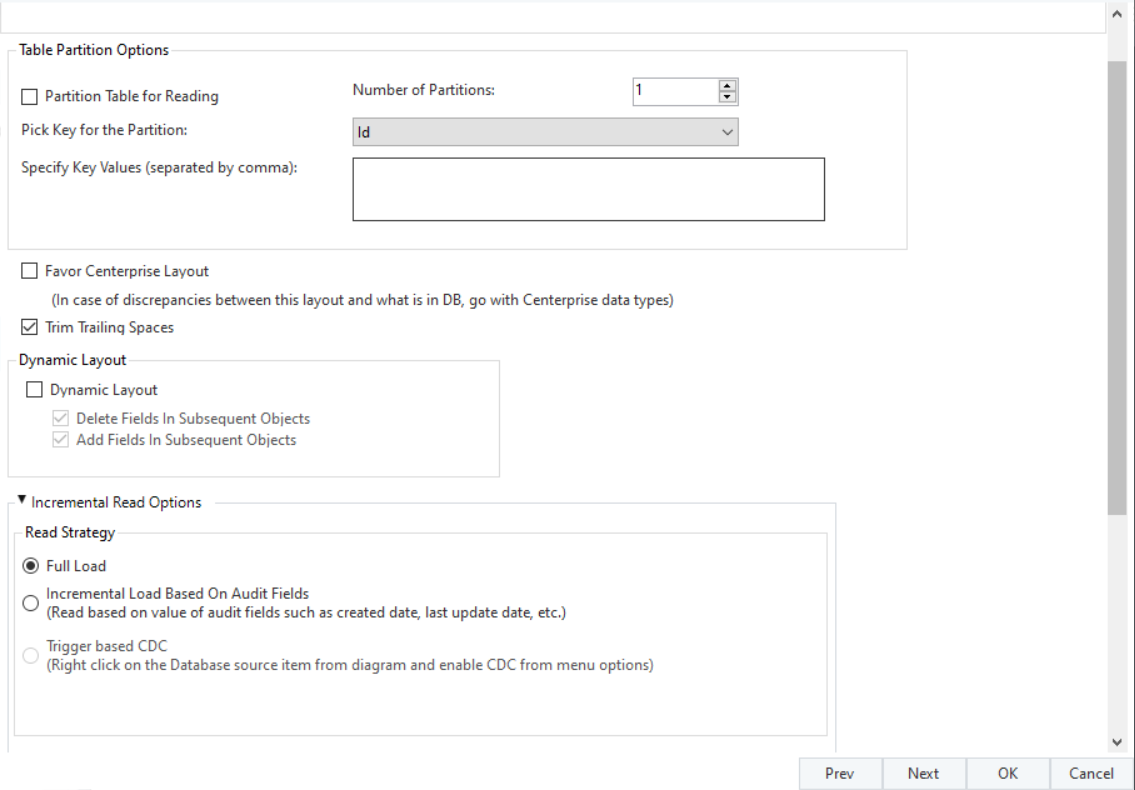
Choose Incremental Load Based on Audit Fields as the Read Strategy which will display further options.
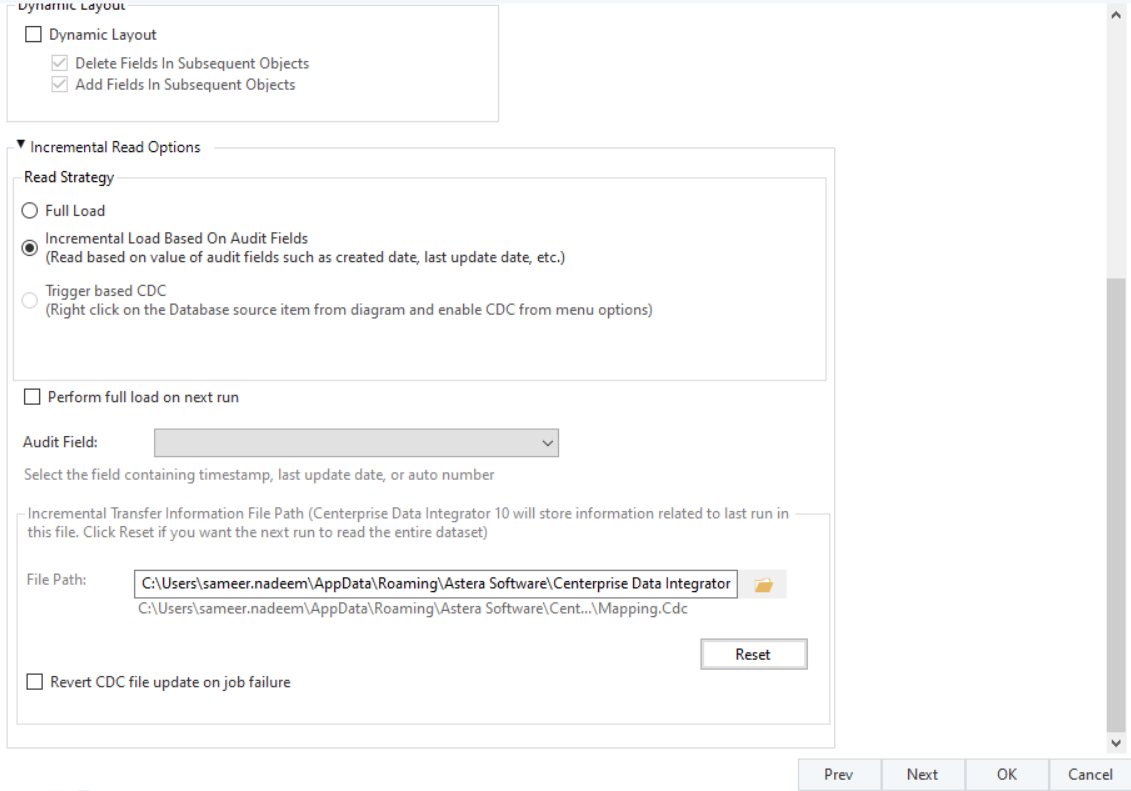
Audit Fields are updated when a record is created or modified, such as created date and time, modified date and time, and auto number. Incremental read tracks the highest value for any audit fields that you specify. During the next run, only records that have a higher value than the saved value are retrieved.
- Add a file path for the Incremental Transfer Information File, which Astera creates to store information on the database table’s last entry. It will compare this file with the database table on each run to check for new entries.
- Set up a destination table by dragging and dropping Database Table Destination from the Toolbox.
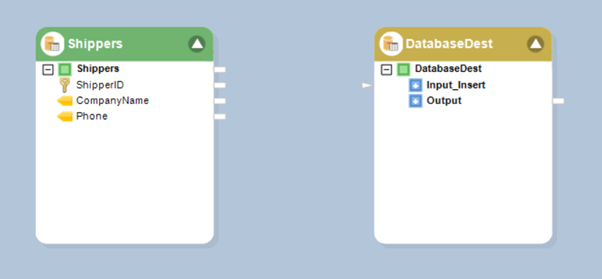
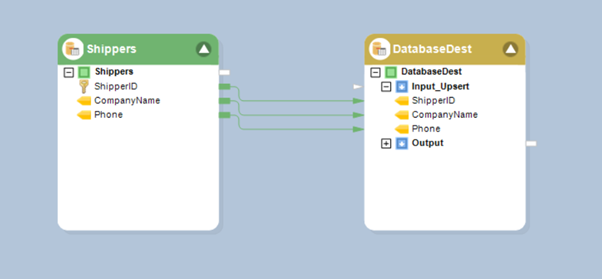
- Once configured, map the table source to the table destination object.
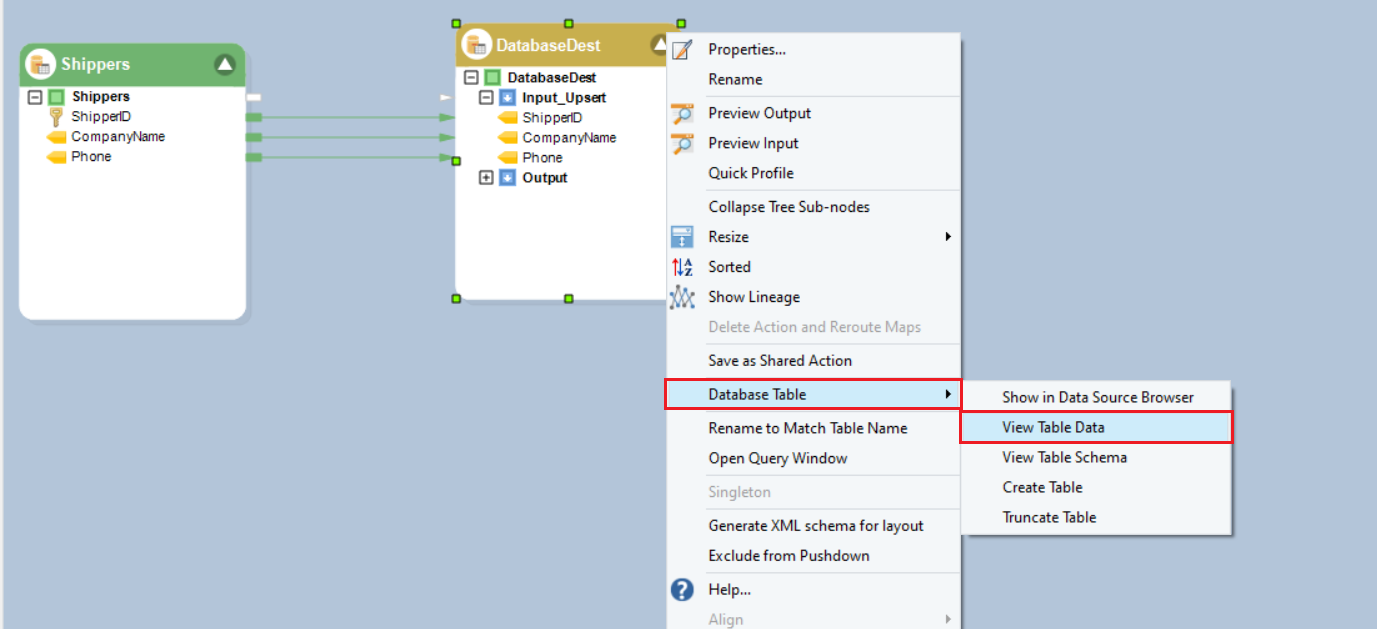
- You’ll see that the destination table is empty. You can check its contents as shown below, and this will open an SQL query for viewing the table data.
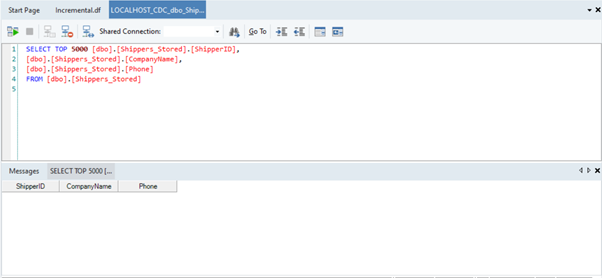
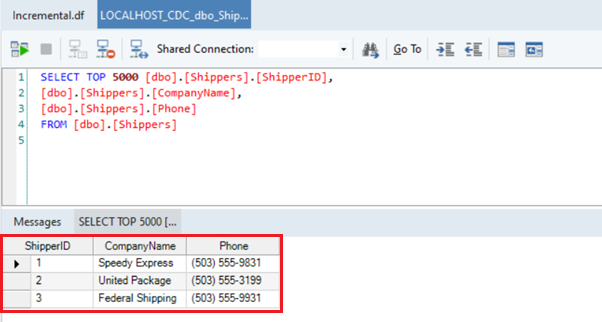
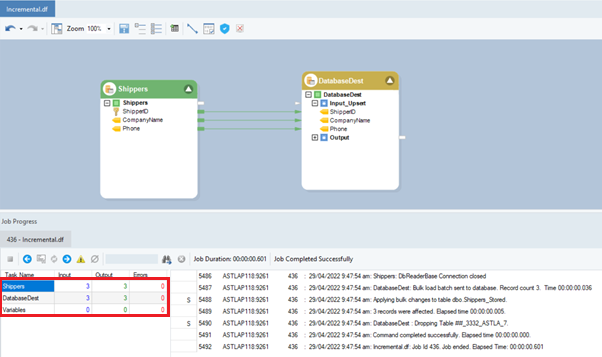
- When you execute the dataflow, check the Job Progress window and you will see that the entries from the source table have been written to the destination table.
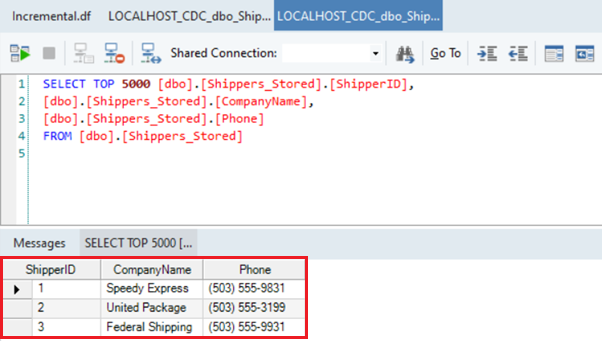
- You can check this by previewing the destination table.
Automate Postgres CDC in Astera and Keep Your Databases Synchronized Effortlessly
Combine Postgres CDC techniques with Astera's impressive data management features and make the most of your always up-to-date databases. Discover the Astera difference today!
Start Your FREE Trial
Choosing The Right PostgreSQL CDC Method for Your Use Case
There are multiple methods for implementing CDC in a PostgreSQL database, and you need to consider several factors when deciding which method to choose. Each method has its pros and cons, which we have briefly outlined above. Additionally, here are some more points to think about:
Data Volume and Change Frequency:
- In environments with moderate data changes requiring real-time tracking, trigger-based CDC is your best bet
- Logical replication is suitable for scenarios with high data change rates as it provides real-time replication capabilities.
- If there is infrequent extraction of data changes in your workflows, choose queries-based Postgres CDC.
Performance and Overhead:
- Triggers-based Postgres CDC can add additional overhead, especially if high transaction rates are involved.
- Logical replication is low-impact and easy on the source system, making it the right choice for high-performance scenarios.
- Queries-based CDC typically does not consume too many resources, but it can affect performance when there is intensive querying.
Use Case Complexity:
- Triggers-based CDC is useful for complex cases that require customization and detailed change tracking.
- Logical replication is suitable for cases requiring simplicity and real-time replication.
- Queries-based CDC is a hassle-free option for simple use cases that don’t need complex triggers.
Integration and Compatibility:
- Triggers-based CDC can integrate seamlessly with your current applications and databases
- Logical replication is ideal for scenarios where there is a need for compatibility between different Postgres instances.
- Queries-based CDC involves custom queries. As such, it’s the right option for meeting tailored integration needs.
Simplicity and Functionality:
- Triggers-based CDC is a robust solution offering detailed change tracking, but this adds to its complexity. Good for customization-heavy environments.
- Logical replication strikes the right balance here, making it a practical choice for a variety of scenarios and ideal for catering to real-time replication requirements.
- Queries-based CDC is quite simple and flexible, but this means it can potentially need more manual intervention. It’s the right technique for occasional change extraction.
Conclusion
In this blog, we took an in-depth look at various options you can use for implementing CDC in PostgreSQL. We also discussed each method’s advantages and disadvantages and highlighted the factors you should consider before choosing a CDC method for your enterprise.
While there is no one-size-fits-all solution when it comes to change data capture, automating the process should be in your list of top priorities. Ultimately, how you implement Postgres CDC depends on your performance requirements, customization preferences, and individual use case.
At Astera, we believe in providing a simplified end-to-end data management solution. Our intuitive, drag-and-drop interface with built–in connectors and transformations does away with coding and democratizes data operations, making them equally accessible and insightful for non-technical and technical stakeholders alike.
Our suite enables you to simplify your data integration processes, build robust data warehouses, and streamline your EDI and API management, all without writing a single line of code.
Experience the Astera difference. Start your free trial today or request a quote to get started.
Authors:
Usman Hasan Khan



