
 March 27th, 2025
March 27th, 2025 

The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

Model Behavior: Why Your Business Needs LLM Data Extraction
Over the last decade, data has been hailed as the new oil, the new gold, the new currency, the new soil, and even the new oxygen. All these comparisons drive home the same point: data is important. If you’re running a business today, you need data for informed decision-making and strategy development.
However, reliably extracting this data is a constant responsibility. Every day, your business needs access to data tucked away in a variety of document formats—from Word documents to PDFs to Excel spreadsheets. These formats are so popular because they offer flexibility in organizing and presenting content, but all that formatting freedom also makes it challenging to extract data from these documents.
Unless, of course, you’ve got LLM data extraction at your disposal.
Try LLM Data Extraction for Yourself
Achieve accurate, context-aware data extraction with large language models. Try Astera’s AI-driven solutions and see the results firsthand.
Contact Us Today!
Why Use LLMs for Data Extraction?
A large language model (LLM) is a machine learning model trained on vast volumes of text data. LLMs are “fed” enough quantities of human language to recognize, understand, interpret, and even generate data in the same natural language. Examples include GPT by OpenAI, BERT by Google, and RoBERTa by Facebook AI.
LLMs are most well-known for their use in generative AI but are also utilized in sentiment analysis, chatbots, and online search. Here are some of the factors that make them a practical choice for data extraction:
- LLMs Can Handle Structured and Unstructured Data
Besides Word files, PDFs, and spreadsheets, your business will likely receive data in plain text files, HTML files, and even scanned images. You’ll see this data in emails, customer feedback forms, legal documents, reports, or invoices. LLMs are trained on massive datasets with diverse language patterns, allowing these models to adapt to both structured and unstructured document types without issues. They can recognize key information and entities in documents with inconsistent formats or no fixed structure.
- Not Just Text, But Context
LLMs focus on the context of the information they’re extracting. For instance, they can distinguish between contracting parties and their duties and liabilities when extracting legal documents. LLMs can compile and cluster data based on context instead of relying on keyword matching. This grasp of context and nuance makes LLM data extraction more accurate and relevant. You can leverage LLMs’ semantic understanding to summarize key information for digestibility or examine intent and sentiment.
- Few-Shot and Zero-Shot Learning
LLMs can extract data using few-shot or zero-shot learning, minimizing the need for task-specific training. If you’re using the few-shot approach, you provide your LLM with some examples of the data you want it to extract. The LLM will then generalize this logic and use it on similar documents. Zero-shot learning allows LLMs to perform tasks that they’re not explicitly trained for. For instance, you can create prompts that ask the LLM to extract information based on its pre-existing knowledge and understanding.
- Fine-tuning for Increased Accuracy
You can fine-tune LLMs using industry-specific datasets to enhance their accuracy further. When trained using such datasets, LLMs can understand technical jargon, domain-specific language, or unique document structures effectively. This is especially useful in the healthcare, law, and finance sectors—where data includes specific terminologies, protocols, and processes.
How LLM Data Extraction Works
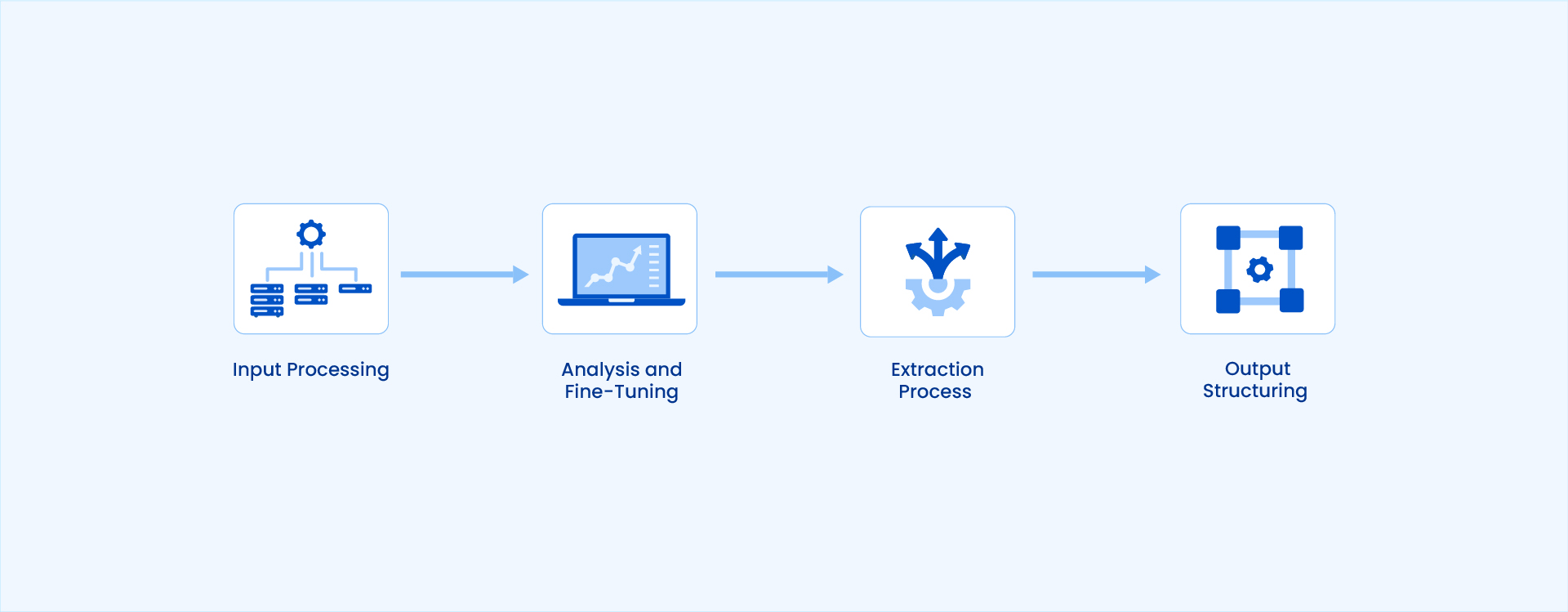
Here’s a breakdown of the LLM data extraction process:
Step 1: Input Processing
Data extraction using an LLM begins with a tokenization process, where the LLM converts the input data into smaller units (known as tokens) before turning them into analyzable numeric representations (known as embeddings).
Step 2: Analysis and Fine-Tuning
Next, your LLM will use its pre-trained knowledge to analyze the data and its meaning. Fine-tuning a pre-trained LLM is optional. However, if you’ve fine-tuned your LLM using specific datasets, you can adapt it to more specialized tasks depending on your business requirements. This fine-tuning and specialization will also come into play at this stage and be integrated into the analysis.
Step 3: Extraction Process
Using pattern recognition, the LLM will identify patterns or entities (such as names, dates, amounts, or order details) in the analyzed text and extract data efficiently. You can also instruct the LLM to perform more targeted extraction using prompts, such as ‘find all customer IDs in this data’.
Step 4: Output Structuring
After extracting the required data, the LLM will convert the output and present it in a structured format that you can use, such as a table, a list, or a JSON file.
Utilizing the model’s contextual understanding of language, LLM data extraction makes it easy to obtain the required information regardless of the source. These intelligent language models outperform conventional extraction approaches such as rule-based systems, regular expressions, and template matching.
Transform Data Extraction with LLMs
Leverage the intelligence of LLMs for faster, smarter data processing. Start your free trial today and transform your workflows.
Speak to Our Team Speaking of Intelligent Models…
Using LLMs for data extraction is the logical step forward if you’re looking to transform your extraction and document processing. LLM data extraction can help you automate repetitive or time-intensive tasks, create more streamlined extraction workflows, and obtain more accurate and consistent data. You can scale it to keep up with expanding data volumes and enjoy improved data quality and reduced time to insight. Moreover, adaptive learning ensures your LLM can accommodate new document types and formats and improve its extraction capabilities with time.
Astera helps you make the most of LLM data extraction. Using Astera Intelligence—our impressive suite of AI capabilities—you can prepare, clean, and optimize data for fine-tuning your LLMs. You can also build custom LLMs that have an in-depth understanding of your data and cater to your particular domain. Experience faster data extraction with our AI-driven tool that automatically generates templates and intelligently fetches data based on your specified fields.
Discover what data extraction can be. Set up a free trial or speak to our team today.
Authors:
Usman Hasan Khan



