 Astera AI Agent Builder - First Look Coming Soon!
Astera AI Agent Builder - First Look Coming Soon!
The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.
What is Data Consolidation? Overview & Techniques
Your organization may appear as a highly systematized structure to the external world. But internally, it is an assortment of data gathered from databases, files, and several other sources. This data can help your business evolve and improve, but only if you manage it efficiently. Data consolidation can help you do that!
This blog will present an overview of data consolidation, as well as some standard techniques used for consolidating data.
What is data consolidation?
Data consolidation is the process of combining data from multiple sources, cleaning and verifying it by removing errors, and storing it in a single location, such as a data warehouse or database. Data is produced from various sources and in multiple formats in every business. The data consolidation process makes it easier to unify that data.
Consolidating data enables companies to efficiently plan, implement, and execute business processes and disaster recovery solutions. This is done because all critical data in one place grants users a 360-degree view of all their business assets. It improves data quality, fast-tracks process execution, and simplifies information access. Thus, proving how necessary data consolidation is.
Understanding the difference between data integration and data consolidation
Data integration and consolidation are often used interchangeably, but these two processes have some key differences. Data integration encompasses a broader set of activities to create a unified view of data by combining data from different sources into a single source of truth (SSOT). On the other hand, data consolidation specifically emphasizes the process of merging and organizing data from multiple sources into a storage repository and make a coherent data set. It is performed to standardize data structure and ensure consistency. In short, data consolidation is a subset of data integration.
Organizations must understand the differences between data integration and consolidation to choose the right approach for their data management needs. By doing so, they can ensure that their data is accurate, consistent, and reliable.
Data consolidation techniques
Data consolidation aims to create a unified data set that can be easily analyzed, allowing businesses to gain valuable insights and make informed decisions. The following are the three most common data consolidation techniques:
ETL (extract, transform, load)
ETL is one of the most widely used data management techniques for consolidating data. It is a process in which data is extracted from a source system and loaded into a target system after transformation (including data cleansing, aggregation, sorting, etc.).
Automated data integration tools can carry out ETL in two ways:
- Batch processing: suitable for running repetitive, high-volume data jobs.
- Real-time ETL: uses CDC (change data capture) to transfer updated data to the target system in real-time.
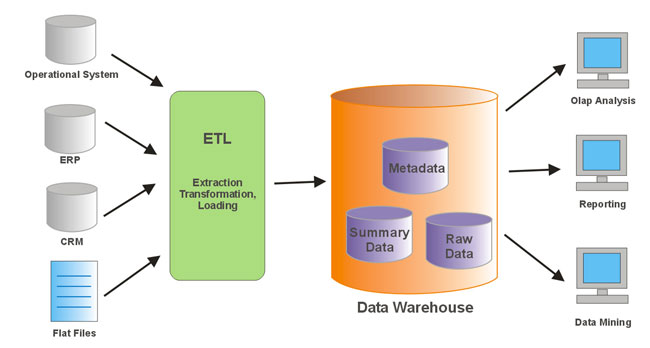
Source: Wisatakuliner
Data virtualization
Data virtualization integrates data from heterogeneous data sources without replicating or moving it. It provides data operators with a consolidated, virtual view of information.
Unlike the ETL process, the data stays in its place but can be retrieved virtually by front-end solutions like applications, dashboards, and portals without knowing its specific storage site.
Data warehousing
Data warehousing is the process of integrating data from disparate sources and storing it in a central repository. Hence, facilitating reporting, business intelligence, and other ad-hoc queries. It provides a broad, integrated view of all data assets, with relevant data clustered together.
Data gathered in a single place using a data consolidation tool makes it easier to determine trends and create business plans.
Data lake
A data lake is an unstructured storage system that stores large volumes of raw data. Unlike a data warehouse, a data lake does not limit the data types that can be stored, making it more flexible, but also more challenging to analyze.
One of the key benefits of a data lake is that it can also store unstructured data, such as social media posts, emails, and documents. This makes it a valuable resource for organizations that need to consolidate and analyze a wide range of data types.
Master Data Management (MDM)
Master data management (MDM) is a process of consolidating data to create a single, authoritative source of data for business-critical information, such as customer or product data. MDM ensures data consistency and reduces duplication across systems. It is particularly useful in scenarios where data integrity, data governance, and data quality are of utmost importance, such as customer data management, product information management, and regulatory compliance.
Wrap up
The data consolidation tasks offer businesses several benefits. When data is stored in one location, it requires a smaller setup for management. This allows companies to cut down their costs.
Moreover, by consolidating big data, you can enjoy better control as there are fewer processes involved in data retrieval, and you can access data directly from one place. This ensures significant time savings. Plus, planning, implementing, and executing disaster recovery solutions become comparatively more straightforward as all the critical data is in one location.
If you’re looking for a user-friendly, AI-powered data consolidation solution, give Astera a try! It empowers users to consolidate data using ETL, data virtualization, and data warehousing. You can select the technique that best fits your requirements.
Authors:
Tehreem Naeem



