Astera AI Agent Builder - First Look Coming Soon!
Astera AI Agent Builder - First Look Coming Soon!
The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

Loading Data into Facts and Dimensions — A Piece of Cake?
Kimball-style dimensional modeling has been the go-to architecture for most data warehouse developers over the past couple of decades. The denormalized nature of these schemas, coupled with optimization for history maintenance, makes the dimensional model an ideal tool for the data warehousing arsenal, especially for reporting through business intelligence (BI) tools.
On the face of it, the idea is simple: Fact tables contain transactional information, and dimensions provide context to these facts through foreign key relationships. The questions that arise, however, are the following: How easy is it to load and maintain data in fact and dimension tables? And Is it worth the effort?
Let’s take a scenario where you’ve set up an architecture for your data warehouse — a simple star schema consisting of sales information in the fact table, surrounded by a few dimensions, such as customers, suppliers, etc. The source data initially coming in from disparate systems has been loaded into a unified staging layer.
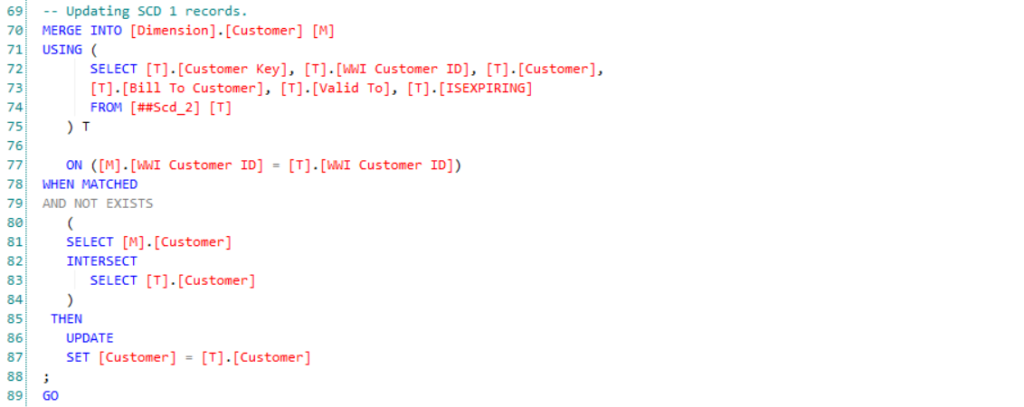
The objective is to set up a loading and maintenance process for your dimension and fact tables. Loading data into dimension tables can be simple, given that you’re not looking to maintain history. In such a case, you would only want to update the destination records, which can be performed via Slowly Changing Dimensions Type 1 (SCD1). Here’s a snippet of what that query would look like:
However, it is unlikely that this would be sufficient in a practical business scenario. It’s important to maintain at least some history in a data warehouse to identify trends and patterns. That is where other, more complicated, SCD types come into play, such as SCD 2, 3, and 6.
If you intend to use SCD 2 or 6 on certain fields, the table needs to contain record identifiers as well to recognize the active row for each record. This could be a true/false flag, an effective expiration date range, or just a version number for each record, to name a few examples.
In case you’re looking to use SCD 3 or 6, you would need an additional field to store the previous value of the field in question.
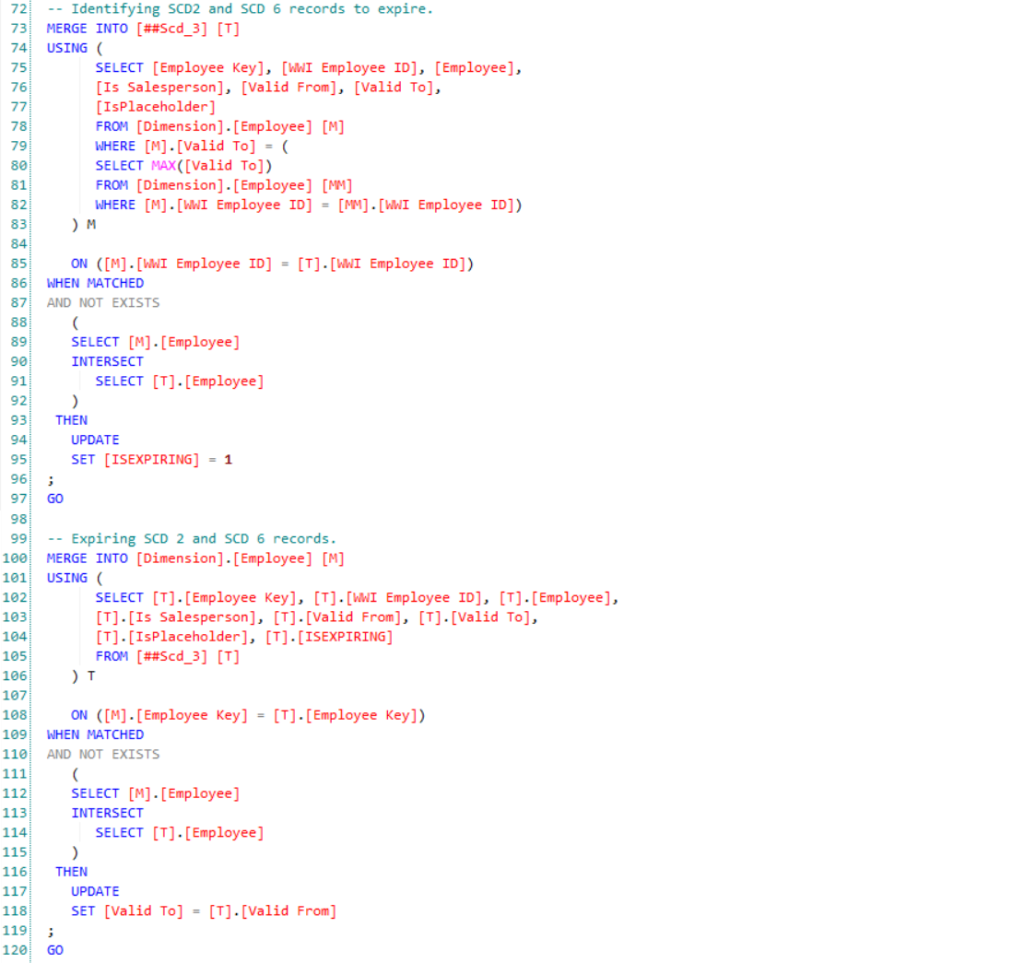
Here’s what a chunk of the query could look like if you were to use SCD 2 or 6 to maintain history:
Is it starting to look a bit complicated? We’ve only touched the tip of the iceberg.
You would likely require different levels of history for different fields. Let’s say, for instance, that you have an employee dimension that contains employees’ salary information and phone number. Here, you may want to keep track of how an employee’s salary is changing but just update the phone number.
For cases like this, you would use multiple SCD types; SCD 1 for the fields that merely require updates and SCD 2, 3, or 6 for those fields that require a certain level of history to be maintained. With so many things to take into account, you can imagine how complex the query would get!
So far, We’ve focused on the population and maintenance of dimension tables. These dimensions provide context to the information stored in fact tables. Therefore, every change in a dimension table is propagated into the fact table as well; ensuring that this propagation is done accurately can be challenging.
Some of the information you need to load into the fact table is not available in the source. The surrogate keys used to establish relationships between dimension and fact tables are non-existent in the staging layer — they were created as system-generated keys in each dimension.
Therefore, you’d need to design a mechanism that uses dimension lookups to take each incoming business (natural) key from the staging layer to the relevant dimension and fetch the active surrogate key for that record. Moreover, the intricacies of fetching these surrogate keys would vary based on the SCD type used for each field and the row identifier present in the dimension table.
As if that process isn’t complex enough, here’s another curveball for you: What if you have some missing entries in the fact table that don’t require the most updated surrogate key? You could use a transaction date key to determine the active surrogate key, given that you have used a time-stamp-specific active row identifier, such as the effective-expiration date range.
The situation could be the other way around as well: You may have some entries in the fact table that refer to a dimension record that hasn’t been added to the dimension table yet. This is a common data warehousing conundrum — late arriving dimensions and early arriving facts. To cater to this issue, you could create a dummy record in the dimension table at runtime.
This record would eventually be replaced by the appropriate (delayed) dimension record coming in from the source. But It would at least enable the dimension lookup to occur at the right time without any unnecessary hiccups.
All in all, loading data into the fact table can be a tedious and error-prone process. If the above-highlighted issues are not addressed. For instance, your pipelines could crash, or your warehouse could end up containing inaccurate data.
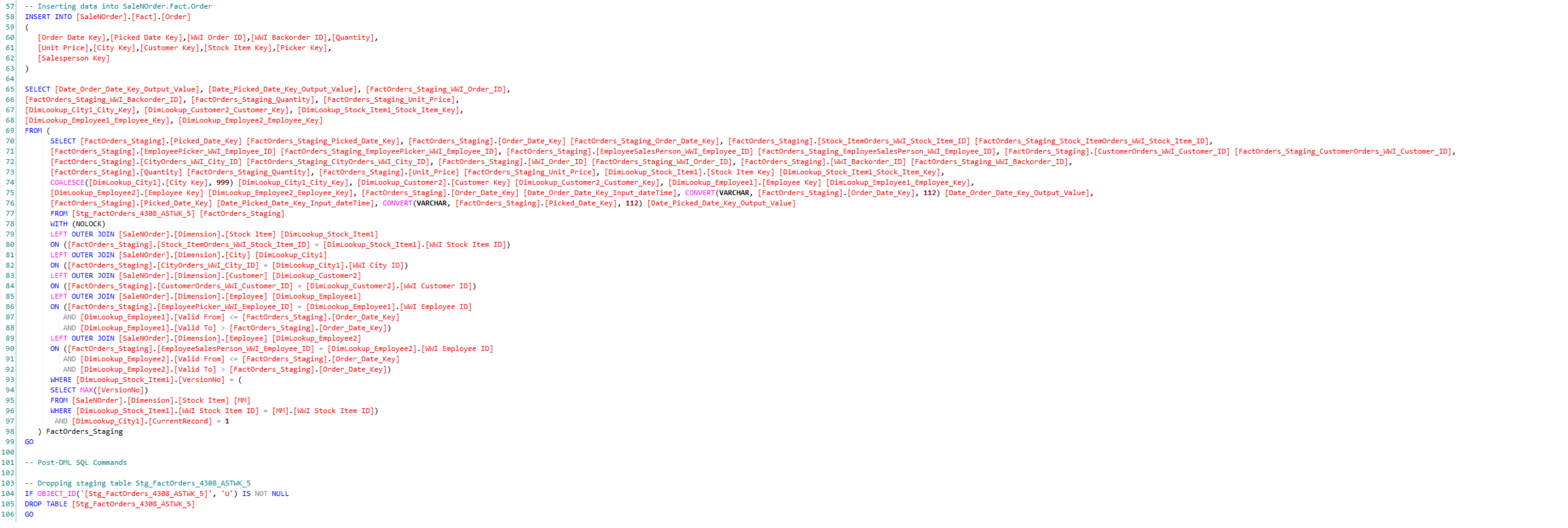
Here’s a sample query that could load data into a fact table:
Let’s say that you do get everything done. You’ve successfully typed out all the queries needed, and they’re perfect. Your job still isn’t quite complete yet. A data warehousing process is never completely finished because the maintenance of the ecosystem is as important as designing it in the first place. To maximize performance, you would need to ensure that the data is loaded incrementally, requiring Change Data Capture (CDC) mechanism to be implemented.
Moreover, these complex queries would need frequent updates, depending on the needs of the business. You may have to add or remove fields, change certain data types, alter the SCD type applied to a field, etc. Making these changes to the queries is not only time-consuming but also extremely error-prone. Before you know it, you may have messed up an existing pipeline while implementing a minor change in the loading mechanism.
Despite these potential maintenance issues, you would still feel that most of the hard work is done. However, enterprises are constantly looking to modernize and improve their data processes. A day might come when your company decides to switch data warehouse platforms. Let’s say they have decided to move from on-premises SQL Server to a cloud platform like Snowflake or Amazon Redshift.
Do you realize what that would require? First, you must create a new architecture on the new platform. Then, rewrite all the queries to set up pipelines native to the new destination tables. You would basically have to perform the entire process again — from scratch! So, based on everything we’ve unfolded, it’s safe to conclude that loading data into fact and dimension tables is NOT a piece of cake. The level of complexity involved can become too high, even for technical users.
But what if I told you there’s a much easier way to achieve the same result?
With Astera Data Warehouse Builder, you can build an architecture for your dimensional model using the intuitive data model designer. Moreover, the click-and-point interface allows you to assign roles, such as SCD types, active row identifiers, transaction date keys, etc., to the fields in fact and dimension tables.
Most importantly, you can leverage the information within your models in the tool’s drag-and-drop-based ETL/ELT component to automate the tedious and time-consuming tasks involved in loading fact and dimension tables — ranging from maintaining SCD’s in dimensions to performing dimension lookups in fact tables. The complicated code we saw earlier is generated automatically by the tool.
Why waste so much time and effort on writing huge queries when you can achieve the same result using a simple visual interface? Even though loading data into facts and dimensions is typically not a piece of cake, with Astera Data Warehouse Builder, it can be!
If you want to explore the agile way to build your data warehouse, reach us at sales@astera.com today or download a 14-day free trial.
Authors:
Syed Shaheryar Ali