 Astera AI Agent Builder - First Look Coming Soon!
Astera AI Agent Builder - First Look Coming Soon! Apr 29th | 11 AM PT
Apr 29th | 11 AM PT

The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

Data Exploration: A Comprehensive Guide
A clear understanding of data health enhances data quality and trustworthiness. This is where data exploration comes into play.
Data exploration provides extensive insights into the characteristics of your data. You can uncover data anomalies and learn how to address them by delving deep. Whether identifying outliers, understanding correlations, or refining feature selection, data exploration empowers you to make informed decisions.
What Is Data Exploration?
Data exploration is the initial step in data preparation and analysis using data visualization tools and statistical techniques to uncover patterns and relationships within a dataset. It helps identify outliers, detect relationships between variables, and understand the nature of data.
Data Exploration vs Data Visualization
Data exploration often involves data visualization to help you understand the dataset’s structure, the presence of outliers, and the distribution of data values. On the other hand, data visualization tools, such as bar charts and scatter plots, are valuable in visual data exploration, providing a visual representation of the data that can aid in identifying patterns and relationships.
Data Exploration vs Data Mining
Data exploration manually sifts through data to understand its characteristics and structure. For example, a data analyst might use a scatter plot to identify outliers or understand the distribution of data points.
On the other hand, data mining is an automated process that aims to extract useful information and patterns from large datasets. It uses sophisticated algorithms to discover patterns that are not immediately apparent. Data Mining is often used for predictive analysis, such as forecasting future trends or behaviors based on historical data.
Data Exploration vs Data Discovery
Data exploration and data discovery are related but distinct concepts. Data discovery is cataloging data assets, making it easier for users to search and understand what data is available. On the other hand, data exploration explores and visualizes data to uncover insights and identify areas or patterns to dig deeper into.
Why Is Data Exploration Important for Businesses?
Data exploration uncovers patterns and relationships between variables. These insights prove invaluable for businesses aiming to understand customer behavior, optimize operations, and outpace competitors. Here are some key benefits of data exploration:
Identify Patterns and Trends
Data exploration is integral to Exploratory Data Analysis (EDA). It statistically analyzes and visualizes data, revealing trends that, once confirmed, can help you develop more effective business strategies.
Improve Operational Efficiency
According to McKinsey, data-driven workflows can help organizations save 42% of time on internal processes, thus improving operational efficiency. Data exploration serves as a valuable starting point for uncovering potential areas of improvement.
Drive Growth
Data exploration lays the groundwork for more sophisticated analytics that drive business growth. It can help you identify new opportunities and segments or markets to target. Accenture finds that businesses that use data analytics to identify new opportunities and markets are 23% more likely to grow their revenue. Through data exploration, you can gain insights for formulating strategies that drive growth and establish a solid foundation for future business intelligence.
How to Explore Data in 10 Easy Steps
Step 1: Identify the Data Domain
Learning the domain and familiarizing yourself with its structure and content will allow you to get the most value out of your data. Understanding the context will provide a better understanding of the data’s meaning, relevance, and purpose. For instance, Electronic Health Records (EHR) data is complex and requires deep knowledge of medical terminology, clinical workflows, and health information technology. Without this knowledge, users couldn’t utilize this data as effectively.

You must also understand why you’re using that dataset. Knowing your objectives will help you set the right data exploration goals. Are you trying to identify patterns or outliers? Or do you want to detect errors or understand the distribution of your data? By understanding your goals, you can more effectively profile your data.
Step 2: Gather Relevant Data
You must consolidate, combine, or merge data from different sources based on your requirements. These sources can be database tables or other formats that store relevant data. However, not all sources are compatible with each other. You often need to find a common field or key to link them.
For example, if you are working with EHR data, you can use the patient ID as a shared key to join data from tables such as patient demographics, medical history, medication orders, lab results, etc. This way, you can gain a more comprehensive understanding of the information.

Step 3: Get Familiar with Your Data
Before you start analyzing your data, you must get familiar with it. You should check the quality and suitability of your data for your analysis goals.

For example, if you have a dataset of customer transactions, you could explore the following aspects of your data:
- The distribution: How are the transaction amounts spread across different ranges? What is the average, variance, and standard deviation of the transaction amounts?
- The frequency of transactions per customer: How often do customers make transactions? What is the average, median, and mode of the number of transactions per customer? Are there any customers who make very few or very many transactions?
- Any unusual patterns in the data: Are there any trends, cycles, or seasonality in the data?? Are there any missing or incorrect values in the data?
Step 4: Evaluate the Suitability of Your Data
You must ensure your data is suitable for your analysis objectives. Therefore, evaluating its relevance, timeliness, and representativeness is essential. Relevance means how closely your data relates to the questions you want to answer.

Timeliness means how recent your data is and whether it reflects the current situation. Representativeness means how well your data covers the population or phenomenon you are interested in. By evaluating these aspects, you can decide whether your data is sufficient or whether you need to collect more data.
If you want to analyze the long-term trends in customer behavior for an online store. If you only have a dataset of customer transactions from the past year, your data might need to be more relevant, timely, and representative. You might need to collect more historical data from previous years to capture the changes and patterns in customer behavior over time.
Step 5: Identify Data Types, Formats, and Structures
The next step is to identify the data types, formats, and structures of your data. Your data could be Date, numerical, Boolean, categorical, string, etc. You should review each column of your data and identify its data type. This will help you understand how your data is organized, what each variable means, and what values it can have.

It’s also essential to review the structure of your data at a detailed level. This will help you choose the right statistical methods for your analysis. You can learn more about your data by reviewing the data dictionary, codebook, or metadata that comes with your data. These resources can help you interpret your data and make better decisions about how to analyze it.
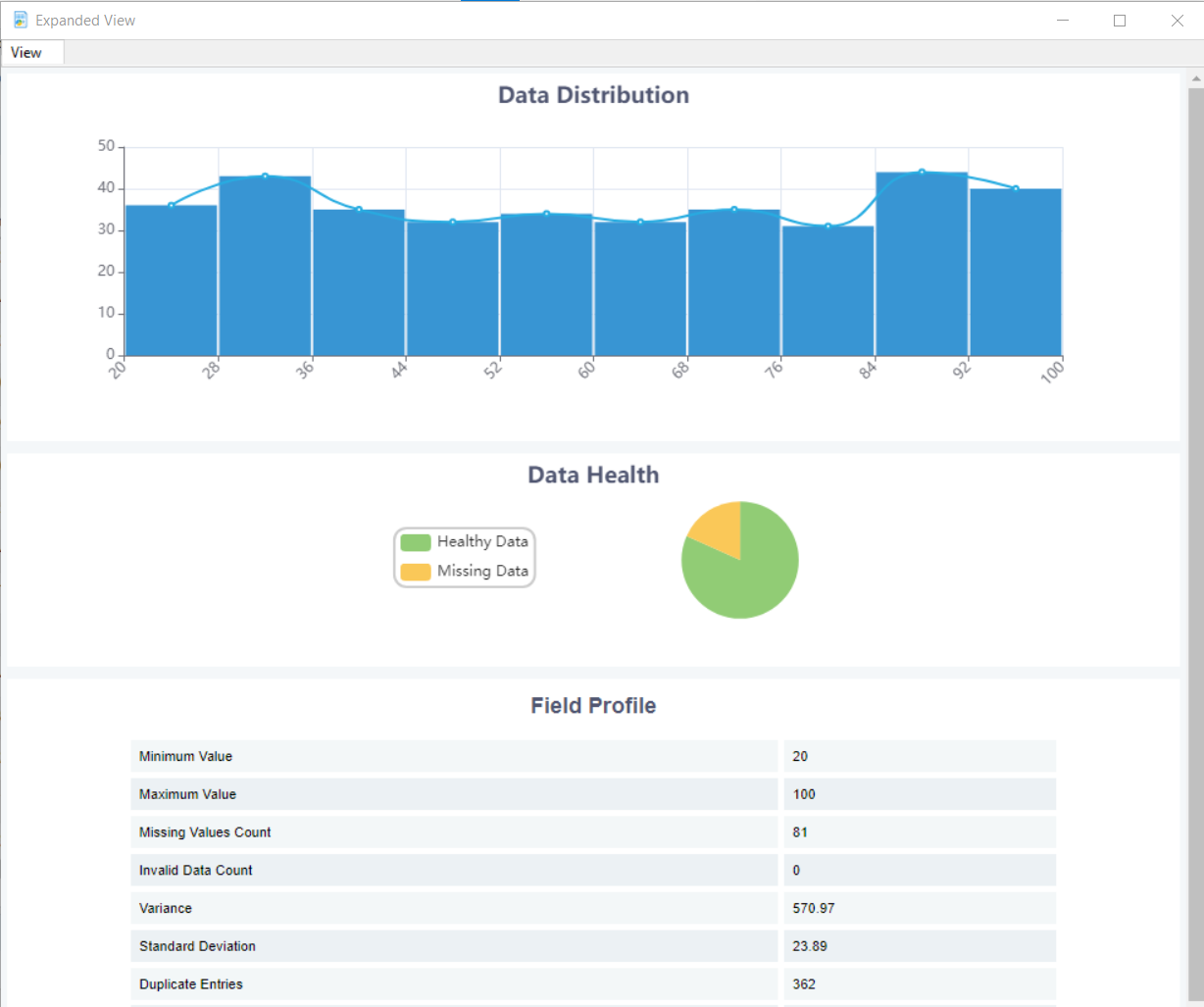
Step 6: Find Null or Missing Values
Missing or null values are a common problem in data. They occur in data for various reasons, such as errors in data collection or entry or privacy concerns. Missing values affect the quality and reliability of your analysis.
Data profiling will help you reveal the frequency of missing values in each field. Visualizations like heat maps or bar charts can help you study the extent of missing values in a dataset and their distribution across different variables. Doing so will help you find patterns and trends in the data and decide how to handle the missing values.

Step 7: Discover Duplicates
Duplicate data refers to rows of data that have identical or similar content. Such redundant data can affect the quality and reliability of your analysis, as well as your system’s storage space and performance. Therefore, data experts often remove duplicate records and keep only one instance of each unique record.
However, before deleting duplicate records, you must consider which instance to keep and which to discard. Sometimes, duplicate records may have subtle differences relevant to your analysis. If you have a dataset of customer orders, but some records have errors or missing information. In this case, you can use duplicate records to fill in the gaps or correct the mistakes.
 In other cases, you may need to merge duplicate records into a single record. For instance, when the customer has two accounts with different information, you may need to combine the information from both accounts into one record to avoid confusion and inconsistency.
In other cases, you may need to merge duplicate records into a single record. For instance, when the customer has two accounts with different information, you may need to combine the information from both accounts into one record to avoid confusion and inconsistency.
Step 8: Identify Inconsistencies
Datasets often have inconsistencies that can result in inaccurate analysis. These inconsistencies stem from a need for more explicit formatting or standards during data entry and collection. Validating your data for errors can help identify and flag such discrepancies.

Here are some of the most common discrepancies in data sets.
| Typos in all data fields | Inconsistencies in units of measurement |
| Variations in naming conventions | Fields with invalid phone numbers |
| Inconsistent use of abbreviations | Fields with unwanted characters |
| Invalid addresses | Fields with non-printable characters |
| Variations in formatting or data types | Fields with leading, trailing, and duplicate spaces |
Step 9: Highlight Outliers
Outliers are data points that are very different from the rest of the data. They result from various factors, such as measurement errors, data entry errors, or natural variations in data. Outliers can distort the overall results of statistical analysis, so it is essential to identify and potentially remove them.
A straightforward way to find outliers in a dataset is to plot the data on a graph, such as a scatter plot, and look for points far away from the main cluster. However, this method can be subjective and inaccurate.
A more reliable way is to use outlier calculator, which finds outliers by using the statistical z-score method, which tells how many standard deviations a data point is from the mean. A common rule is that a data point with a z-score more significant than 3 or less than -3 is an outlier.

That said, identifying outliers is seldom straightforward. Depending on the context and the purpose of the analysis, some outliers may be more relevant than others. The domain knowledge and the statistical methods used to define outliers can also affect the outcome. Therefore, it is essential to understand the nature and the source of the outliers before deciding how to handle them.
For instance, if you’re analyzing the income distribution in a town, you would collect a sample of 100 people and calculate their annual income. The research shows that most people earn between $15,000 and $120,000 annually, but two earn $1 million and $10 million annually. These people are outliers because they are very different from the rest of the sample.
However, they may not be errors or anomalies. They may represent a small but significant group of wealthy people in the country. If you remove them from the analysis, you may underestimate the income inequality in the country. On the other hand, if you keep them in the analysis, you may overestimate the average income in the country. Therefore, you need to consider your analysis’s context and goal before deciding how to deal with these outliers.
Step 10: Summarize and Display Your Data
After you have gathered your data, you need to summarize and display it using descriptive statistics and visualizations. These tools can help you better understand the relationships among variables in your data.

Imagine you have a dataset of customer transactions from an online store. Use descriptive statistics to calculate the average transaction amount, the range of transaction amounts, and the variability of transaction amounts.
You may also want to use visualizations to show how the transaction amounts are distributed, how they vary by customer age, and how other factors, such as product category or season, influence them. Summarizing and displaying your data can gain valuable insights into customers’ behavior and preferences.
Data Exploration in AI and ML
Data exploration is pivotal in artificial intelligence (AI) and machine learning (ML) since it helps make predictive models more accurate. A machine learning algorithm is as good as the data you feed it.
Exploring your data helps you understand how certain variables relate and interact with each other while analyzing their impact on the outcomes of predictive models.
For instance, understanding how these features are related in a dataset with variables like age, income, and education level will help you make ML models more accurate.
Data scientists often leverage data exploration to discern patterns, correlations, and outliers within large datasets. This process allows you to identify inaccuracies or irrelevant information and visualize it to illustrate complex relationships graphically.
Data exploration can also help you perform feature selection, which is the process of identifying the most relevant variables that contribute to the predictive power of a model.
Moreover, it can help you evaluate model performance by revealing underlying data structures that could affect predictions. Through iterative exploration, you can refine their models, enhance accuracy, and ensure robustness against overfitting.
Data Exploration Tools
The traditional manual approach to data exploration is labor-intensive and susceptible to human error. Data scientists have gravitated towards automated data exploration tools in response to these challenges. These sophisticated tools leverage algorithms and ML techniques to scrutinize data more precisely and efficiently. They can manage extensive datasets and unearth insights that might elude manual analysis.
Prominent data exploration tools like Astera have revolutionized the exploration process. Astera is an all-encompassing, no-code data management platform designed to streamline the entire data journey. From intricate extraction processes across diverse data landscapes to meticulous data preparation and integration, Astera provides the tools to transform raw data into actionable insights.
While Astera focuses on end-to-end data management, it also complements visualization tools like Power BI and Tableau for visualization and reporting. It ensures that data is clean and well-structured, crucial for creating compelling visualizations. You can use Astera to prepare data and then utilize Power BI or Tableau for detailed visual analysis. This combination allows for a comprehensive approach to data exploration, leading to more informed business decisions and strategies.
These tools expedite the data exploration process and enhance its accuracy. Automating repetitive tasks will allow you to focus on strategic analysis and decision-making. As the field of data science evolves, these tools will continue to play a crucial role in unlocking the full potential of data exploration.
Automating Data Exploration with Astera
Data exploration helps you unlock various insights within a dataset. However, the right tools make the process significantly more efficient and effective.
A data exploration tool equipped with a real-time, preview-centric design is the modern-day compass for navigating complex datasets. It streamlines the process by providing instant access to data previews, making it easier to comprehend the dataset’s structure, but it also helps monitor data integrity.
Astera DataPrep offers:
- Interactive Data Grid: Agile correction capabilities that allow for hands-on, immediate data cleansing and adjustments.
- Data Quality Assurance: Implement comprehensive checks and rules to maintain data accuracy and consistency.
- Rich Data Transformations: A wide array of transformations to shape and refine your data to meet analysis requirements.
- No-Code Interface: An intuitive point-and-click environment that democratizes data preparation, making it accessible to users of all skill levels.
- Connectors for Diverse Data Sources: Seamless integration with various on-premises and cloud-based sources, ensuring smooth data extraction and consolidation.
- Workflow Automation: Streamline the entire data preparation process, from integration to transformation, saving valuable time and resources.
Astera bridges the gap between raw data and actionable insights, facilitating quicker decision-making, predictive modeling, and ultimately better business outcomes.
Experience firsthand how Astera’s AI-powered data extraction and sophisticated data preparation can revolutionize your data pipelines. Join us for a live demo and start your journey toward seamless, automated, and insightful data management today!
Authors:
Fasih Khan


