Astera AI Agent Builder - First Look Coming Soon!
Astera AI Agent Builder - First Look Coming Soon!
The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

Data Ingestion vs. ETL: Understanding the Difference
Working with large volumes of data requires effective data management practices and tools, and two of the frequently used processes are data ingestion and ETL . Given the similarities between these two processes, non-technical people seek to understand what makes them different, often using search queries like “data ingestion vs ETL”.
Data ingestion focuses on the initial collection and import of data, preparing it for storage or future use. ETL, on the other hand, takes this process further by not only ingesting data but also transforming it. The transformation involves cleaning the data to remove inaccuracies or irrelevant information, structuring it into a predefined schema for easy querying, and adding valuable context before loading it into its destination, such as a data warehouse. Let’s have a closer look at data ingestion and ETL to understand how they are different and how they are often used together. This will help us understand their roles in a modern data pipeline architecture.
What is Data Ingestion?
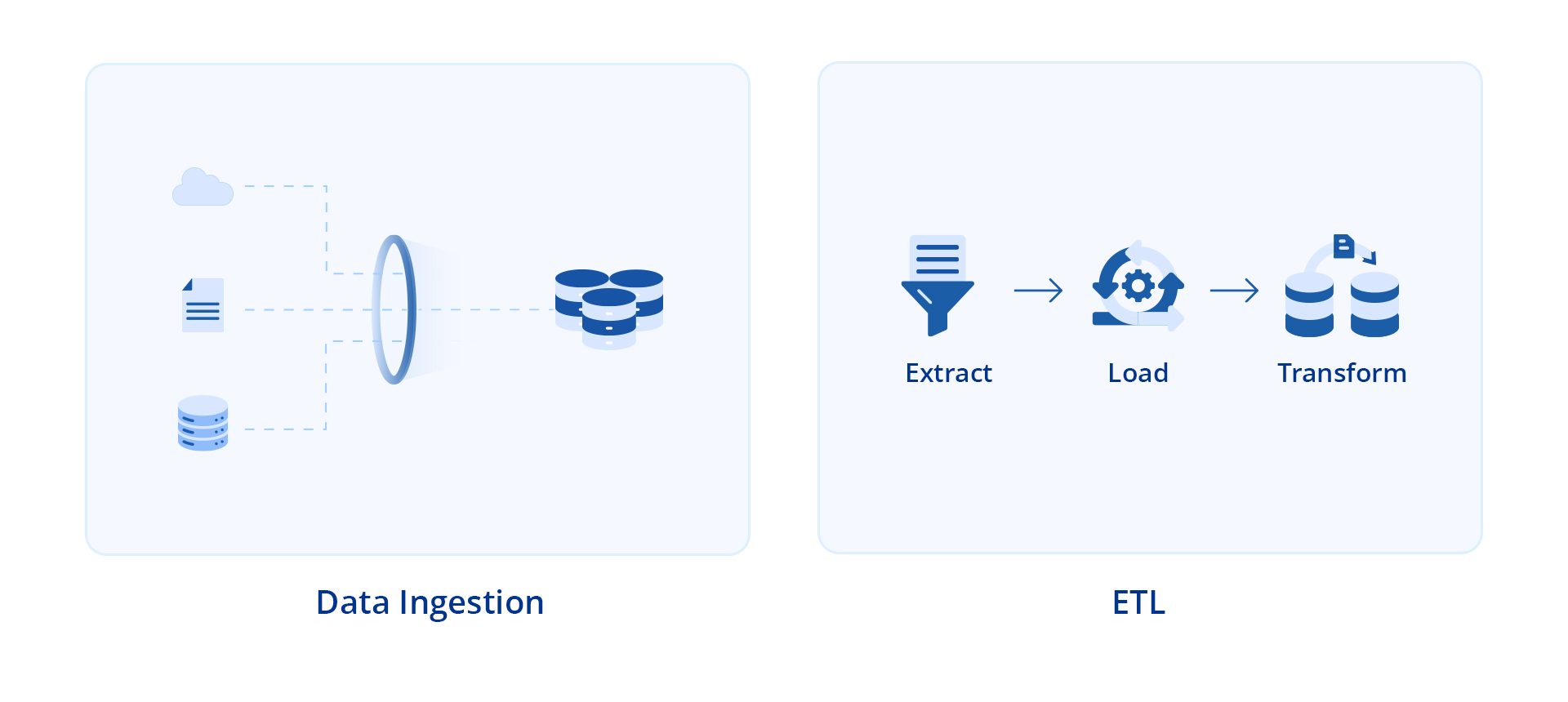
Data ingestion is the process of collecting, importing, and transferring data from different sources such as files, databases, and streaming platforms into a storage or processing system It’s an initial step in a data pipeline, where raw data from sources such as files, streams, APIs, or databases is acquired and prepared for further analysis and storage.
For instance, data ingestion for a retail company would involve collecting sales data from sources like mobile apps, e-commerce platforms, and customer feedback forms that would include product information, customer profiles, transaction records, and inventory updates. The data ingestion process would then involve extracting data from each source and loading it into a centralized data repository.
There are two types of data ingestion techniques:
Batch data ingestion: It involves collecting and moving data at regular intervals.
Streaming data ingestion: This includes collecting data and loading it into the target repository in real time. is
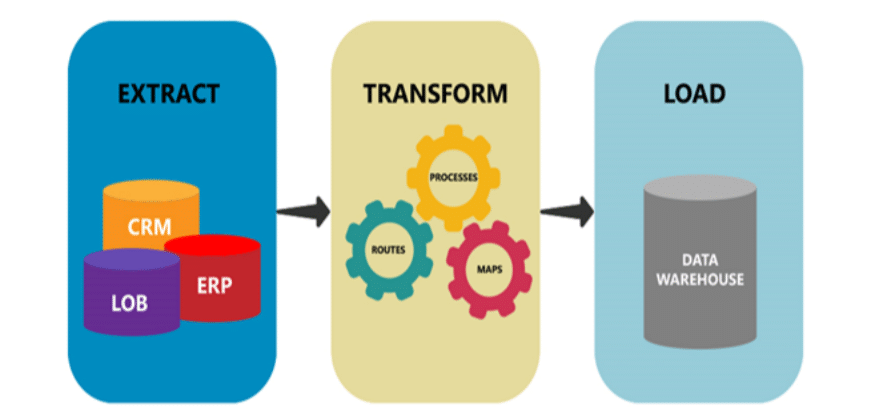
What is ETL?
Extract, transform, and load (ETL) is a type of data integration process that was standardized in the 1970s. It involves extracting data from multiple sources, transforming it into a consistent format, and finally, loading it into the target system, which is typically a database, a data warehouse, or a data lake. Data extraction involves retrieving data from different source systems such as APIs, files, databases, or streams. This step requires querying databases or reading files to gather the essential information.
Data transformation involves converting the extracted data into a format suitable for analysis and reporting. Some common transformation operations include normalization, data cleansing, aggregation, and enrichment.
Finally, loading involves moving the transformed data into the target system for reporting or BI analysis. More recently, cloud computing has made it possible to flip the final two stages of ETL so that it works in the sequence Extract, Load, and Transform (ELT).
However, the primary objective remains the same: integrate data from different sources, organize it into a standardized format or structure, and finally prepare it for analysis and decision-making.
Data Ingestion vs. ETL: Differences
Both these processes help improve the data knowledge of an organization as they change the data to the right format. Moreover, ETL and data ingestion both involve considerations for data quality. ETL emphasizes deduplication, data cleansing, and validation to ensure consistency and accuracy. Similarly, data ingestion focuses on acquiring raw data reliably.
Despite all the similarities, data ingestion and ETL have some clear differences. For starters, the goal with ETL is to extract, transform, and load data into the target repository in a consistent format to maintain data quality and integrity. On the other hand, data ingestion aims to gather and import raw data from different sources into a centralized repository for further analysis and processing.
Here are some more differences between data ingestion and ETL:
- Data ingestion precedes ETL in the data processing pipeline and serves as the initial step in aggregating raw data. ETL comes later and aims to prepare data for analysis and reporting.
- ETL involves data transformation, cleansing, and integration activities, while data ingestion involves data movement.
- The aim of data ingestion is to collect raw data, which might still have many quality issues. However, ETL always cleans the information and changes it into the right format before loading it into the target system.
- Data ingestion processes almost always trigger processes in other systems, while ETL pipelines end right after loading data into the target system.
- Data ingestion supports both batch and real-time processing, while ETL usually moves data in batches on a regular schedule.
Key Considerations for Choosing Between Data Ingestion and ETL
Real-time data requirements: Data ingestion is ideal in this case as it facilitates real-time or near-real time processing better. It allows us to ingest and analyze data streams as they arrive. This proves beneficial in decision making.
Batch processing cases: ETL is more suited to batch processing cases where data is collected and processed in batches. This easily helps manage large volumes of data efficiently as it applies transformations and loading data into the target systems at scheduled intervals.
Structured data requirements: ETL can easily extract both structured and unstructured data from multiple sources. Hence, it can be used when there’s a need to extract, transform, and load data from structured sources like relational databases.
Predictable data processing: The characteristics like scalability and cost-effectiveness make ETL an ideal choice for predictable data processing tasks. Organizations can schedule ETL jobs during off-peak hours when the system loads are low. This reduces operational costs and optimizes resource utilization.
Compatible source and target system: When source and target systems are compatible and require little to no transformation, data ingestion is the way to go. Data ingestion allows companies to ingest the data directly into the target system without manipulation of any kind.
Data ingestion or ETL? Both!
With the ongoing debate on data ingestion vs ETL, it is essential to understand that it’s not about choosing one over the other. Instead, both play a key role in the data lifecycle and complement each other for seamless data flow and processing.
Here’s why choosing both data ingestion and ETL is a wise approach:
Data ingestion ensures that every piece of data, no matter its source, is captured. This inclusiveness is needed because organizations rely on a wide variety of data types and sources to inform their decisions. While data ingestion gathers the data, ETL transforms this raw data into a format that’s ready for analysis. Without ETL, the data might remain in a state that’s difficult or impossible to analyze effectively. It ensures data accuracy and reliability by standardizing formats and cleaning up any inconsistencies.
To sum up, data ingestion helps kickstart the data integration and management process by capturing raw information. ETL further transforms this data into valuable information. Together, they enable organizations to carry out strategic planning and make informed decisions.
Benefits of Data Ingestion and ETL

Data ingestion and ETL provide several benefits for businesses, enabling them to effectively handle and utilize their data. Some of the key benefits include;
- Real-time Analytics: Data ingestion and ETL (streaming) support real-time processing. This means businesses can process and analyze data as it arrives, thus facilitating timely responses to events. Ingesting and processing data continuously helps organizations to respond promptly to changing business conditions.
- Scalability and flexibility: Data ingestion and ETL make it easier for organizations to scale data processing and storage by enabling them to handle massive amounts of data from diverse sources efficiently. Using parallel processing and optimization techniques, companies can accelerate data processing and ingestion workflows.
- Maintains data integrity and data quality assurance: Apart from collecting data, ETL and data ingestion processes also include mechanisms that ensure data quality and integrity. This can include data cleansing, validation, deduplication, and error handling. Considering these, it’s easier to prevent issues and improve the overall reliability of the data analytics and reporting.
- Cost Efficiency: Operational costs associated with data management can be reduced using specialized ETL tools and data ingestion tools. These tools automate the data ingestion and ETL processes, which eliminates the need for manual intervention. Consequently, companies can achieve cost efficiency while maintaining high data quality standards.
- Support for Advanced Analytics: ETL and data ingestion allow the integration of advanced technologies like predictive modeling, machine learning, and data mining as they prepare and organize the data, providing the necessary groundwork. Organizations can retrieve information about valuable patterns and correlations and drive actionable insights.
Data Ingestion Use Cases
Data ingestion is important in acquiring and moving data into a system for initial processing or storage. Here are some use cases where data ingestion is specifically applicable.
IoT Data Management: Data ingestion is the foundational step in managing data from Internet of Things (IoT) devices. It collects, processes, and stores the large amount of data generated by these devices. Data ingestion allows the organizations to capture data from different sources in real-time or near real-time. Moreover, data digestion makes it possible to integrate the IoT data into existing data processing pipelines, cloud-based platforms, and data lakes.
Customer Data Onboarding: Data ingestion integrates external customer data sources into the data infrastructure of an organization. The customer information is incorporated from different channels, including third-party vendors, marketing databases, etc. This efficient data collection allows organizations to ingest large amounts of customer data in real-time or batch processes. Ingesting data in a centralized repository helps an organization in targeted advertising campaigns and marketing initiatives.
Log File Analysis: Log-based ingestion is common in performance analysis and security monitoring. Data is ingested from log files generated by systems, applications, or devices that include valuable information about user interactions and system performance. Ingesting log data enables organizations to proactive detection and response to threats.
Financial Market Data Processing: Information like currency exchange rates, market indices, stock prices, and trading volumes prove essential in market analysis and risk management. Therefore, its essential to get such information from different sources into a centralized data repository. Ingesting financial market data helps an organization perform various analytical and quantitative tasks including algorithmic trading, modeling, and risk assessment.
ETL Use Cases
ETL processes are used in various industries for integrating data from multiple sources. Here are some common use cases of ETL:
Automating Manual Workflows
ETL, when implemented through ETL tools can be used to automate manual workflows. By using ETL tools organizations can design automation logic, monitor operations for continuous optimization and schedule data processing. This helps organizations to enhance efficiency, streamline operations, and reduce manual intervention in data-related tasks.
Data Warehousing
ETL is preferred for data warehousing as it has comprehensive data processing capabilities. It ensures quality and usability within the warehouse through quality assurance, integration of multiple sources, and management of historical data. Providing these functionalities, ETL makes sure the data in the warehouse is reliable and optimized
Streamlining Data Migration
Data migration can be streamlined using ETL, particularly when transferring from an on-premises system to the cloud. It begins by pulling both structured and unstructured data from a source system, then cleans and filters it, and finally loads the cleaned data into the target database.
ETL helps companies move large amounts of data while ensuring proper organization and ease of use in the target system.
Conclusion
While different processes, organizations use data ingestion and ETL together to take full advantage of their data assets. Data ingestion facilitates the collection and storage of raw data from diverse sources, while ETL processes are needed to transform and load this data into structured repositories for analysis, reporting, and decision-making.
Whether you need to ingest data from multiple sources or ETL it into your data warehouse for analysis and decision-making, you need a modern, no-code data integration solution to simplify and automate the process. This is where Astera comes into the picture with its Data Pipeline Builder.
Astera Data Pipeline Builder enables you to build fully automated data pipelines to ingest data and execute ETL workflows without writing a single line of code.
Streamline company-wide data integration with many native connectors, embedded data quality and governance features, built-in transformations, parallel processing ETL engine, and an intuitive UI.
Build ETL pipelines and ingest data in a 100% no-code environment
Astera empowers users to integrate enterprise data by building reliable data pipelines without writing a single line of code. Download a 14-day free trial or reach out to us to discuss your use case.
Start you 14-day trial now!
Authors:
Aisha Shahid