 Astera AI Agent Builder (Coming soon)
Astera AI Agent Builder (Coming soon) 
 July 22nd | 11 AM PT
July 22nd | 11 AM PT


The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

Scalable ETL Architectures: Handling Large Volumes of Data
Extract, Transform, Load (ETL) architectures have become a crucial solution for managing and processing large volumes of data efficiently, addressing the challenges faced by organizations in the era of big data.
These architectures are designed to handle massive datasets by utilizing distributed computing frameworks like Apache Hadoop and Apache Spark, along with employing parallel processing and data partitioning techniques.
Implementing scalable ETL architectures enables organizations to unlock the potential of their data repositories, facilitating timely and valuable insights for informed decision-making. This article delves into the complexities of building and optimizing scalable ETL architectures to meet the demands of modern data processing.
What Is the Architecture of an ETL System?

ETL architectures consist of components and processes that enable the efficient handling of data extraction, transformation, and loading. These architectures facilitate the seamless flow of data from diverse sources to a designated destination.
Key components include the data source layer, responsible for interfacing with various data sources like databases and APIs, and the extraction layer, which retrieves the required data.
The transformation layer applies cleansing, filtering, and data manipulation techniques, while the loading layer transfers the transformed data to a target repository, such as a data warehouse or data lake. ETL architectures ensure data integrity and enable organizations to derive valuable insights for decision-making.
Types of ETL Architectures
- Batch ETL Architecture: The architecture enables real-time streaming ETL, where data streams from sources like IoT devices or social media feeds are handled in near real-time. The system continuously ingests the data, transforms it, and loads it in real-time to target systems or analytics platforms. This architecture is suitable when near-real-time processing is not critical, and periodic updates are sufficient.
- Real-time Streaming ETL Architecture: Data streams are handled in near real-time. They are continuously ingested from sources like IoT devices or social media feeds. The data is transformed and loaded in real-time to target systems or analytics platforms. This architecture enables immediate decision-making and event response.
- Hybrid ETL Architecture: This architecture combines both batch and real-time processing. It can handle both batch data and streaming data, providing flexibility. Batch processing deals with non-time-sensitive data, while real-time processing allows for immediate insights from streaming data. This architecture effectively caters to various data processing requirements.
How to Build ETL Architectures
To build ETL architectures, the following steps can be followed,
- Requirements Analysis: Analyze data sources, considering scalability, data quality, and compliance requirements.
- Technology Selection: Choose suitable tools and technologies based on data volume, processing needs, compatibility, and cloud options.
- Data Flow and Integration Design: Design the overall data flow and integration processes, including sequencing, transformation rules, and data governance policies.
- Data Extraction: Implement efficient data extraction methods, considering extraction schedules and techniques for extracting only new or changed data.
- Data Transformation: Apply transformation rules for data cleansing, validation, formatting, standardization, and profiling.
- Data Loading: Design a reliable loading mechanism, create target data structures, optimize loading performance, and implement data partitioning strategies.
- Error Handling and Monitoring: Implement mechanisms to handle errors, monitor ETL processes for performance, errors, and data inconsistencies, and set up logging and alerting systems.
- Testing and Validation: Conduct comprehensive testing and validation at each stage, including data accuracy, completeness, consistency, and regression testing.
- Optimization and Maintenance: Continuously monitor and optimize the ETL architecture, fine-tune processes, review and update the architecture, and establish data archival and retention policies.
This is how ETL architectures can be built through the above steps.
Challenges with Designing an ETL Architecture Framework
There are certain challenges associated with designing an ETL framework,
- Handling Diverse Data Sources: Dealing with various data sources that have different formats, protocols, and connectivity options.
- Processing Large Data Volumes: Efficiently processing and transforming massive amounts of data, while keeping scalability in mind for future growth.
- Ensuring Data Quality: Implementing validation checks and ensuring data integrity to address any issues related to data quality.
- Accurate Data Transformation: Mapping and transforming data accurately and efficiently across different data sources and structures.
- Managing Metadata: Effectively managing metadata, schemas, transformations, and dependencies for data lineage and troubleshooting purposes.
- Robust Error Handling: Building systems that can handle errors and retries, ensuring data integrity and reliability.
- Performance Optimization: Optimizing the ETL process to achieve high performance and reduced processing time.
- Incremental Data Extraction: Supporting the extraction of only changed or new data, efficiently tracking changes.
- Data Security and Compliance: Ensuring data security, privacy, and compliance with regulatory requirements.
- Monitoring and Logging: Implementing effective systems for monitoring and logging, providing visibility, and identifying potential issues.
These are the challenges that are associated with designing an ETL framework.
What Are the Best ETL Architecture Practices?
ETL practices are essential for efficient data integration and processing. The best ETL practices involve several key elements.
Data Profiling, Transformation, and Error Handling
To ensure accurate extraction, comprehensive data profiling and understanding of data sources are essential. Thoroughly examining the structure, quality, and characteristics of the data enables the extraction of relevant and reliable information.
Data transformation is another critical aspect that involves cleansing, validation, and standardization. Cleaning eliminates inconsistencies, errors, and duplicates, ensuring data quality and consistency. Validation checks for data integrity, while standardization harmonizes formats for seamless integration into the target system.
Implementing robust error handling and logging mechanisms is crucial for effective ETL processing. These mechanisms identify and resolve issues, capture, and log errors, generate notifications, and handle exceptional scenarios gracefully. By having a reliable error-handling system in place, organizations can maintain data integrity and reliability throughout the ETL process.
Monitoring and Security
Scalable and parallel processing techniques significantly enhance performance in ETL architectures. By distributing data processing tasks across available resources, organizations can achieve faster processing and effectively handle growing data volumes.
Regular monitoring, testing, and documentation practices are crucial to maintaining reliability and scalability. Monitoring ensures the health and performance of ETL workflows while testing validates data transformations to ensure accuracy. Documentation plays a key role in facilitating troubleshooting and making modifications to the ETL system as needed.
Lastly, it is important to employ robust security measures in ETL architectures. Data encryption ensures the protection of sensitive information during transit and while at rest. Implementing access controls helps restrict unauthorized access and modifications to the data, ensuring its integrity and confidentiality.
By prioritizing security measures, organizations can maintain the trust and privacy of their data throughout the ETL process.
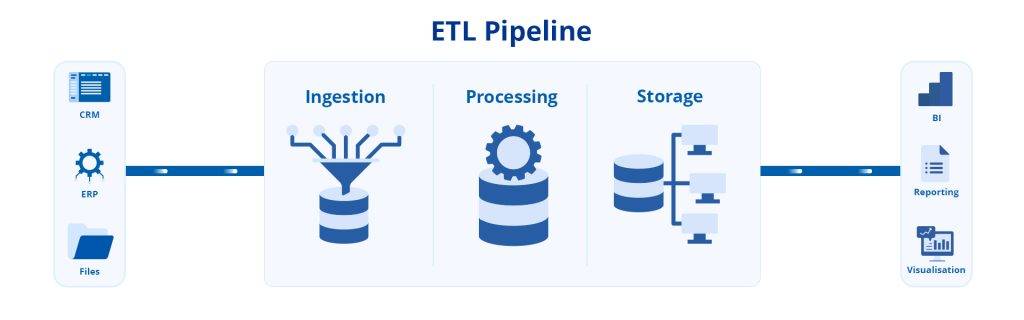
Key Considerations for Designing ETL Architecture
Ensuring high-quality data
Data must be accurate and trustworthy to ensure effective decision-making. Companies can use data preparation and validation tools to check for errors and clean up any messes in the data. A repository of high-quality data ensures that decisions made based on data-driven insights are sound and reliable.
Identifying data sources and targets
A clear understanding of where the data comes from and where it’s headed streamlines the data movement and avoids hiccups along the data pipeline. Therefore, a data architect must know the ins and outs of your databases, applications, and file systems. It also helps identify the right tools for extraction based on source format, design data transformations for the target system’s needs, and ensure data quality throughout the pipeline.
Choosing between batch and streaming ETL
The latency requirement is the deciding factor between batch processing and streaming ETL. Batch processing involves collecting and handling data in chunks or batches, which is great for dealing with large volumes of data. An example of this would be daily or weekly data backups where transaction logs and other data files are accumulated and uploaded to a secure storage location in batches at a scheduled interval.
Conversely, stream processing allows for real-time or near-real-time data ingestion and analysis, providing instant insights and responses to changing data streams. For example, users can create streaming ETL jobs to continuously ingest, transform, and load data in micro-batches as they arrive.
Addressing data governance requirements
Data governance provides a set of rules and practices to ensure that the data is handled securely and in compliance with relevant laws and regulations. These practices include defining who has access to what data, setting up security measures, and ensuring users are aware of their responsibilities in handling data. A data governance framework strengthened with data classification, access controls, and lineage tracking protects data from unauthorized access or misuse and helps maintain trust and credibility.
Automating ETL Pipelines with Astera
Astera Centerprise, a no-code data pipeline tool, is a powerful platform that automates ETL pipelines, revolutionizing data integration. With its user-friendly interface and robust features, Astera simplifies the ETL process and boosts productivity.
Extraction and Connectors
The platform’s automation capabilities allow for complex data transformations. Its visual interface enables users to easily design data workflows by dragging and dropping components, reducing the need for manual coding. This makes it accessible to users with varying technical expertise.
Astera Centerprise, a no-code data pipeline builder, offers a wide range of pre-built connectors for various data sources, facilitating seamless data extraction from databases, cloud platforms, and file formats. It supports both batch and near real-time data processing, enabling organizations to integrate data from diverse systems and maintain up-to-date analytics.
Transformation and Automation with Astera
The platform also provides powerful data transformation capabilities. It offers a rich library of transformation functions, allowing users to cleanse, filter, aggregate, and manipulate data according to their requirements. The platform fully supports complex transformations, enabling users to join multiple datasets and apply custom business logic.
Automating ETL pipelines with an ETL tool brings numerous benefits to organizations. It reduces the time and effort required for data integration, improves data quality by eliminating manual errors, and enables faster and more informed decision-making based on accurate and up-to-date information. Astera’s intuitive interface and comprehensive features make it a game-changer for automating ETL pipelines and streamlining data integration processes.
Conclusion
Scalable ETL architectures are crucial for efficiently handling large data volumes. They enable organizations to extract, transform, and load data from diverse sources into target systems effectively. Distributed processing frameworks, parallelization techniques, efficient data storage, and fault tolerance measures are key considerations for scalability.
Cloud technologies like serverless computing and auto-scaling enhance scalability further. A robust ETL architecture empowers organizations to derive valuable insights and make data-driven decisions at any scale.
Authors:
Astera Analytics Team



