 Astera AI Agent Builder - First Look Coming Soon!
Astera AI Agent Builder - First Look Coming Soon!- What is a Dimensional Data Model?
- Elements Involved in Dimensional Modeling
- Dimensional Data Modeling Example
- Designing a Dimensional Data Model
- What is Multi-Dimensional Data Model in Data Warehouse?
- Benefits of Dimensional Modeling
- Limitations of Dimension Modeling
- Automation – A Game Changer for Dimensional Modeling

The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

What is dimensional data modeling? Examples, process, & benefits
Businesses are increasingly shifting towards data warehouses to leverage the large volume of data that they generate every day. Data warehousing is the best solution for analytics. However, businesses didn’t always have this option. Early databases were primarily designed for transactional processing and lacked the efficiency needed for analytical reporting, which gave birth to dimensional modeling.
In the early 1990s, Ralph Kimball, a prominent figure when it comes to data warehouse approaches, developed the principles of dimensional modeling. His book “The Data Warehouse Toolkit,” first published in 1996, outlined the concepts and best practices of dimensional modeling. Kimball’s approach focused on modeling data in a way that aligns with business processes and user requirements, emphasizing simplicity and ease of use.
In this article, we will delve deep into the concepts of dimensional data modeling and understand its processes, benefits and limitations.
What is a Dimensional Data Model?
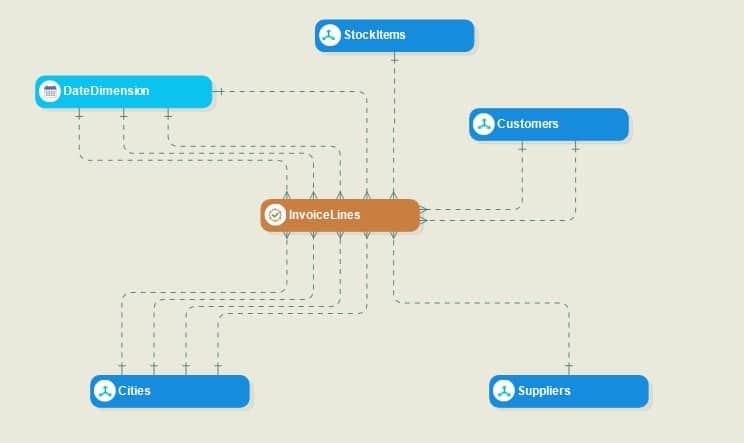
A dimensional data model is a way of organizing and structuring data in a database or data warehouse to make it easier for businesses to analyze and gain insights from their data. They are particularly useful when dealing with large volumes of data and when users need to explore data from different angles or dimensions.
Different applications require different dimensional modeling techniques. There are primarily two modeling techniques: Normalized Entity-Relationship models (ER models) and Dimensional modeling.
Normalized Entity-Relationship models (ER models), on the other hand, are designed to eliminate data redundancy, quickly perform the Insert, Update, and Delete operations, and get the data inside a database.
In contrast, dimensional models or Kimball dimensional data models are denormalized structures designed to retrieve data from a data warehouse. They use fact and dimension tables to maintain a record of historical data in data warehouses. Moreover, they are optimized to perform the Select operation and are used in the basic design framework to build highly optimized and functional data warehouses.
Elements Involved in Dimensional Modeling
Fact Tables or Business Measures
Fact tables store the numeric information about business measures and foreign keys to the dimensional tables. Business facts can be additive, semi-additive, or non-additive. Table 1 explains the three types of fact tables.
| Type of Facts | Description |
| Additive Facts | Business measures that can be aggregated across all dimensions |
| Semi-additive Facts | Business measures that can be aggregated across some dimensions and not across others (usually date and time dimensions) |
| Non-additive Facts | Business measures that cannot be aggregated across any dimension |
Table 1: Types of facts in a fact table
Fact Types Explained with a Dimensional Data Model
An apparel store maintains the following data in fact table rows for a sales transaction:
| Date | Store Location | Product Type | Quantity | Unit Price | Sales Amount | Inventory | Sales Tax |
| 6/3/2018 | CA | Nylon | 5 | 100 | 500 | 30 | 7.75% |
| 6/3/2018 | CA | Polyester | 7 | 250 | 1750 | 50 | 7.75% |
| 6/3/2018 | PA | Nylon | 6 | 100 | 600 | 65 | 6.00% |
| 6/3/2018 | PA | Polyester | 3 | 250 | 750 | 25 | 6.00% |
| 6/4/2018 | CA | Nylon | 7 | 100 | 700 | 36 | 7.75% |
| 6/4/2018 | CA | Polyester | 6 | 250 | 1500 | 17 | 7.75% |
| /4/2018 | PA | Nylon | 9 | 100 | 900 | 14 | 6.00% |
| 6/4/2018 | PA | Polyester | 10 | 250 | 2500 | 20 | 6.00% |
Table 2: Transactional table maintained by an apparel store
The columns containing numeric information about the business process are our business facts. In this example, Quantity, Unit Price, Sales Amount, Inventory, and Sales Tax are facts. And the rest of the entities (Date, Store, and Product Type) are dimensions.
Sales Amount can be added across all dimensions. Therefore, it is an additive fact. Moreover, adding Inventory information across the Store dimension provides useful business information. However, since this is just the snapshot of the number of goods at a certain point, adding it across the Date dimension does not give any helpful business insights. Since Inventory is additive across some dimensions and non-additive across others, it is a semi-additive fact. Now consider Sales Tax. Adding Sales Tax across any dimension will pose problems during analytical processing. Sales Tax is, therefore, a non-additive fact.
Dimension Tables
Dimension tables store descriptive information about the business facts to help understand and analyze the data better. In the example presented in Table 2, Date, Store Location, and Product Type are dimension entities, giving more information about the business facts. The total amount of Sales is an important measure to record, but without the dimensions, a business cannot assess which store location or product type yields more sales.

Figure 1: Star schema with fact and dimension tables
Primary Key
The primary key is a column in dimension tables that identifies unique records. The surrogate key will be the primary key for the slowly changing dimensions.
Foreign Key
Foreign keys join two tables (usually fact and dimension tables). The primary key in a dimension table is a foreign key in the related fact table and is used to reference that particular dimension.
Dimensional Data Modeling Example
Let’s consider a real-life example of dimensional modeling for a retail business. Imagine a chain of stores that wants to analyze its sales data to gain insights into its performance. In this scenario, a dimensional data model could be applied as follows:
- Facts: The primary facts in this scenario would be sales transactions. These facts would include data such as:
- Sales revenue
- Quantity of products sold
- Discounts applied
- Profit margins
- Dimensions: Various dimensions would provide context to the sales data:
- Time Dimension: This dimension could include attributes like year, quarter, month, day, and even time of day. For instance, it could help answer questions like, “What were our sales for each quarter last year?”
- Product Dimension: It could describe the products sold in the stores. It might include attributes like product category, brand, and product name. For example, it could help answer questions like, “Which product category generated the most revenue?”
- Store Dimension: This one could contain information about the individual store locations, such as store name, city, state, and store manager. It could answer questions like, “Which store had the highest sales last month?”
- Customer Dimension: It could provide insights into customer demographics, such as age, gender, and location. It could help answer questions like, “What is the average purchase amount per customer segment?”
- Facts-to-Dimensions Relationships: The fact table, containing the sales transactions, would have foreign keys linking it to the dimension tables. For example, each sales transaction record might have foreign keys pointing to the corresponding time, product, store, and customer in their respective dimension tables.
- Hierarchies: Hierarchies within dimensions would help users navigate and analyze data at different levels of granularity. For example, the time dimension might have a hierarchy that goes from year to quarter to month to day.
- Measures: Measures would be calculated from the sales facts to provide valuable insights. For example:
- Total Sales Amount
- Average Discount Percentage
- Profit Margin Percentage
With this dimensional data model in place, the retail business could use it to answer a wide range of questions, such as:
- “What were our total sales for each product category in the last quarter?”
- “Which store had the highest sales growth compared to the same period last year?”
- “What is the average profit margin for products in each product category?”
Designing a Dimensional Data Model
To understand the process of designing dimensional models, let’s consider the example of an apparel line that sells two kinds of windbreakers – Nylon and Polyester in its two stores across California and Pennsylvania. The sample data for the example is shown in Table 2.
Step 1: Identify the Business Processes
Before modeling the data, you should find the types of dimensional modeling appropriate for your data model. The dimensional modeling process (or any data modeling) begins with the identification of the business process that you want to track. In this case, we want to track sales for the two types of windbreakers.
Step 2: Identify Facts and Dimensions in Your Dimensional Data Model
The information in a dimensional model is categorized into two table types – Facts and Dimensions. The next step is identifying the business facts you want to measure and their associated dimensions. In our example, windbreaker sale is the fact that we want to measure. Date, store location (California and Pennsylvania), and product type (Nylon windbreakers and Polyester windbreakers) are the dimensions that give us further insights into the sales process.
Step 3: Identify the Attributes for Dimensions
After you’ve identified the dimensions and facts for your business process, the next step is identifying attributes and creating a separate dimensional table for each dimension. There are different types of dimensional tables for each data type. Each record in the dimension table should have a unique key. This key will be used to identify the records in the dimension table and as the foreign key in the fact table to reference the particular dimension and join it with the fact table. Tables 3-5 show the different types of dimensions in a data warehouse in our apparel line example.
| Date Dimension | ||
| Date Key | Date | Day |
| 10201 | 6/3/2018 | Sunday |
| 10202 | 6/4/2018 | Monday |
Table 3: Dimension table for Date
| Store Dimension | |||
| Store Key | Store Name | City | State |
| 151 | AngAngie’sparel | Los Angeles | California |
| 152 | AngAngie’sparel | Pittsburgh | Pennsylvania |
Table 4: Dimension table for Store
| Product Dimension | |||
| Product Code | Collection | Material | Color |
| 131620 | Windbreaker – Fall Collection | Nylon | Orange |
| 131571 | Windbreaker – Fall Collection | Polyester | Black |
Table 5: Dimension table for Product
Step 4: Define the Granularity for Business Facts
Granularity refers to the level of information that is stored in any table. For instance, in our example, the sales amount is recorded daily; therefore, the granularity, in this case, is daily. The fact tables in a dimensional model should be consistent with the pre-defined granularity.
Step 5: Storing Historical Information (Slowly Changing Dimensions)
An important feature of dimensional models is that the dimensional attributes can be easily modified without changing the complete transaction information. For example, the apparel line decides to continue the Nylon windbreaker from Fall Collection into the Spring Collection and updates the name in the Collection attribute. Making the update is easy in the dimensional table, but we will lose our previous data with the update. If the goal of your data modeling and data warehouse is maintaining and storing history, this could be a problem. Dimensions that change slowly over time are called Slowly Changing Dimensions. In addition, the time dimension table in a data warehouse is automatically generated and captures the time at which different transactions occur. You can maintain and store historical data by tracking slowly changing dimensions.
Learn More About Designing An Automated Dimensional Modeling With Our Step By Step Guide
What is Multi-Dimensional Data Model in Data Warehouse?
A Multi-Dimensional Data Model is a specific implementation of dimensional data modeling tailored for more advanced analytical and reporting needs. It extends the concepts of regular dimensional data modeling to provide additional capabilities. Here are some important factors to note about dimensional data model:
- It adds complexity by introducing the concept of data cubes. Data cubes store pre-aggregated data, which can lead to a more complex but more efficient structure for multidimensional analysis.
- It continues to be user-friendly but offers even more capabilities for users to interact with data using OLAP tools. Users can pivot, drill down, and analyze data from multiple dimensions simultaneously.
- It often involves denormalized dimension tables and pre-aggregated data in data cubes. While this may increase storage needs for the aggregated data, it can reduce redundancy in dimension tables, leading to more efficient storage.
- It is ideal for advanced analytics, complex reporting, and scenarios where performance is critical, such as large-scale data warehouses with extensive historical data.
Benefits of Dimensional Modeling
Dimensional modeling is still the most used data modeling technique for designing enterprise data warehouses because of the benefits it yields. These include:
Optimized for Query Performance: Dimensional models are specifically designed for querying and reporting, which results in faster query performance, especially for complex analytical queries.
Faster Data Retrieval: Dimensional data modeling merges the tables in the model itself, which enables users to retrieve data faster from different data sources by running join queries. The denormalized schema of a dimensional model data warehouse, instead of the normalized one in the snowflake schema, is optimized to run ad hoc queries. As a result, it greatly complements an organization’s business intelligence (BI) goals.
Flexible to Change: A dimensional modeling framework makes the data warehousing process extensible. The design can be easily modified to incorporate new business requirements or adjust the central repository. New entities can be added to the model or the layout of the existing ones can be changed to reflect modified business processes.
Multidimensional Analysis: Dimensional models support multidimensional analysis, so users can explore data from various dimensions and hierarchies simultaneously.
Reduced Data Redundancy: Dimensional models often involve denormalization, which reduces data redundancy and consequently improves query performance compared to highly normalized models.
Limitations of Dimension Modeling
While dimensional modeling is a powerful technique for analytical and reporting needs, it also has some limitations, and there are scenarios where it may not be the most suitable approach. So, it’s essential to evaluate whether it aligns with the characteristics and requirements of your data and use cases. Here are some limitations of dimensional modeling and situations where you might consider alternative modeling techniques:
- Complex Relationships: Dimensional modeling assumes that relationships between dimensions and facts are relatively simple. If your data involves highly complex relationships that cannot be easily represented in a star or snowflake schema, dimensional modeling may not be the best choice.
- Frequent Data Changes: Dimensional models are designed for historical analysis and may not handle data that changes frequently or requires real-time updates well. In such cases, a transactional or normalized model may be more appropriate.
- Sparse Data: When you are dealing with data where many combinations of dimensions have no associated facts (sparse data), dimensional models can lead to inefficient storage and query performance.
- Large and Unstructured Data: If your data includes large amounts of unstructured or semi-structured data (e.g., text documents, social media feeds), dimensional modeling alone may not be sufficient. You may need to incorporate techniques like NoSQL databases or document-oriented databases.
Automation – A Game Changer for Dimensional Modeling
Designing dimensional models is an essential step in building the framework of an enterprise data warehouse. The process can be streamlined with the help of a robust data warehouse automation tool such as Astera Data Warehouse Builder.
With Astera DW Builder, you can quickly build dimensional models in a visual code-free integrated development environment. Entities can be denormalized with simple drag-and-drop and merges. Entity roles (facts and dimensions) can be assigned in bulk, saving you valuable time when working with hundreds of entities. In addition, the product enables you to manage slowly changing dimensions with built-in support for SCD types 1, 2, 3, and 6.
Astera DW Builder is an end-to-end data warehouse automation platform with built-in dimensional data modeling capabilities, support for a wide range of databases and CRM applications, automated data mapping and data loading features, and native integration with business intelligence platforms such as Tableau and Power BI.
See Astera DW Builder’s demo or sign up for a free trial to experience first-hand the power of data warehouse automation.
Authors:
Iqbal Ahmed



