
The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

ETL, As We Know It, Is Dead
It’s a new world—again.
Data today isn’t what it was five or ten years ago, because data volume is doubling every two years.
So, how could ETL still be the same? In the early ‘90s, we started storing data in warehouses, and ETL was born out of a need to extract data from these warehouses, transform it as needed, and load it to the destination.
This worked well enough for a time, and traditional ETL was able to cater to enterprise data needs efficiently. But data volume from the ‘90s or ‘00s isn’t comparable to data from today. For perspective, the amount of data created from the beginning of time until the year 2000 is now created every single minute. And that’s just the volume of data.
Add to that data velocity, variety, and veracity (the four Vs), and it becomes clear that conventional ETL needs to evolve to keep up with the data explosion. That’s where automated ETL comes in to modernize data management.
Automated ETL is here. Have a chat with us to see if your data is ready for automation.Are you ready for the future of ETL? Find out today

¡Viva la Revolución!: How the Four V′s of Data Are Changing Everything
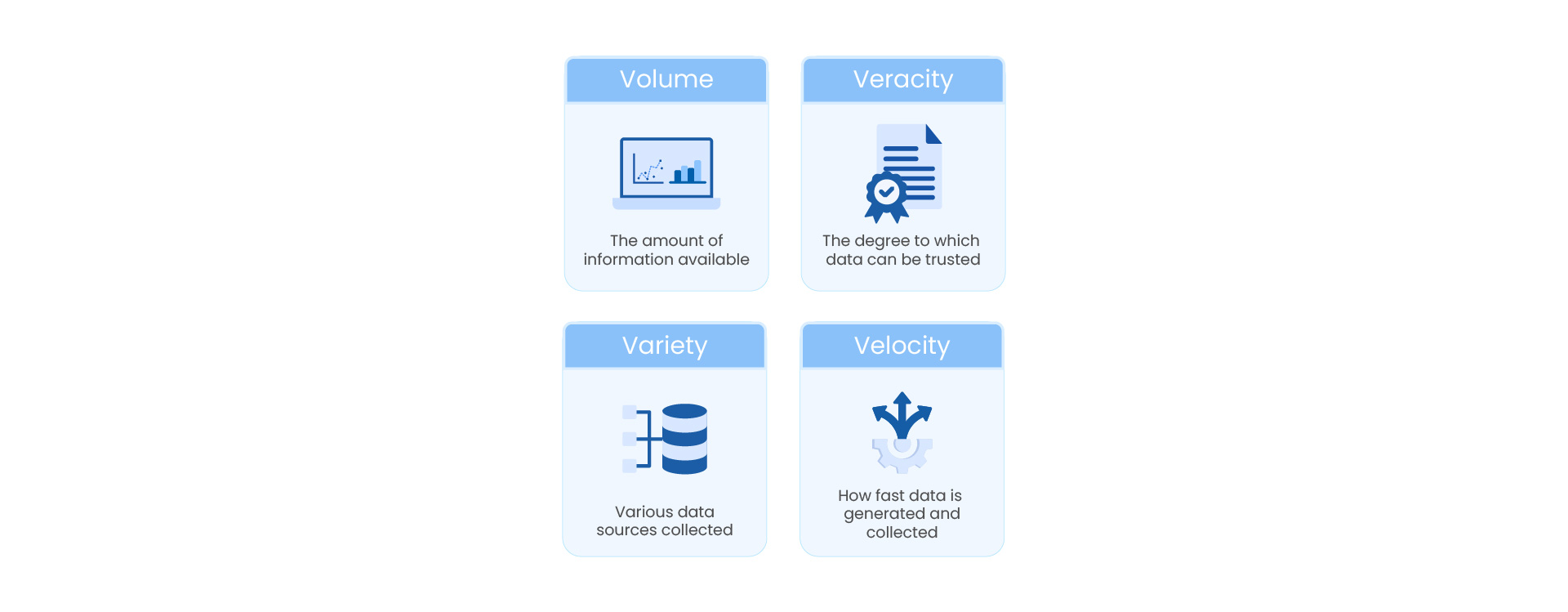
The 4 V’s of Data
For over 25 years now, data integration and ETL technology have been the foundation of business intelligence, decision-making, and data analytics. However, the change in the 4 V’s of data means ETL needs to be reimagined for a new age of data and data users.
Volume
Estimates suggest 3.5 quintillion bytes of data is created daily, and that number is always increasing. By 2030, we’ll be creating 660 zettabytes of data. That’s equivalent to 610 iPhones (128 GBs) per person!
The question “What do your cellphone, your watch, your fridge, and your doorbell have in common?” may have been a riddle a decade ago, but now it’s a straightforward question with the answer being they’re all online and constantly generating data. In other words, the Internet of Things (IoT) revolution is further contributing to data volume’s exponential growth.
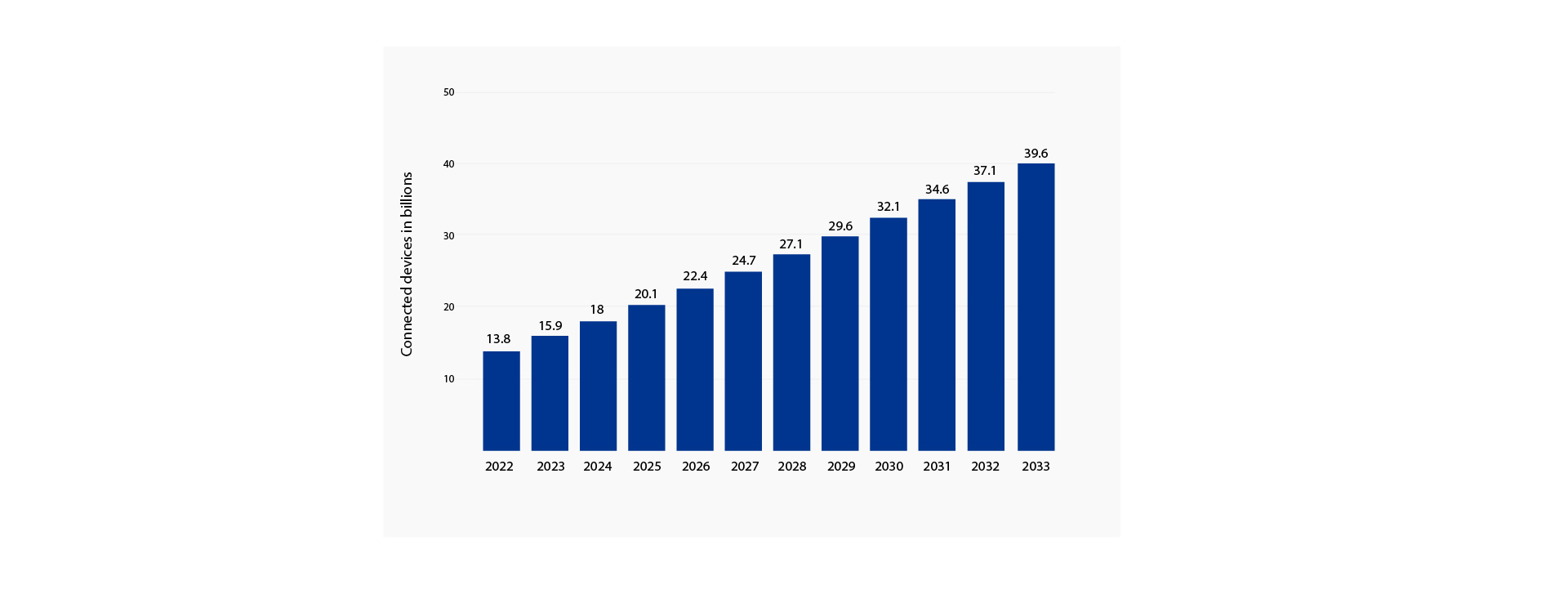
Number of Internet of Things (IoT) connections worldwide from 2022 to 2023, with forecasts from 2024 to 2033(in billions)
Source: Statista
To cope with the mushrooming growth of data volume, businesses need something more adaptable and scalable than traditional ETL.
Velocity
The increase in volume also means an increase in the speed at which data is generated and processed.
Think of when you share a TikTok, watch Netflix, or make a credit card purchase. These actions create data that require real-time data processing. Now imagine how many people across the globe are doing this and how many more will be doing it in a few years.
Data velocity will, therefore, increase at almost the same rate as volume, requiring ETL solutions that can process and update the data in real-time.
Variety
Data types are becoming more diverse as businesses now need to account for unstructured data from social media, images, videos, and sensors in addition to traditional structured data.
Plus, the variety of data will only increase in the next few years, concurrent with the increase in volume and velocity. As a result, businesses will need adaptable solutions such as reusable ETL pipelines that can handle a large variety of data sources seamlessly.
Veracity
With the increase in volume, velocity, and variety of data, ensuring veracity becomes increasingly important. Large volumes of data that move quickly and originate from disparate sources will only be valuable if it’s accurate. This requires their ETL tools to have data validation features to ensure data integrity and accuracy.
Resistance is Futile: Automated ETL is the Future
Automated ETL is the logical next step in the evolution of ETL. Data science and analytics teams need ETL solutions to generate value and insights seamlessly without spending hours setting up ETL pipelines or cleaning the data.
This means that to survive, modern ETL must go beyond the basic functionalities and power automated workflows, so users can set up ETL pipelines with just a few clicks.
Plus, it’s not just the data that is changing; the role and expectations of a data user are drastically different as well.
In other words, modern data users aren’t technical ETL programmers of the past. They are business users who want automated ETL that does all the heavy lifting so they can focus on insight-gathering, analysis, and decision-making instead of manually programming ETL pipelines. Since the target user is different, the solution should be, too.
ADP Accelerator for Automated Pipelines: The Future of ETL Is Now
Astera’s vision of empowering data professionals has been the driving force behind the different iterations of our no-code, drag-and-drop data stack.
Automation is at the heart of Astera Data Pipeline Accelerator (ADPA), which automatically generates data models, allowing you to integrate multiple databases seamlessly. This means that you work with data models and databases instead of spending hours manually tweaking individual tables.
Apart from making ETL easier and more accessible, ADPA boosts efficiency, completing large-scale ETL projects in days instead of months.
This unparalleled efficiency, combined with our solution’s scalability and adaptability, means you can future-proof your data strategy and stay ahead of the 4 V’s of data.
Seeing is believing. Get a free instant, guided tour of our new-gen solution today!
Authors:
Raza Ahmed Khan



