 Astera AI Agent Builder - First Look Coming Soon!
Astera AI Agent Builder - First Look Coming Soon!
The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

ETL Data With Astera’s Native Connector for Amazon Redshift
In this article, we’ll discuss how Amazon Redshift works and how it compares to traditional on-premises data warehouses. We’ll also explore how Astera helps businesses use Amazon Redshift to its full potential with a native data connector.
What is Amazon Redshift?

Offered by Amazon Web Services (AWS), Amazon Redshift is a powerful cloud-based data warehouse that enables quick and efficient processing and analysis of big data. It provides easy scalability, high performance, real-time data access, deep analytics capabilities, and seamless integration with other applications, making it a preferred choice for many organizations. Amazon Redshift can handle large volumes of data without sacrificing performance or scalability. Therefore, it helps businesses reduce data processing time and improve their analytics capabilities.
Its primary goal is to assist businesses in leveraging their stored data to gain insights into their customers, make better decisions, and drive revenue growth. Therefore, by storing large amounts of structured or semi-structured data, users can quickly query the data using standard SQL-based ETL tools and business intelligence software.
With Amazon Redshift, businesses can extract valuable insights from datasets stored in their data warehouses. This data can be used to analyze customer behavior patterns, track inventory levels, or inform decisions around product development and marketing campaigns. Amazon Redshift is capable of processing queries on petabytes of data in seconds, delivering high performance with low latency.
Comparing Redshift to conventional data warehouses
First, we’ll explore the differences between Amazon Redshift and common data warehouses. Conventional data warehouses use relational databases and require a great deal of manual effort to set up. They have only one server, so they aren’t as fast or as efficient in gathering large datasets.
In contrast, Amazon Redshift allows users to store and analyze petabytes of data. It uses MPP (Massively Parallel Processing) to break down queries into small pieces that can be executed in parallel for increased performance. This makes it much faster than traditional data warehouses, making it ideal for complex analytics operations and applications that require quick access to large amounts of data.
Amazon Redshift also offers scalability, as users can easily increase their storage capacity and computing power when needed. It utilizes columnar storage technology, which allows users to scan fewer columns when executing certain queries. Therefore, reducing the amount of time needed for the operation to complete. Additionally, Amazon Redshift integrates with other AWS services for easy set up and management of resources.
Benefits of Amazon Redshift
Amazon Redshift brings a range of benefits to the table compared to traditional data warehouses. By combining a cost-effective infrastructure, scalability, and superior analytics capabilities, Amazon Redshift offers unparalleled power in data warehousing.
Cost-effective infrastructure
Amazon Redshift is an affordable data warehouse solution, allowing companies to store and analyze enormous amounts of data without breaking the bank. It is based on an Infrastructure as a Service (IaaS) model. This means that businesses don’t need to invest in expensive hardware and software.
Scalability
Amazon Redshift is highly scalable, allowing businesses to easily increase or decrease their computing resources as their needs change. This is achieved using clusters and elastic resizing, which enables businesses to add or remove nodes from their Redshift clusters without any downtime or disruption to their analytics workloads. These features make Amazon Redshift a flexible solution for analyzing large volumes of data.
Superior analytics capabilities
Amazon Redshift also offers superior analytics capabilities when compared to traditional data warehouses. Through its integration with powerful tools like Apache Hive and Apache Spark, businesses can quickly analyze large datasets and gain valuable insights into their customer base, operations and more.
Loading data to Amazon Redshift with a native connector
Using a native connector to extract, transform, and load data into Amazon Redshift is more efficient and less error-prone compared to manual coding. When coding, data engineers need to write complex ETL scripts, often dealing with different data sources and ensuring that each transformation is correctly implemented. This process can become tedious and time-consuming, especially for large data sets or recurring jobs.
A data integration tool with native connectors automates much of this process, offering a user-friendly interface with pre-built functionalities that reduce the chances of human error while speeding up the ETL workflow. Users can extract data from multiple sources—cloud platforms, on-premises databases, or external APIs—without writing extensive code. The transformation steps are visually configurable, allowing users to clean and structure the data based on predefined logic. Finally, the data is loaded directly into Amazon Redshift, optimized for fast querying and analytics. This approach removes the complexities of hand-coding while offering better performance and scalability by leveraging Redshift’s architecture.
Organizations that benefit the most from using a native connector include those that handle large volumes of data or have a diverse set of data sources but lack the technical bandwidth to build and maintain custom ETL pipelines. It’s particularly advantageous for teams that prioritize speed, accuracy, and the ability to scale quickly. This solution allows them to focus on data analysis and decision-making rather than spending time managing the infrastructure required to move and prepare data.
Challenges and limitations with Amazon Redshift
While Amazon Redshift integrates easily with other AWS services, it has limited support for other software ecosystems. If you are running software outside of the Amazon infrastructure, you may not be able to use all its features.
Additionally, Amazon Redshift is a cloud-based application that relies on the availability of network bandwidth and storage space. If these two resources are insufficient, performance will suffer and may cause applications to crash or become unresponsive.
Connect to Amazon Redshift with Astera’s native connector
With Astera’s native connector, users can take full advantage of the power and scalability of Amazon Redshift, allowing organizations to access and analyze data in ways that are not usually possible with traditional data warehouses. Astera offers an easy-to-use visual interface, enabling users to create data integration and data migration pipelines, as well as data models for data warehousing architectures. These include dimensional models and data vaults.
Astera features a drag-and-drop environment, allowing business users to connect to the Redshift DB without typing long chunks of code or specifying connection strings. Easily configure Redshift connectivity to process data or perform database lookups by selecting Amazon Redshift from the drop-down list of supported databases.
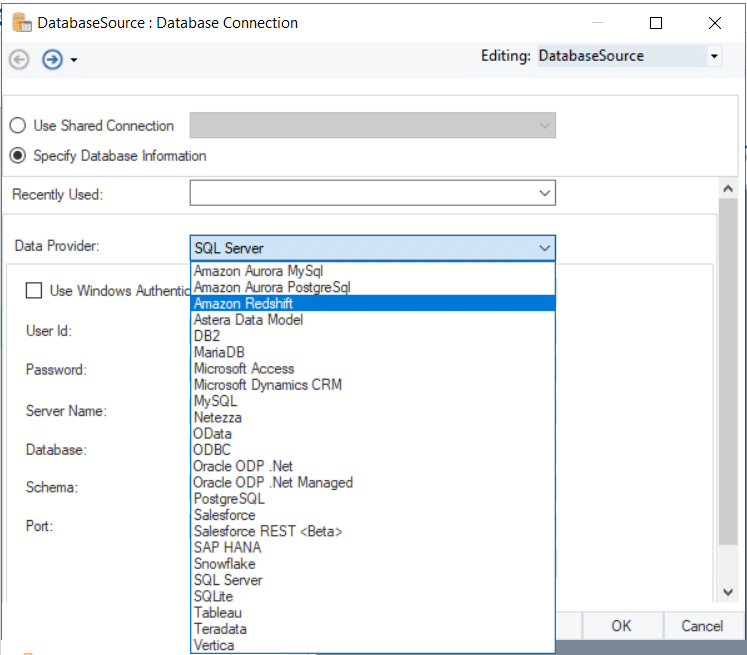
Figure 1: Scroll through the list of data providers supported by Astera and connect to Redshift
Amazon Redshift database as a source
Drag the database table source object from the toolbox and drop it onto the designer window to connect to the Redshift database and use it as a source object. Next, you can configure it by selecting Redshift as the data provider from the drop-down list.
In the next step, we need to select the table from which the data will be sourced. In this case, we are selecting a table with employee details named public.orders. We can click on the Partition Table for the Reading option to break the table into smaller segments that will be read individually. This option can be selected to reduce the load on the database and improve performance. Here, we also can select the key field to divide the table into partitions.
Another option in the database properties table is for specifying the Read Strategy. Here, we can decide whether we want to read the complete data (Full Load) or just updated records (Incremental Load Based on Audit Fields).
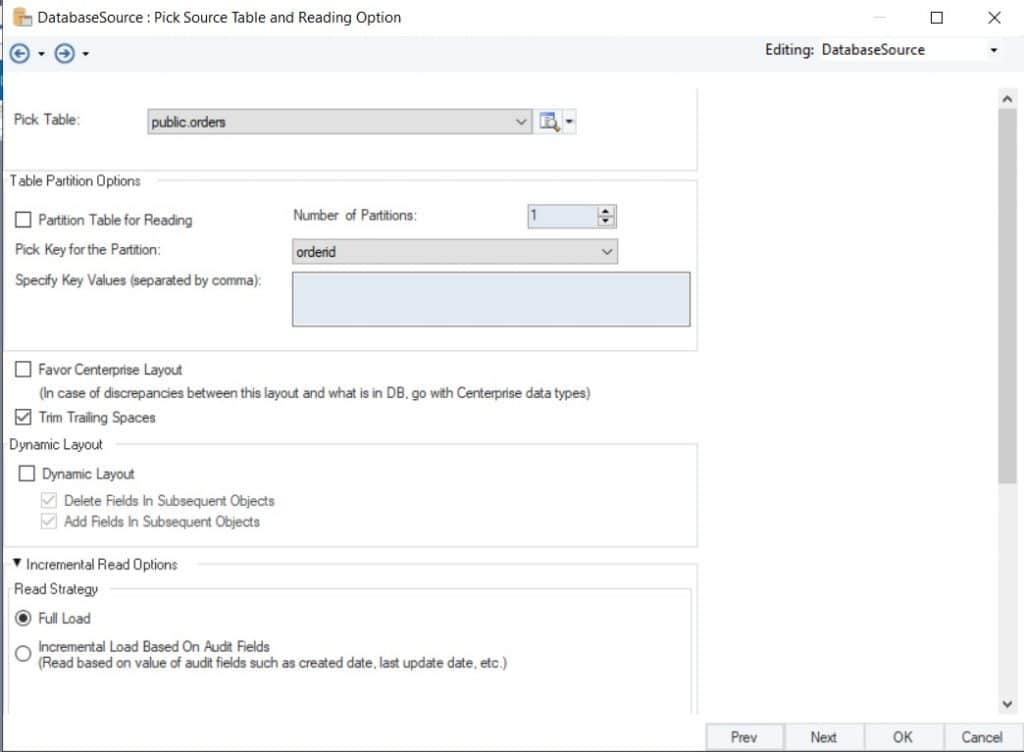
Figure 2: Selecting the table and Read Strategy for our Database Source
The next screen shows the Layout Builder for the Database Source Table. Here, we can see the data types and lengths of each field, along with a few other details.
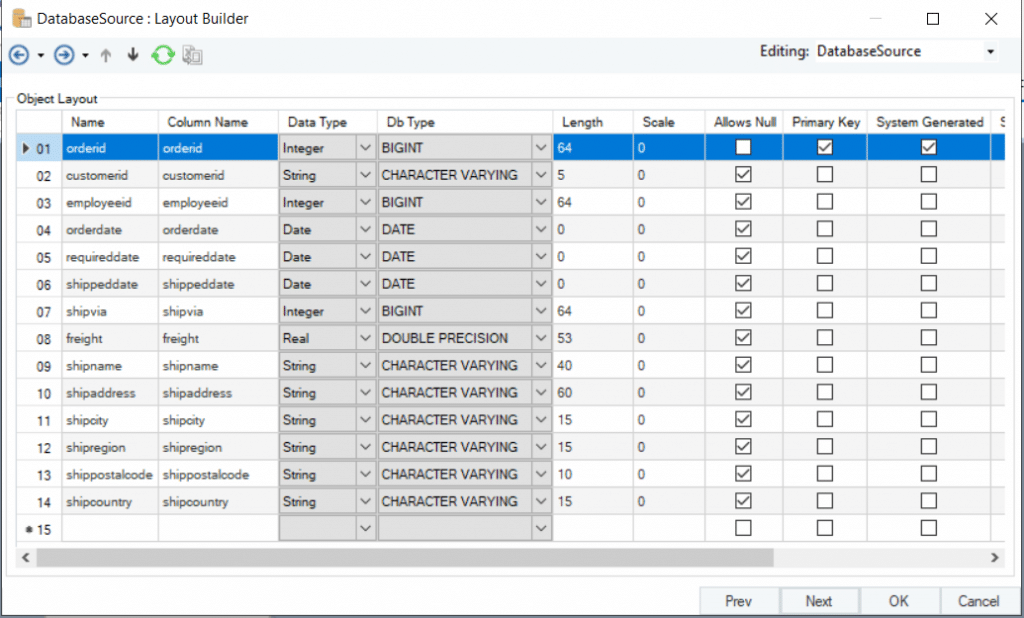
Figure 3: The Layout Builder of the Redshift Database Table with details about the data type and length of each field.
The data from this Redshift table can be processed in multiple ways using various built-in transformations available in Centerprise and loaded to a file, database, or any other available destination.
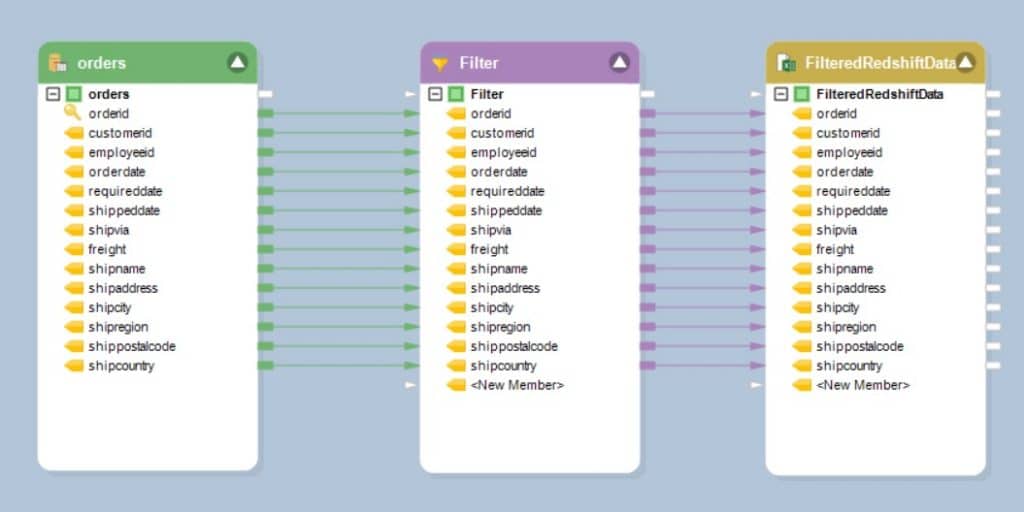
Figure 4: A dataflow showing a filter being applied to data sourced from a Redshift table and mapped onto an Excel destination object
The screenshot above shows a dataflow that filters data from the Orders table using a Filter transformation and mapped on an Excel destination file named FilteredRedshiftData.
Amazon Redshift database as a destination
Users can also connect to the Amazon Redshift database and configure it as a destination object. For this, the database table destination object needs to be dragged from the toolbox and dropped on to the designer. Next, we need to point the destination object to the Redshift database as follows:
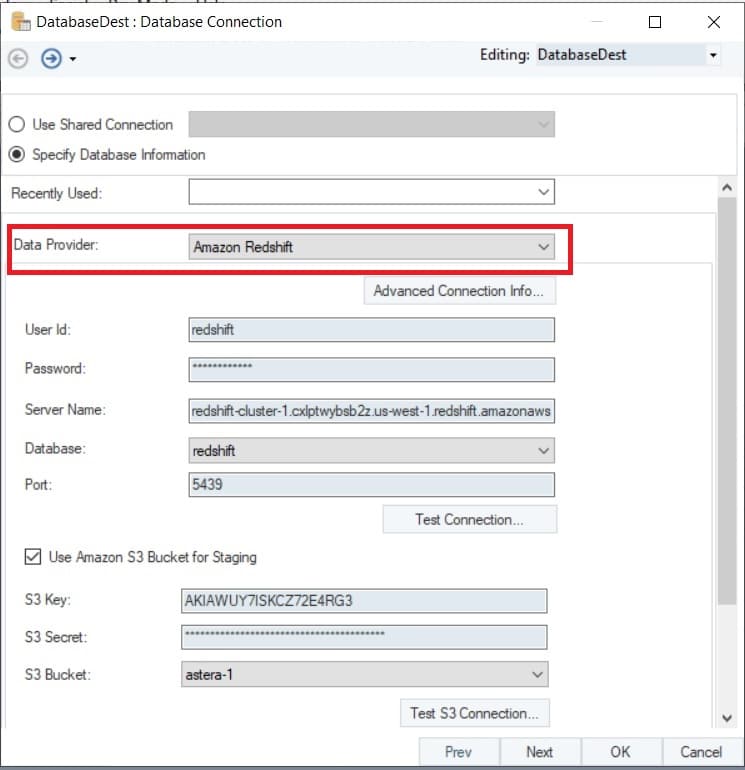
Figure 5: Configuring a database table destination object with Redshift as the data provider.
The image also shows an option where users can add their Amazon Simple Storage Service (S3) credentials to load data in bulk to the Redshift DB.
Once Redshift has been selected as the data provider, the user needs to decide whether they want to pick an existing table, create a new one, or overwrite the data present on an existing one. In this case, we have created a new table in the database and named it WebAggregate.
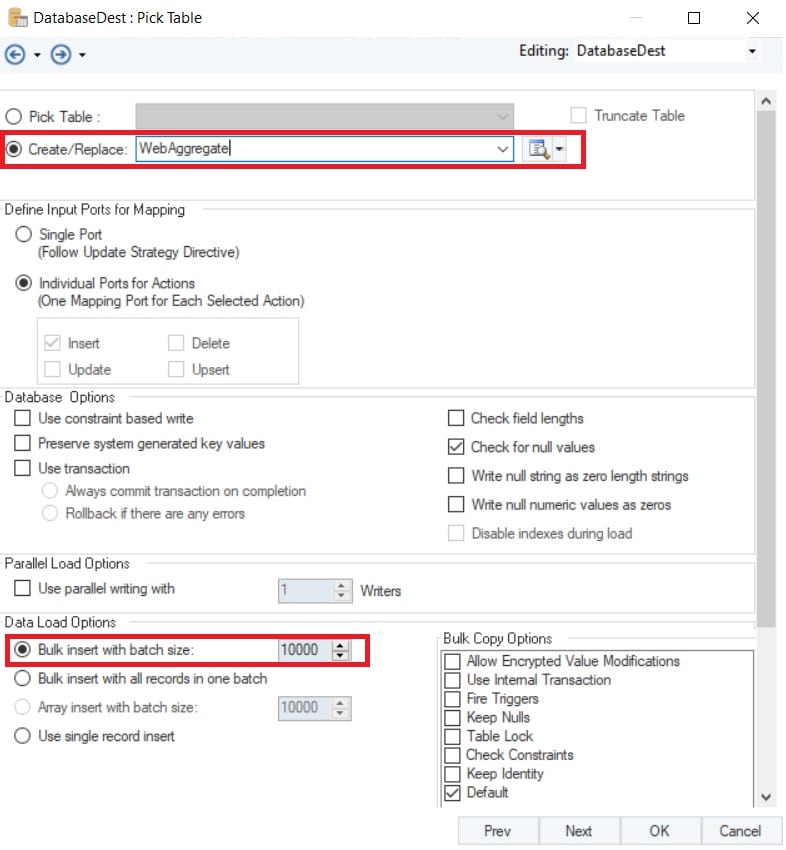
Figure 6: A new database table named WebAggregate is created to load data in bulk.
In this example, data from a Database source object named WebConnectionRegistration is aggregated and passed to the WebAggregate database table. The complete dataflow is as follows:
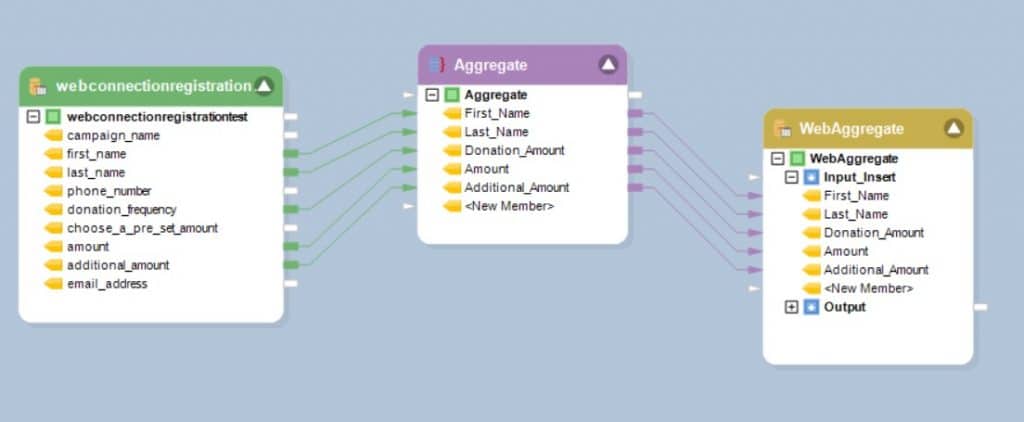
Figure 7: Data from a database table is aggregated and mapped to a Redshift destination table.
Conclusion
Ultimately, Amazon Redshift is an incredibly powerful data warehouse solution that can help organizations uncover insights that drive business decisions. By leveraging the speed and scalability of Amazon Redshift, organizations can quickly and easily gain insights from their data. Alongside this, they can benefit from significant cost savings compared to traditional data warehouses.
With Astera, users can:
- Automate the process of extracting, transforming, and loading (ETL) data from multiple sources into a single repository on Amazon Redshift.
- Automate scheduling of your AWS ETL workflows with the built-in job scheduler feature to ensure repetitive tasks are handled accurately and on-time.
- The solution’s visual data modeler enables users to create and modify data models using a simple drag-and-drop interface.
- Users can define relationships between tables, create primary and foreign keys, and specify data types and constraints for each field in their data model.
- Astera Data Warehouse Builder also supports reverse engineering. This allows users to generate data models from existing databases or data warehouses in Amazon Redshift.
- The solution also provides extensive documentation and version control features. Therefore, making it easier for users to manage and maintain their data models over time.
- With automatic script generation capabilities, users can forward engineer their logical data models to physical databases on Amazon Redshift, or any of the supported providers.
By using Astera to connect to Amazon Redshift, businesses can effectively leverage their stored data to gain insights and improve decision-making.
Authors:
Astera Analytics Team



