 Astera AI Agent Builder - First Look Coming Soon!
Astera AI Agent Builder - First Look Coming Soon! Apr 29th | 11 AM PT
Apr 29th | 11 AM PT
- What is Data Validation?
- Why Data Validation Can’t be Overlooked
- Benefits of Data Validation
- Types of Data Validation
- Issues Affecting Data Validation
- Data Validation Methods
- Common Data Validation Challenges
- The Importance of Automation in Data Validation
- Best Practices for Data Validation
- Data Validation in Action
- Simplify Data Validation with Astera Data Pipeline Builder

The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

What is Data Validation?
In 1998, NASA launched The Mars Climate Orbiter, built at a cost of $125 million to study the Martian climate. After 10 months of activity, the space probe burned and broke into pieces because of a small mistake in the metric system.
The navigation group at the Jet Propulsion Laboratory (JPL) used the metric measurements of millimeters and meters for their computations while Lockheed Martin Astronautics in Denver, the entity responsible for crafting and constructing the spacecraft, supplied essential acceleration data using the imperial system of inches, feet, and pounds.
This mistake could have been easily avoided if the data was validated before it was used. The example shows the importance of data validation and what consequences it could have, especially today when the entire world relies heavily on data.
What is Data Validation?
In simple terms, data validation is rechecking your data for accuracy, missing values, anomalies, and discrepancies during the data integration process before it can be used for decision-making. Essentially, it’s like giving your data a thorough health check. Data validation ensures that the data you’re using is trustworthy and suitable for your analysis.
The main purpose behind data validation is to check that it is meant for the intended use. For example, you are making a marketing campaign to target teenagers and your marketing campaign is based on the survey results you gathered. However, after you made your campaign, you realize that the data you collected was not of teenagers but people in their mid-twenties. So, your data would have been accurate, but it might not have been valid.
Why Data Validation Can’t be Overlooked
In 2018, a staff member at Samsung Securities in South Korea made a huge mistake by confusing the currency (won) with company shares. Instead of paying out dividends of 1,000 won per share, the employee accidentally granted 1,000 Samsung Securities shares to employees. This blunder led to a massive financial loss for the company, amounting to $300 million.
Any organization is susceptible to similar mistakes if they lack protocols to safeguard themselves. In the instance of Samsung Securities, implementing an assurance process that involved automatic data validation could have prevented the error.
This is just one example of the crucial role data validation plays in data management. It does not only play a crucial role in saving time and cost for an organization, rather it is also pivotal in maintaining compliance, specifically for healthcare and financial industries.
It is not just a matter of caution; it’s an imperative for any organization that values accuracy, efficiency, and risk mitigation, whether it’s financial institutions, healthcare providers, or technology companies.
Benefits of Data Validation
Data validation checks the collected data’s quality and accuracy before analyzing and processing it. It verifies that all of your information is present and correct. Validating data, however, is a time-consuming process that can severely delay analysis. So, the question arises: is data validation worth the delay?
Let’s look at some of the most important benefits of data validation.

Improves the Efficiency of Data
Data validation ensures that datasets are accurate and complete before analysis, leading to error-free data which is needed for future research or machine learning model training, ultimately saving time and resources.
But the value of data validation goes beyond just improving the efficiency of data analysis. For businesses, reliable data is necessary to make well-informed decisions that will lead to growth and increased profit. Having accurate information means companies can make decisions based on accurate insights and trends, resulting in better outcomes.
Not only does data validation save time and resources, but it can even help avoid mistakes caused by incorrect data. By identifying inaccuracies early on, businesses can prevent errors from worsening and make crucial changes before it’s too late.
Reveals New Data Insights
Data validation helps businesses discover hidden patterns and relationships in their data that may have previously gone unnoticed. This can give them a more comprehensive understanding of their operations and the factors that drive their success. With this knowledge, businesses can make better decisions to generate growth and profitability.
For instance, data validation might show correlations between customer demographics and buying habits that weren’t previously known. This information can help businesses customize their products and services to meet the needs of their target market better, resulting in greater customer satisfaction and retention.
Identifies Inaccuracies
Accurate data is essential for businesses to make informed decisions, but it can be difficult to attain without data validation. Data validation helps identify and fix inaccuracies in the data, so that business decisions are based on reliable evidence. That way, costly mistakes are avoided and businesses can operate with greater efficiency, lower risk, and improved profitability.
Take sales data as an example: Data validation can detect duplicates or missing entries, allowing businesses to better understand their sales performance and make decisions that lead to growth.
Enhances Customer Satisfaction
By using accurate and reliable data, businesses can provide better products and services, ultimately leading to greater customer satisfaction. When businesses make decisions based on accurate and reliable data, they can better understand their customers’ needs and preferences and provide products and services that meet them. This leads to increased customer loyalty and repeat business.
Types of Data Validation
Data storage standards vary per company. Basic data validation procedures can assist your business in keeping data organized and efficient. Before storing data in the database, most data validation methods execute one or more of these checks. Here are the common validation types:
Data Type Check
A Data Type check verifies that the data put into a field is of the appropriate data type. A field may only take numbers. The system should reject data with letters or special symbols and provide an error message.
Code Check
Code Checks guarantee that fields are selected from legitimate lists or that formatting standards are met. Comparing a postal code to a list of valid codes simplifies verification. Moreover, NAICS industry codes and country codes can be treated similarly.
Range Check
Range checks assess if input data fits a range. For example, geographic data uses latitude and longitude and longitude should be -180 and latitude 90. Outside this range are invalid.
Format Check
Several data types are formatted. Format Checks verify data format. Date fields are recorded like “YYYY-MM-DD” or “DD-MM-YYYY.” As a result, any other form will be refused. A National Insurance number is LL 99 99 99 L, where L is any letter, and 9 is any number.
Consistency Check
Consistency Checks ensure data is entered appropriately. Monitoring a parcel’s delivery date after shipping is one example.
Uniqueness Check
Information like IDs and email addresses are guaranteed to be one-of-a-kind. These database fields should contain unique entries. Uniqueness Checks prevent duplicates in databases.
Presence Check
Presence Checks prevent essential fields from being blank. If the field is blank, an error notice will appear, and the user cannot progress or save their input. Most databases prohibit blank key fields.
Length Check
Length Checks guarantee the field has the correct number of characters. Therefore, it checks the character string’s length. Consider requiring a password of at least eight characters. Length Check verifies the field has eight characters.
Look Up
Look Up reduces mistakes in limited-value fields. A table determines acceptable values. The list of potential values is limited since, for instance, there are only seven days a week.
Issues Affecting Data Validation
To ensure data validation, it is important to understand the pillars of data validation. Here are some of the factors that you need to check:
- Format: It is important to ensure that data is in a consistent format. Format mistakes usually happen with dates. Some places use the format dd/mm/yy, while others may use mm/dd/yy.
- Range: Data ranges should fall within a reasonable range. For example, it is important to check that temperatures are within a certain limit or that ages are within a logical range.
- Completeness: Let’s say you got a survey done and many applicants didn’t fill in their email addresses or those email addresses and phone numbers were incomplete. So, you need to check your data for completeness as well. A survey conducted by Convertr, a customer acquisition platform, deduced that 1 in 4 leads that undergo processing are categorized as invalid because 27 percent have fake names, 28 percent have an invalid email address, and 30 percent have incorrect phone numbers.
Additionally, utilizing a people search API can provide more information about an individual, such as their phone number, home address, email address, place of employment, website, etc. - Consistency: Your data must be consistent across different parts of a dataset or between different datasets. For example, you need to ensure that customer names are spelled the same way throughout.
- Referential Integrity: Referential integrity ensures that relationships between data in different tables or databases are maintained and that there are no references to missing or non-existent data.
- Uniqueness: In a dataset, uniqueness indicates that each piece of data is different from all others, and there are no repetitions or duplicates of the same value. Uniqueness is often crucial when using data as identifiers or keys in databases, especially when linking different pieces of information or ensuring reliable data relationships.
- Attribute dependency: The inaccuracy caused due to the value of a field depending on another field. For instance, the accuracy of product data is dependent on the information related to suppliers. Therefore, errors in supplier data will reflect in product data as well.
- Invalid values: In case the datasets have known values, such as ‘M’ for male and ‘F’ for female, then change in these values can render data invalid
- Missing values: Presence of null or blank values in the dataset.
- Duplication: Repetition of data is a common occurrence in organizations where data is collected from multiple channels in several stages.
- Misspellings: Incorrect spellings
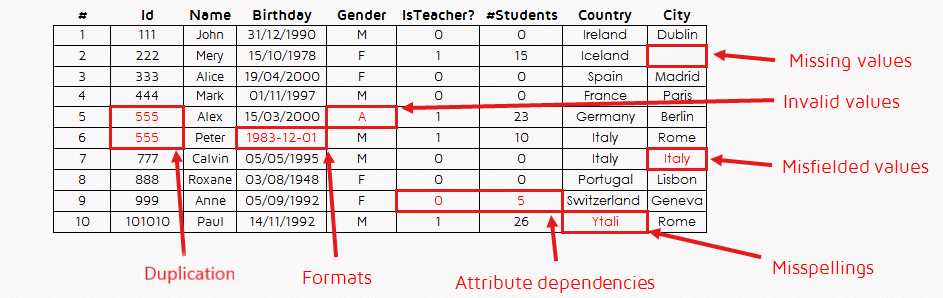
Factors leading to invalid data (source: QuantDare)
Data Validation Methods
You may validate data by using one of three ways:
Scripting
Data validation is often conducted by developing scripts in a scripting language like Python. For example, you may build an XML file with the target and source database names, column names, and tables for comparison.
The Python script may read the XML and evaluate the results. Nevertheless, this may be time-consuming because the scripts must be written, and the findings must be manually verified.
Enterprise tools
Data validation is possible with enterprise data validation tools. Astera Data Pipeline Builder, for example, may validate and fix data. Data integration tools are more reliable and a safer option as they are feature packed.
Open-source tools
Cloud-based open-source tools are affordable and can reduce infrastructure costs. Nonetheless, they still require expertise and manual coding for optimal use. Open-source tools include SourceForge and OpenRefine.
Common Data Validation Challenges
Given the importance of data validation, it only makes sense that it should be an essential part of every organization, and it must be. Then why do mistakes still happen and especially in organizations such as NASA and Samsung that cannot afford to overlook data validation.
One of the reasons the mistakes still occur is because data validation is not as easy as it seems, especially in today’s context when data volume and variety have increased significantly. Here are some of the common challenges you can anticipate while implementing data validation:
- Multiple Sources: One of the biggest challenges of ensuring data validity is the plethora of sources. Today, data comes in from social media, POS systems, sensors, website and combining this data accurately requires robust data quality management.
- Changing Data: Data can change over time due to updates, deletions, or modifications. Implementing version control and audit trails helps track changes while maintaining data validation.
- Unstructured Data: Today, 80% of the data is unstructured that is it comes in the form of such as text or images. It involves using advanced techniques like natural language processing or image recognition to extract meaningful information for validation.
- Data Privacy and Security: Data validation is important but so is data privacy. Let’s say you are working with identification numbers or credit card numbers, and you need to validate them. When dealing with such datasets, maintaining privacy can be a tad bit challenging
- Legacy Systems: Many businesses still use legacy systems that is on prem databases. Integrating validation into older systems can be complex due to compatibility issues.
- Cross-System Validation: Data moving across various systems requires validation at each step to ensure consistent, accurate information flow.
The Importance of Automation in Data Validation
Modern challenges require modern solutions and hence the only way to mitigate these challenges associated with data validation is to adopt a data validation tool. A data validation tool is designed to handle increasing data volumes without sacrificing accuracy or efficiency. Automation is the cornerstone of these tools. It streamlines repetitive tasks, reduces the risk of human error, and expedites the validation process.
A data management tool, such as Astera Data Pipeline Builder, supports data validation through built-in data profiling, data quality rules, and data cleanse transformations. You can use the tool’s out-of-the-box connectors in a graphical UI to integrate, transform, and validate data from multiple sources.
Best Practices for Data Validation
1. Define Clear Validation Rules
Set explicit rules for data formats, ranges, and required fields. Ensure validation rules align with business logic to maintain consistency across datasets.
2. Implement Multi-Level Validation
Use a layered approach—validate data at the point of entry, during processing, and before storage. Combining client-side and server-side validation prevents errors from slipping through.
3. Automate Data Validation
Leverage automated validation tools to reduce manual effort and minimize human errors. Tools like Astera’s data validation capabilities streamline the process for large datasets.
4. Maintain Comprehensive Error Logs
Keep detailed logs of validation failures to diagnose recurring issues. Clear error messages help users quickly identify and fix incorrect entries.
5. Validate Against External Data Sources
Cross-check data with external systems or reference databases to ensure accuracy. For example, validating addresses against postal databases can prevent incorrect entries.
6. Use Check Constraints and Referential Integrity
Enforce constraints at the database level to prevent invalid data entry. Using foreign keys and unique constraints helps maintain relational data integrity.
7. Incorporate Statistical and Anomaly Detection
Use statistical methods or AI-driven anomaly detection to flag outliers or inconsistencies that may not be caught by rule-based validation alone.
8. Conduct Regular Data Audits
Schedule periodic reviews to identify validation gaps and refine rules based on evolving data trends. Continuous improvement ensures long-term data quality.
9. Ensure User-Friendly Error Handling
Provide actionable error messages that guide users toward correct input rather than just rejecting entries. A smooth user experience encourages better data quality.
10. Balance Performance and Rigor
Overly complex validation can slow down systems. Optimize validation rules to maintain a balance between thoroughness and processing efficiency.
Data Validation in Action
Let’s consider a simple scenario where a company ABC consolidates their customer data in an Excel file to streamline their marketing efforts and revenue channels. However, the data they gathered had several errors. Therefore, they decide to validate their data using Astera Data Pipeline Builder.
Fig. 2 shows the dataflow that takes an Excel source as input, profiles it for analyzing source data, cleanses it to remove invalid records, and applies data quality rules to identify errors in the cleansed data before writing it into the destination delimited file.
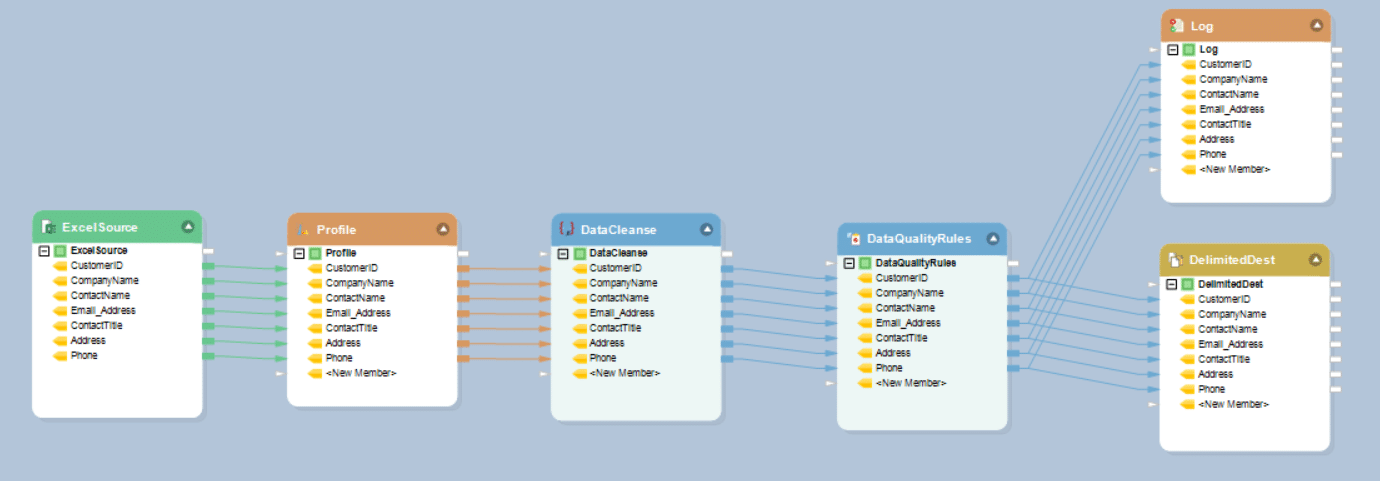
Fig.2: A simple dataflow for explaining data validation from Excel source
The result of the Data Profile transformation shows the field-level details of data. This enables the organization to understand the data and ensure:
- The credibility of data: Once the data has been analyzed, anomalies and duplications can be eliminated to ensure the reliability of data. This further helps the organization identify quality issues and determine actionable information to streamline business processes.
- Faster decision-making: It creates an accurate picture of the source data, enabling the organization to reach decisions faster.
- Hands-on crisis management: Profiled data can prevent small mistakes from turning into critical issues.
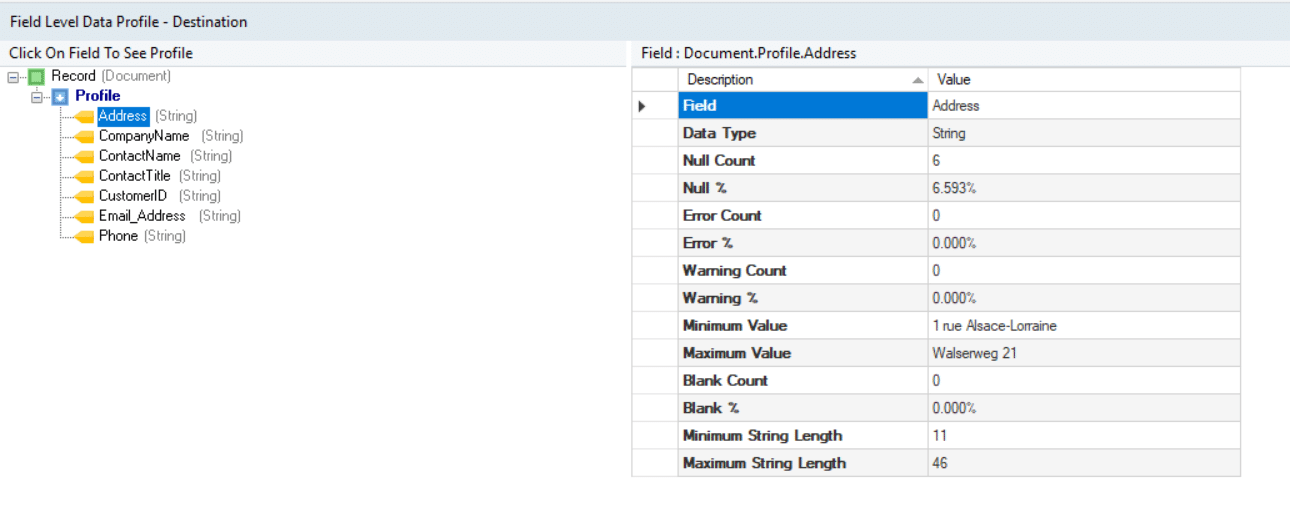
Fig. 3: Profiling source data
The Data Cleanse transformation is used to fix two issues in the source data:
- It removes trailing and leading spaces from the records.
- It identifies records containing ‘.co’ and replaces it with ‘.com’. This fixes erroneous records in the Email Address.
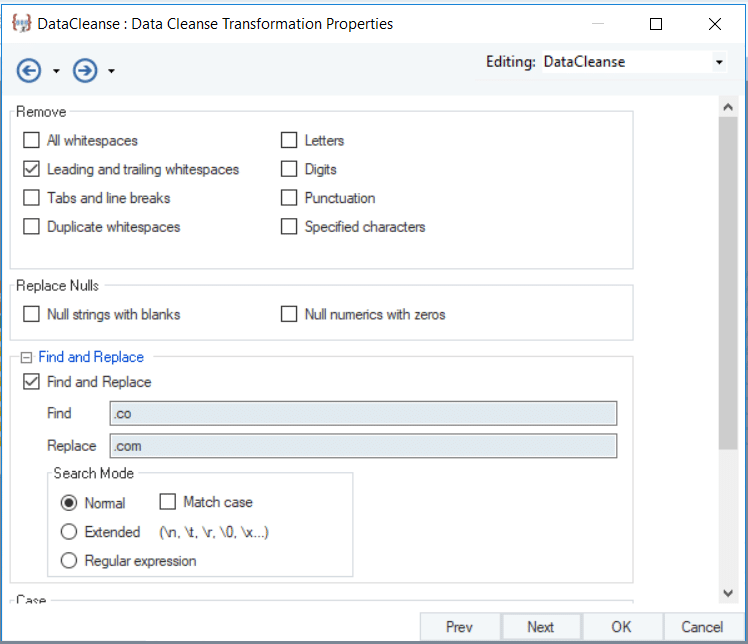
Fig.4: Applying conditions to cleanse data
The cleansed data, after removing extra spaces and incorrect email address format, can be seen in the right half of Fig. 5.
Using this clean data, the organization can:
- Improve email marketing efforts: By creating a clean and error-free version of its customer data, the organization ensures the data can be utilized to get maximum returns on email marketing.
- Increase revenue: Using correct email addresses guarantees higher response rates, which in turn results in increased conversions and chances of sales.
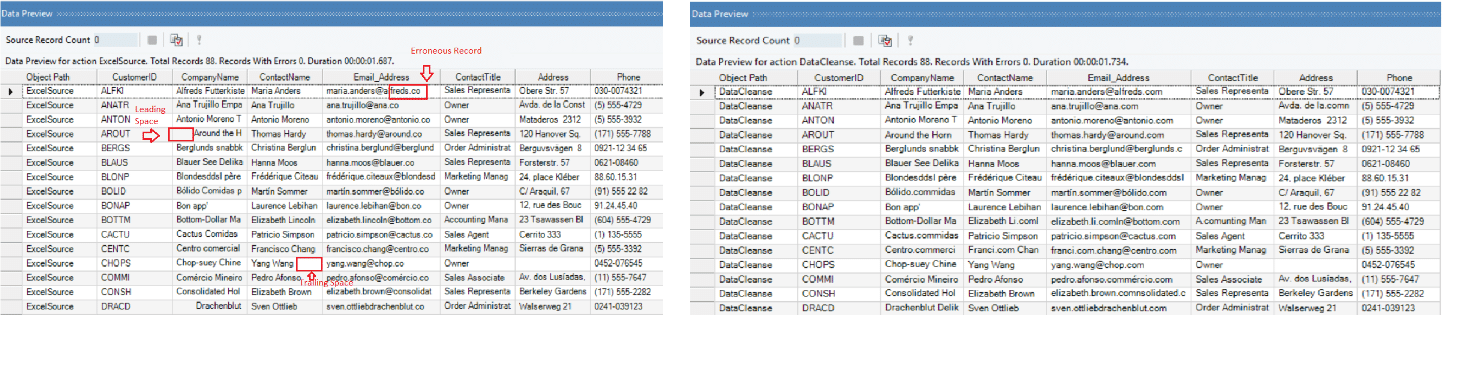
Fig. 5: Comparison of erroneous source data with cleansed data
Next, Data Quality Rules are applied to the cleansed data to identify records in the Email Address field that have an invalid format.
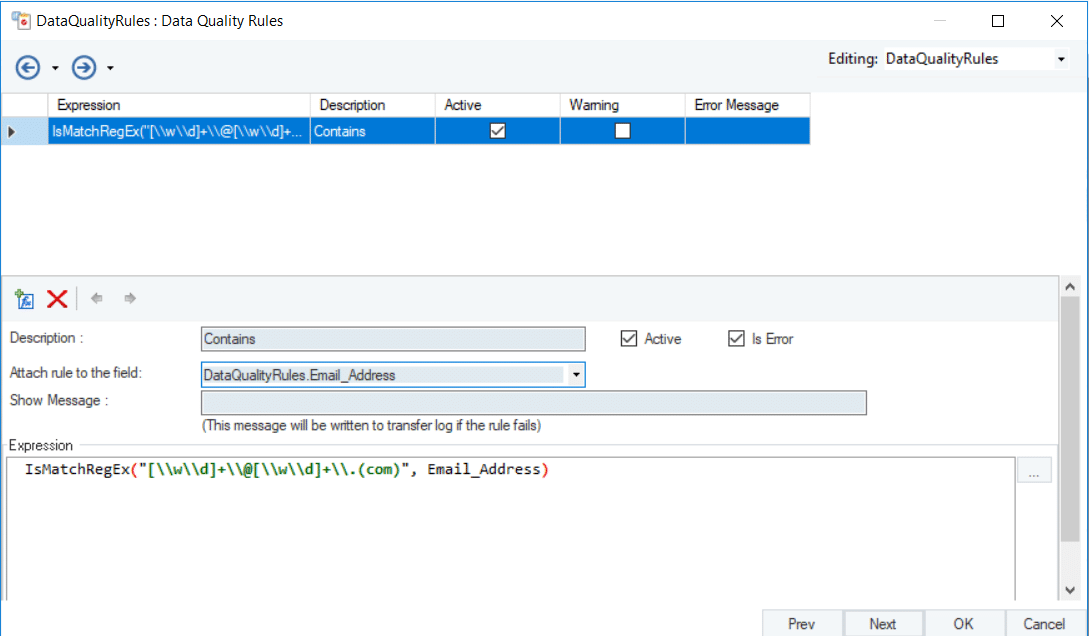
Fig.6: Flagging incorrect records in the Email Address field
The result can be seen in the next screenshot. Applying Data Quality Rules enables the organization to:
- Get consistent data: By correcting email addresses, the organization ensures that all the departments have access to consistent and correct information.
- Facilitate scalability: With a sound quality infrastructure in place, the organization can easily scale up without worrying about the trustworthiness and reliability of its data.
The errors identified by the Data Quality Rules are written into a log file, whereas the cleansed data is written into a Delimited file.
Simplify Data Validation with Astera Data Pipeline Builder
Automating data validation can significantly save time and streamline business processes in the modern enterprise world, where important decisions are derived from data. The code-free, AI-driven environment of Astera Data Pipeline Builder enables you to automate data validation as a part of dataflow or workflow. Further, data updates can be made conditional, depending upon the success of validation tests to ensure the trustworthiness of your enterprise data.
To find out how to simplify and automate your data validation tasks using a codeless end-to-end solution, download the trial version of Astera Data Pipeline Builder.
What is data validation?
Why is data validation important?
What are some common types of data validation checks?
How does data validation differ from data verification?
Can data validation be automated?
How does Astera Data Pipeline Builder facilitate data validation?
What are data quality rules in Astera Data Pipeline Builder?
How can I implement data validation in Astera Data Pipeline Builder?
What is schema validation?
How does schema validation differ from data validation?
How does data validation impact data integration projects?
Can data validation rules be customized?
Authors:
Astera Analytics Team



