 Astera AI Agent Builder - First Look Coming Soon!
Astera AI Agent Builder - First Look Coming Soon!- What is Database Replication?
- Difference Between Data Replication vs Database Replication
- Database Replication vs. Mirroring
- Top Benefits of Database Replication
- How Does Database Replication Work?
- Types of Database Replication
- Common Database Replication Challenges
- How to Evaluate Modern Database Replication Platforms
- Try Astera Data Pipeline Builder for AI-Driven Database Replication

The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

Database Replication 101: Everything You Need To Know
Database replication involves making sure important data is replicated across multiple locations within a company.
In the advanced digital age, businesses must take all measures to safeguard their data and ensure its availability at all times. Data availability is important for proactive decision-making and empowering other tech, such as AI. This is where database replication becomes a high priority.
But what is database replication exactly? What does it involve, and what are the benefits of replicating databases? Let’s find out.
What is Database Replication?
Database replication is the process of creating and maintaining multiple copies of a database across different locations or servers. The main objective of replication is to improve data availability, distribute the workload, and enhance the overall performance of the database system. It also provides redundancy and fault tolerance by ensuring that data is replicated to multiple nodes, whether synchronously or asynchronously.
Database replication plays a crucial role in modern data management systems and strategies. It is a fundamental technique used by organizations to ensure data integrity, reliability, and accessibility. It simplifies access to data across multiple teams, and, by making copies, it protects data from tampering and destruction.
Database replication is an ongoing process. Continuous replication ensures that changes to the primary database are promptly propagated to replicas, guaranteeing up-to-date data globally. It allows organizations to add new replicas and accommodate evolving schemas. Ongoing replication also facilitates automatic failover and recovery, ensuring seamless transitions during primary database failures.
Difference Between Data Replication vs Database Replication
Before diving further into database replication, it’s important to understand the distinction between data replication and database replication.
Data replication refers to copying specific data from one storage device to another, often for backup purposes. This process ensures that in the event of a hardware failure or data loss, the replicated data can be used to restore the original data.
On the other hand, database replication involves replicating an entire database, including its schema, tables, and stored procedures, to multiple servers. Unlike data replication, which focuses solely on copying data, database replication aims to create identical copies of the entire database structure and its contents.
Naturally, database replication involves more complexity and intricacies compared to simple data replication. It requires careful consideration of factors such as data consistency, synchronization, and conflict resolution.
Database Replication vs. Mirroring
Database replication and mirroring are techniques used to create redundant copies of a database. However, there are some key differences between them.
Database replication involves creating multiple copies of a database. As mentioned previously, it distributes the workload and improves performance by allowing applications and users to access data from the nearest replica.
The clear advantage of database replication over mirroring lies in the flexibility it offers in terms of data distribution and configuration options. It offers the ability to selectively replicate specific objects or subsets of data within a database. This feature provides more granularity and control over what data is replicated, allowing users to tailor the replication process to meet specific needs.
On the other hand, mirroring involves creating an exact copy of the database on another server, known as the mirror server. The mirror server remains synchronized with the primary server through continuous data transfer. In the event of a failure on the primary server, the mirror server can take over seamlessly.
One thing to keep in mind is that while mirroring “mirrors” the database, it cannot be queried unless snapshots are created.
Top Benefits of Database Replication
One of the key benefits of database replication is improved data availability. With multiple copies of the database spread across different locations, or servers, organizations can ensure that the data is always accessible, even in the event of a server failure or network outage. This high availability of data is essential for real-time access to up-to-date information.
Furthermore, database replication helps distribute the workload among multiple nodes, resulting in improved performance. By spreading the read and write operations across different replicas, organizations can handle a higher number of concurrent requests, reducing the chances of bottlenecks and improving response times. The distributed nature of replication also enables organizations to scale their databases horizontally by adding more replicas as the workload increases.
Database replication also plays a vital role in disaster recovery strategies. By having replicated copies of the database in different geographical locations, organizations can recover from disasters such as natural calamities, hardware failures, or human errors. In the event of a disaster, the replicated database can be quickly activated, ensuring minimal downtime and data loss.
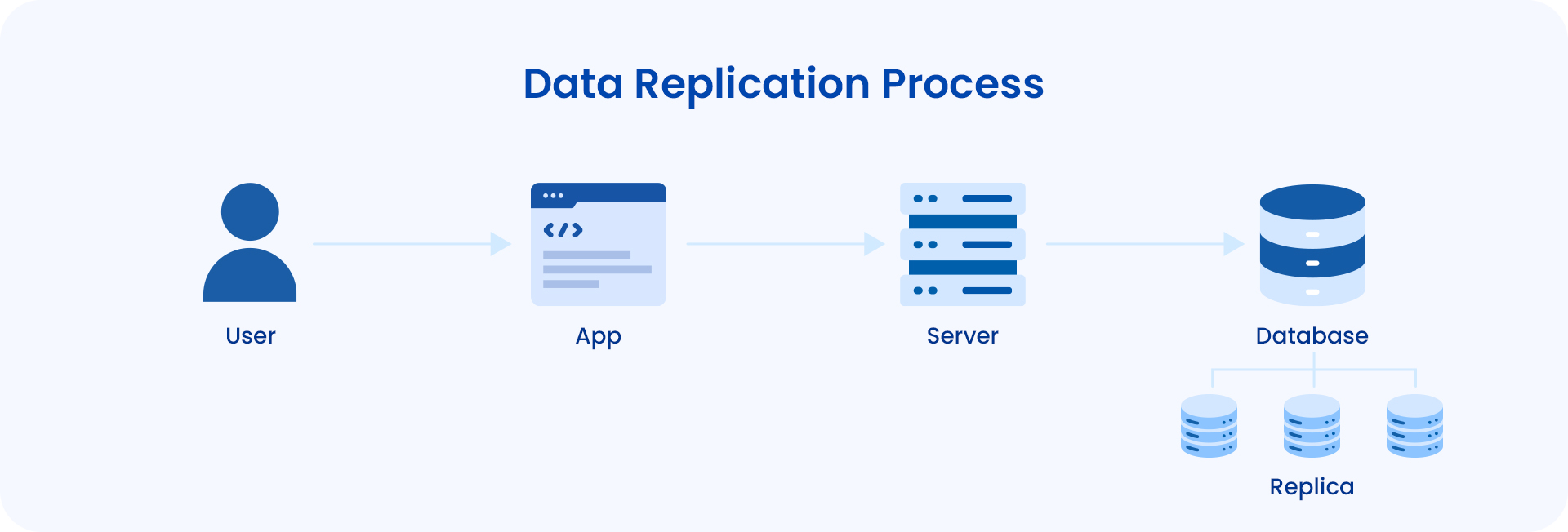
How Does Database Replication Work?
The replication process follows a structured sequence to ensure accurate and efficient data distribution.
1. Identifying the Source Database
Replication starts with selecting the primary database, where all data modifications originate. This system serves as the authoritative source for updates.
2. Configuring Replica Databases
One or more replica databases (or subscribers) are set up to receive updates. Depending on the replication type, these replicas may be read-only or support bidirectional data modifications.
3. Capturing Data Changes
Updates, inserts, and deletes are tracked using transaction logs or change data capture (CDC) mechanisms, ensuring only relevant modifications are transmitted to replicas.
4. Transmitting Changes to Replicas
Replication engines send updates over the network using log-based streaming, batch processing, or event-driven synchronization, depending on system requirements and latency tolerances.
5. Applying Updates on Replicas
The target databases process incoming changes and apply them in the same sequence as they occurred in the source system. Some implementations use conflict resolution algorithms if multiple replicas modify the same data.
6. Ensuring Data Consistency
Monitoring tools verify that replicas remain synchronized with the primary database. Some systems implement periodic checksum verification to detect and correct inconsistencies, ensuring data integrity across all replicated instances.
By following this structured approach, database replication maintains data availability, improves performance, and supports business continuity in distributed environments.
Types of Database Replication
Full-table Replication
Full-table replication replicates entire tables from a source database to one or more replica databases. In this approach, any changes made to the source table, including inserts, updates, and deletes, are replicated entirely to the corresponding table(s) in the replica database(s). Full-table replication is straightforward and ensures that the replica contains an exact copy of the source table at any given point in time.
However, it may result in higher data transfer and storage requirements, especially when dealing with large tables or when only a small portion of the data has changed. This method is commonly contrasted with more granular approaches, such as CDC, where only the modified data is replicated, leading to more efficient use of resources.
Key-Based Incremental Replication
In this type of database replication strategy, changes to a database are identified and replicated based on specific key values within the data. Instead of replicating entire tables, key-based incremental replication selectively captures and replicates only the rows that have been inserted, updated, or deleted, based on certain key columns or fields. Key-based incremental replication is particularly useful for minimizing data transfer and improving efficiency in scenarios where only a subset of data changes frequently.
Log-Based Replication
Log-based replication relies on capturing and replicating changes directly from the transaction log (or database log) of the source database. Instead of monitoring and tracking individual data modifications (as in key-based or full-table replication), log-based replication extracts the changes recorded in the database’s transaction log, which is a sequential record of all database transactions.
Synchronous Replication
Synchronous replication ensures that all changes made to the database are immediately replicated to all replicas before the transaction is considered complete. While it guarantees data consistency, it may introduce latency as the transaction has to wait for the replication process to finish.
Asynchronous Replication
Asynchronous database replication is used to copy and synchronize data between databases in a way that doesn’t require the primary database to wait for the replica to acknowledge receipt of the data changes. In this scenario, the replication process doesn’t happen in real-time or synchronously with each transaction on the primary database. Instead, changes are transmitted and applied to the replica at a delay, often referred to as “replication lag”.
Master-slave Replication
In master-slave replication, also called Single Leader Replication, there is a single primary database, known as the master, which processes write operations. The replicas, known as slaves, receive the changes from the master and update their data accordingly. This technique is widely used in scenarios where read scalability and fault tolerance are important.
Master-master Replication
Master-master replication, also known as bi-directional replication, allows both databases to act as the primary database and accept write operations. Changes made in one database are replicated to the other, ensuring that both databases are in sync. This technique provides better fault tolerance and enables load balancing between databases.
Snapshot Replication
Snapshot replication is a type of database replication where a copy of the entire database is taken at a specific point in time and then transferred to the replicas. This initial snapshot is then followed by incremental updates to keep the replicas synchronized with the primary database. Snapshot replication is commonly used when the data changes infrequently or when the replicas are located in remote locations with limited bandwidth.
Transactional Replication
Transactional replication is a type of database replication that captures and propagates individual transactions from the primary database to the replicas. This means that every change made to the primary database, such as insertions, updates, or deletions, is replicated to the replicas in the same order they occurred. Transactional replication is often used in scenarios where data consistency and low latency are critical, such as in financial systems or real-time applications.
Merge Replication
Merge replication is a type of database replication that allows multiple replicas to independently modify the data and then merge the changes back to the primary database. This type of replication is commonly used in scenarios where the replicas are frequently disconnected from the network or when conflicts between changes made at different replicas need to be resolved. Merge replication requires a more complex conflict resolution mechanism to ensure data integrity.
Peer-to-Peer Replication
Peer-to-peer replication, also known as multi-master replication, is a type of database replication where each replica can act as both a source and a target for data changes. This means that changes made at any replica are propagated to all other replicas in the network. Peer-to-peer replication is often used in distributed systems where multiple replicas need to be updated simultaneously and where high availability and scalability are essential.
Common Database Replication Challenges
Implementing database replication comes with its own set of challenges. It’s important to factor in these challenges to ensure smooth and effective database replication:
- Data consistency:
Ensuring data consistency across replicas can be challenging, especially in scenarios where data changes frequently. Synchronizing and propagating changes requires sophisticated algorithms and techniques to avoid conflicts and maintain consistency. - Replication lag:
As replication often involves propagating changes to remote replicas, there can be a slight delay between the primary database and the replicas. Minimizing replication lag may be a high priority, especially in scenarios where real-time data is critical. Using synchronous database replication can help keep replication delays to a minimum. - Network latency:
Replicating data across geographically distributed locations can be impacted by network latency. Ensuring efficient data transfer and minimizing latency becomes critical to maintain a responsive and reliable replication system. - Scalability:
As the volume of data and the number of transactions increase, ensuring the scalability of the replication system becomes a challenge. Scaling to accommodate a growing workload, like during a holiday sale, while maintaining performance and responsiveness is a delicate balance. - Conflict resolution:
When concurrent updates happen on both the primary and replica databases, a mechanism is needed to determine which update prevails. Choosing the wrong strategy can lead to lost data or corrupted information.
How to Evaluate Modern Database Replication Platforms
With numerous database replication platforms available in the market, choosing the right one requires due diligence. Here are some key factors to consider when evaluating modern database replication platforms:
- Performance and scalability:
Assess the platform’s ability to handle the workload and scale as your data grows. Look for features such as load balancing, data sharding, and automatic failover. - Latency and Replication lag:
Assess the platform’s ability to minimize replication lag, especially if your use case requires real-time or near-real-time data synchronization. Look for features that enable monitoring and management of replication lag. - Data consistency and integrity:
Ensure that the database replication platform provides mechanisms to maintain data consistency and integrity across replicas, such as conflict resolution, transactional guarantees, and data validation. - Monitoring and management:
Consider the ease of monitoring and managing the replication process. A good database replication solution provides functionalities like real-time monitoring, performance metrics, and intuitive management interfaces to streamline the process. - Integration and compatibility:
Check if the platform supports integration with your existing database systems and applications. Evaluate compatibility with different database management systems and programming languages. No-code tools, like Astera Data Pipeline Builder, can integrate with a range of databases, ensuring a complete data management process.
By evaluating these factors, organizations can make an informed decision and select a modern and efficient database replication tool tailored to their unique requirements.
Try Astera Data Pipeline Builder for AI-Driven Database Replication
Database replication plays a crucial role in ensuring data availability, performance, and fault tolerance for organizations of all sizes. Understanding the concepts and techniques associated with database replication is essential for building resilient and scalable data systems.
Implementing a robust database replication solution and choosing the right replication platform, enables you to deliver high data availability, keeping it ready to meet your ever-growing business needs.
Make Database Replication Easy and Fast
Streamline and automate the entire database replication process—without using any code! Astera Data Pipeline Builder does it all for you.
Start Your FREE 14-Day Trial
What is database replication?
Why is database replication important?
How does database replication improve performance?
How does Astera Data Pipeline Builder facilitate database replication?
Can Astera Data Pipeline Builder handle real-time data replication?
What are the benefits of using Astera Data Pipeline Builder for replication?
Is database replication suitable for all types of data?
How do I choose the right replication method for my organization?
Can replication be used for disaster recovery?
How does replication affect database scalability?
Authors:
Junaid Baig



