 NEW RELEASE ALERT
NEW RELEASE ALERT
 March 27th, 2025
March 27th, 2025 

The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

What is a Data Lake? Definition and Benefits
Around 80% to 90% of the data that is produced is unstructured, i.e., it is not organized and lacks a predefined format. What does this mean for businesses? It’s a signal, loud and clear, that it’s time to embrace a data lake that can house all this data and provide them with a single source of truth they need for their business intelligence (BI) initiatives.
What Is a Data Lake?
In the world of technology, a data lake is a term we use to describe a large, centralized storage repository that organizations use to store vast amounts of raw, unstructured, and semi-structured data.
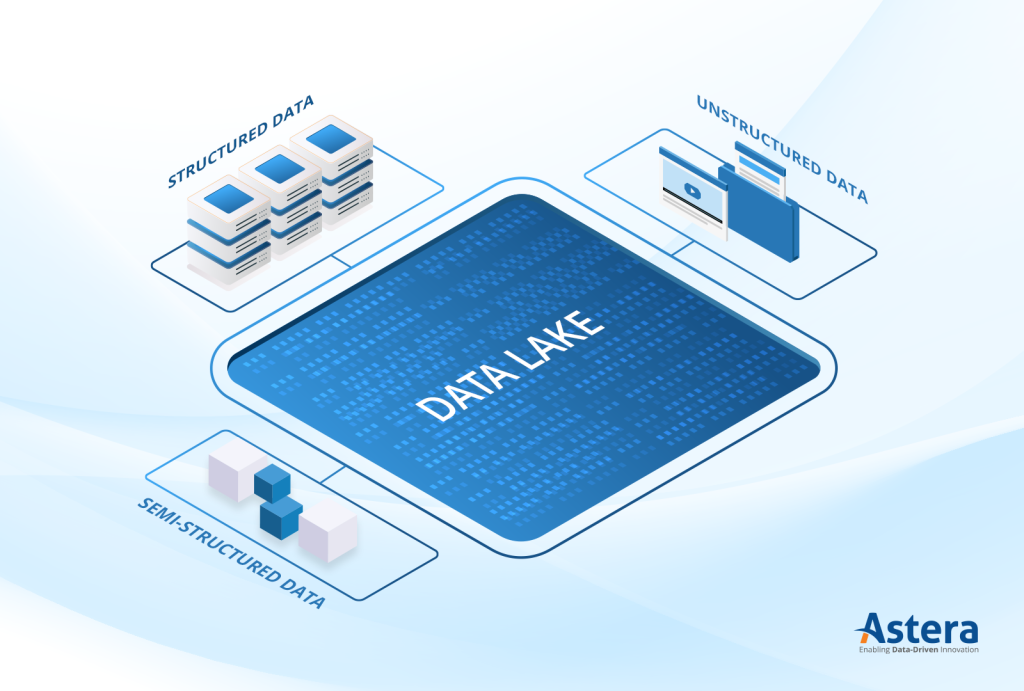
Data lakes are capable of storing structured, semi-structured, and unstructured data.
You can think of it as a giant reservoir of information, where data from different sources such as social media, web applications, and IoT devices is stored in its raw form without any predefined structure or format. This includes all kinds of data, including text, image, audio, and video.
Like skilled fishermen, business and data professionals can cast their nets into the data lake and reel in the insights they need to drive business decisions. However, like all fishing trips, this demands careful planning to ensure data quality management, security, and regulatory compliance.
Data Lake vs Data Warehouse: What’s the difference?
A data warehouse is a large repository that organizations use to store and manage their data. These are designed to store structured data – data that is organized in tables and columns.
As opposed to a data lake which is an unstructured repository, you can think of a data warehouse as a well-organized library where all the books are placed neatly on their shelves. You know exactly where to go to get the book you need. Similarly, data warehouses streamline the process of retrieving and analyzing the data you need because the data is structured.
Data warehouses are commonly used for business intelligence and reporting, as they enable organizations to extract insights and make informed decisions based on their data.
While organizations use both a data lake and a data warehouse as a centralized data repository, they both have very different applications. The table below summarizes data lake vs data warehouse:
| Data Lake | Data Warehouse |
| Stores and handles structured, semi-structured, and unstructured data | Stores and handles structured data only |
| Does not require a predefined schema | Requires a predefined schema |
| Data is stored in its native format | Data is transformed and cleaned |
| Flexible and scalable | More rigid and less scalable |
| Used for big data analytics | Used for business intelligence and reporting |
| Requires more advanced technical skills to manage | Easier to manage and use |
| Enables users to store and analyze vast amounts of data | Enables users to access and analyze a specific set of data |
Benefits of Using a Data Lake
Data lakes are highly flexible and scalable, making them an ideal solution for organizations that need to store and analyze massive amounts of data quickly and efficiently. Here are some more reasons why organizations use data lakes:
Incredibly Scalable
Data lakes, like Azure Data Lake, are highly scalable, enabling organizations to handle enormous amounts of raw data with ease. They allow you to easily accommodate additional data as your data needs grow.
Highly Flexible
Unlike traditional data warehouses, data lakes are designed to store both structured and unstructured data sets in their native format. You can easily integrate different types of data sources and run more complex analytics on the data stored in your data lake.
Cost-Effective
Generally, data lakes are a cheaper solution compared to traditional data warehouses because you don’t need to transform and clean your data before loading it. This means that you can store more data at a lower cost, which is especially useful if you need to store large amounts of data.
Better Data Analysis
You can run more advanced analytics on data stored in a data lake, including machine learning and predictive modeling. This is because data lakes allow you to store data in its raw form, which provides more granular insights into your data.
Data Democratization
Data lakes enable everyone within an organization to access and use the data they need, regardless of their technical expertise. This streamlines company-wide data sharing and promotes data democratization, helping organizations make more informed decisions.
Loading Data Into a Data Lake
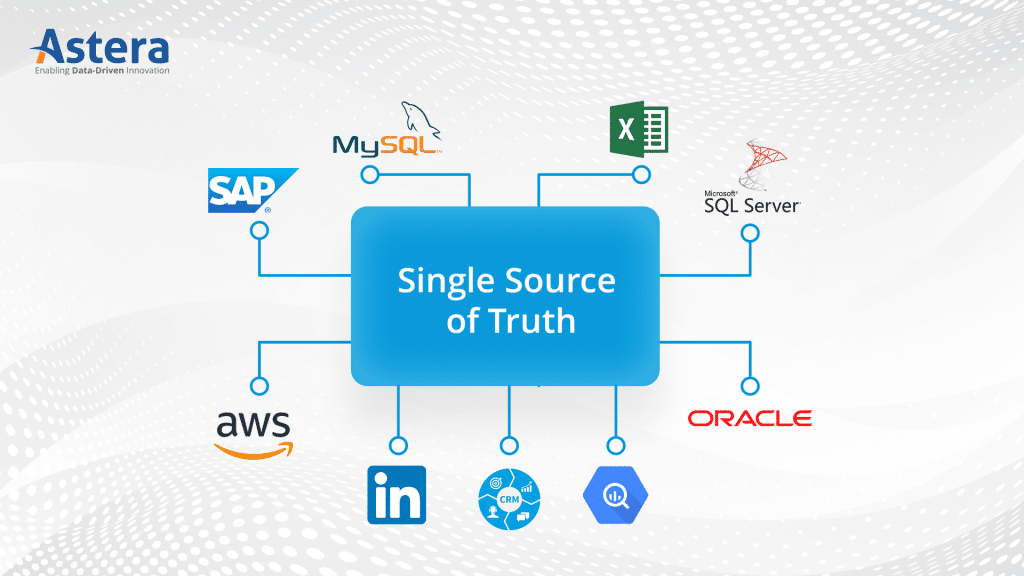
Combine data from multiple sources into your data lake and build a single source of truth.
Consolidating data into a data lake means bringing together large amounts of data from different data sources and dumping it into a centralized location. Developers build data pipelines to achieve this. The overall goal is to streamline the process of accessing and analyzing company-wide data.
However, given the number of complexities involved, this can be a tedious and resource-intensive process that requires significant planning and technical expertise, especially since the entire process is carried out manually by writing code.
As your organization grows, so does the number of your data sources and, consequently, the amount of data you work with. Every time a new data source is added, your team of developers will need to write code to connect to it and extract the data.
So how can you simplify and accelerate the process of consolidating your data into a data lake? Hint: No-code data integration.
Consolidating Data Using No-Code Data Integration
No-code data integration platforms, like Astera Centerprise, enable organizations to consolidate data from multiple sources into a data lake. These platforms provide an intuitive, drag-and-drop interface that empowers non-technical users to easily build data pipelines, eliminating the need to hire expensive developers.
Additionally, these data management platforms have a built-in library of native connectors that simplify and accelerate the process of connecting to and extracting data from multiple data sources, including file formats, data warehouses, databases, cloud applications, and APIs.
Then, depending on your business use-case for using a data lake, you can:
- Either transform the data before loading it into your data lake,
- Or, load the data first and transform it when needed.
If you need to transform your data before loading it into your data lake, you will have to use ETL (extract, transform, load). You can use easily do so with modern data integration tools as they offer a vast range of built-in transformations. Otherwise, you can use Pushdown Optimization (ELT) to extract the data first, load it into your data lake, and then transform it later.
You might be asking yourself, “why should I use a data lake if I have to transform the data before loading it?” While it’s not commonplace to use a data lake for structured data, there are some business use cases that warrant it. For example, your business requires you to conduct an analysis that requires combining relational data with non-relational data, or there is a need to accelerate data ingestion and have data redundancy, etc.
How Astera Centerprise Can Help
Astera Centerprise is a modern data integration platform that you can use to easily streamline the process of combining data from different sources and loading it into a data lake. With Astera Centerprise, you can:
- Quickly consolidate data into a centralized repository
- Eliminate the need for manual data processing
- Leverage built-in connectors to combine data from multiple sources
- Improve data quality using embedded data quality features
- Automate several aspects of your data integration tasks
Looking to accelerate the process of creating a single source of truth? Astera Centerprise can help. Sign up for a demo or download a 14-day free trial. You can also get in touch with one of our data integration experts at +1-888-77-ASTERA.
Authors:
Khurram Haider



