 Astera AI Agent Builder - First Look Coming Soon!
Astera AI Agent Builder - First Look Coming Soon! Apr 29th | 11 AM PT
Apr 29th | 11 AM PT

The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

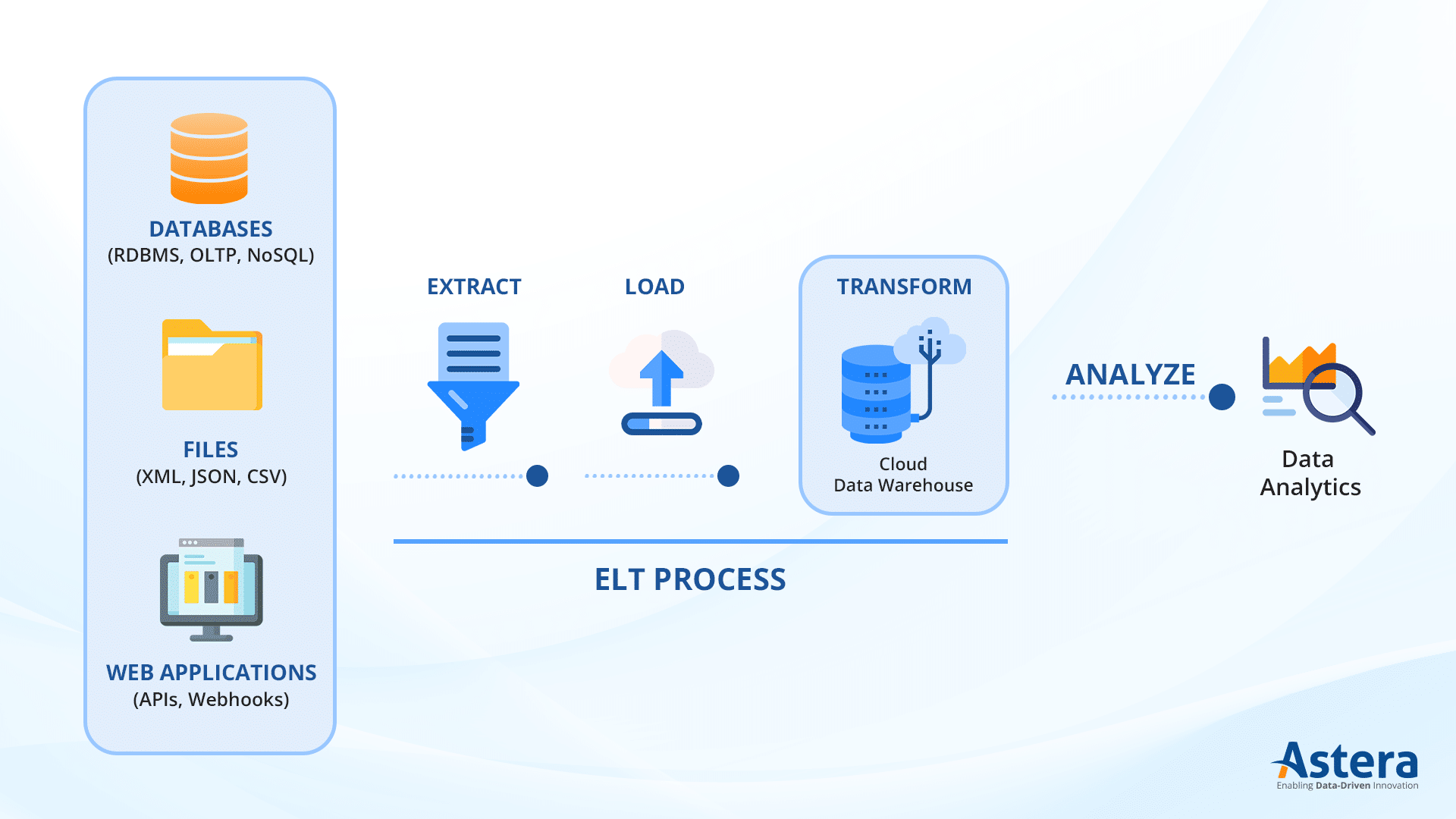
What is ELT (Extract, Load, Transform)? Here’s Everything You Need to Know
For decades, organizations have used Extract, transform and load (ETL) to integrate data stored across disparate source systems. However, the increasing data volume, variety, and velocity presented by the big data age call for a different approach. Many data architects are now inclining toward extract, load, and transform (ELT), which is more suited for the modern data stack.
The blog discusses how ELT works, the evolution of ETL into ELT, why the latter has become a more popular approach, and whether the two approaches can coexist.
What is ELT?
Extract, Load and Transform (ELT) is a modern data integration process that involves extracting data from various sources, loading it into a target system, and then transforming it within that environment. The transformation step includes cleaning, structuring, and optimizing the data for analysis and reporting. ELT leverages the processing power of modern data warehouses and data lakes, allowing for efficient handling of large volumes of structured and unstructured data. This approach is commonly used in cloud-based architectures, enabling organizations to store raw data and apply transformations as needed.
How ELT Works
ELT follows a three-step process that optimizes data movement and processing within cloud-native environments.
1. Extract
The first step involves retrieving raw data from multiple sources, such as:
- Relational databases (e.g., MySQL, PostgreSQL, SQL Server)
- APIs and web services (e.g., REST, SOAP)
- Flat files (e.g., CSV, JSON, XML)
- Streaming sources (e.g., Kafka, IoT sensors, event logs)
This data is pulled in its native format and is often unstructured or semi-structured. The extraction process may be performed in batches or real-time streams, depending on the use case.
2. Load
Once extracted, the raw data is loaded directly into a storage system, such as:
- Cloud data warehouses (e.g., Snowflake, Google BigQuery, Amazon Redshift)
- Data lakes (e.g., Amazon S3, Azure Data Lake, Google Cloud Storage)
- Distributed processing frameworks (e.g., Apache Hadoop, Apache Spark)
The goal of this step is to move data quickly without modifying it, enabling faster ingestion and storage. Many ELT platforms use parallel loading techniques to optimize performance and reduce bottlenecks.
3. Transform
After loading, the data is processed to make it usable for reporting, analytics, and decision-making. This step may include tasks such as organizing, cleaning, standardizing, and enriching the data. ELT allows transformations to be performed using a variety of tools, including built-in database functions, SQL queries, and no-code or low-code data processing solutions. Since modern cloud warehouses provide on-demand compute power, transformations can be executed efficiently at scale without impacting extraction and loading speeds.
ELT vs. ETL: What’s the Difference?
ETL and ELT both involve three steps: extraction, transformation, and loading. The fundamental difference between the two lies in when and where data transformation occurs.
-
ETL transforms data before loading: In this approach, data is extracted from sources, processed in a staging area, and then loaded into the target system. This ensures that only structured, cleaned, and optimized data is stored, making ETL ideal for traditional data warehouses that require strict data governance and predefined schemas. Since transformations occur outside the target system, ETL often requires dedicated processing resources and additional time for data preparation.
-
ELT transforms data after loading: Here, raw data is first loaded into the target system (typically a cloud data warehouse or data lake) and transformed as needed. This eliminates the need for an external staging area, shifting the computational workload to the target system. ELT is commonly used in modern data architectures that handle large volumes of structured, semi-structured, and unstructured data, allowing for more flexible data processing and real-time analytics.
Faster, Smarter Data Processing with ELT
Connect to 100+ sources, automate data movement, and leverage cloud-native processing for scalable transformations. Reduce latency, enhance efficiency, and unlock real-time insights—all without coding!
Start Free Trial
ELT in the Era of Cloud
The rise of unconventional data sources—IoT devices, social media, and satellite imagery—has led to an explosion in data volume, variety, and velocity. To handle this surge, enterprises are turning to cloud data warehouses (e.g., Snowflake, Amazon Redshift, Google BigQuery) and cloud storage platforms (e.g., Amazon S3, Azure Blob Storage, Google Cloud Storage) for scalable, high-performance data management.
In this cloud-first environment, ELT (Extract, Load, Transform) has become the preferred approach for processing data.
It is particularly suited for cloud environments because:
- Optimized for in-platform processing: Unlike traditional databases, modern cloud warehouses can efficiently perform transformations at scale. ELT takes advantage of this by loading raw data first and applying transformations within the warehouse.
- Faster and more scalable data ingestion: ELT accelerates the loading process by eliminating transformation bottlenecks, making it easier to ingest high-volume, real-time, or unstructured data.
- Retaining raw data supports flexibility: Since ELT loads data in its original form, organizations can transform it in multiple ways for various analytical use cases, AI models, and compliance requirements.
Benefits of ELT
-
Enhanced Performance & Efficiency – Cloud data warehouses use parallel processing and distributed computing to handle transformations, allowing for faster execution times and better resource utilization compared to traditional ETL workflows.
- Optimized for Modern Data Architectures – ELT aligns with modern data lake and lakehouse architectures, allowing businesses to store and process diverse data formats efficiently while supporting real-time analytics and reporting.
-
Reduced Data Latency – ELT enables real-time or near-real-time data availability by loading it first and transforming it within the cloud platform. This ensures businesses can act on the most up-to-date information instead of waiting for batch ETL processes to complete.
-
Flexible & Future-Proof Data Strategy – ELT stores raw data before transformation, allowing businesses to reprocess and adapt data as new analytical requirements, regulations, or use cases emerge, ensuring long-term flexibility and maximizing data value.
-
Greater Accessibility – Business users and analysts can directly interact with raw data in cloud warehouses, enabling self-service data exploration and analysis without relying on IT teams for pre-transformed datasets.
-
Lower Operational Costs – Since ELT utilizes cloud computing resources for transformations, businesses can minimize infrastructure costs by eliminating the need for separate ETL servers and reducing data movement, leading to lower operational expenses.
ETL and ELT- Substitutes or Complements?
While ETL and ELT are considered alternatives, these approaches aren’t mutually exclusive. While the latter solves many of the ETL’s problems, dubbing it the substitute might not be accurate. Both approaches have advantages and disadvantages, and their efficacy depends on the type of data assets and business requirements.
For example, if you need to integrate data with sensitive business information, ETL should be your preferred data integration approach as it allows you to structure, transform, manipulate, and secure data as per requirements before loading it to the target destination. On the other hand, when you are working with large volumes of data coming from multiple sources, where any slowdowns can adversely impact business performance, you should choose ELT.
Therefore, it’s safe to say that ELT and ETL can coexist and are vital for organizational success. Instead of seeing the two as substitutes, you should view them as counterparts to leverage business intelligence essential for growth.
Features to Look Out For in ELT Tools
It is important to choose the right ELT tool for your organization. Here are some features that you need to keep in mind before you invest in one:
- Code-Free Architecture
An ELT tool should provide the same level of usability to both developers and business users without the need for advance technical knowledge. A no-code ELT tool reduces dependence on the IT team and provides ease of use and accessibility to information, thereby enabling enterprises to leverage valuable insights quickly and efficiently.
- Automation
A typical enterprise processes high data volumes daily. Performing similar tasks repeatedly wastes time, resources, and effort. An ELT tool should have automation and orchestration capabilities so that you can schedule integration and transformation jobs easily, be it a simple data flow or a complex workflow.
- Connectivity to Multiple Data Sources
ELT jobs become easier when a tool offers native connectivity to various sources and destinations. Before purchasing a tool, look at the library of connectors it supports. Ideally, an ELT tool should have native connectivity to popular cloud data bases and storage platforms such as Amazon S3, Azure Blob, Snowflake, and Amazon Redshift amongst others.
Building ELT Pipelines with Astera
Astera is a code-free data integration tool with a powerful ETL/ELT engine. With Astera’s ELT or pushdown optimization mode, you can push down the transformation logic to the source or target database when they reside on the same server. Here is why Astera is the perfect ELT solution:
- Support for various cloud platforms, such as Snowflake, Redshift, Amazon S3, and Blob storage, making it a perfect fit for cloud environments.
- Two pushdown modes: partial and full pushdown. Astera’s intelligent algorithm decides which of the two best suits a job’s performance.
- The ELT mode executes automatically generated SQL queries on the destination.
- Native SQL support for transformations, including join, aggregate, union, route, switch, various types of lookups, and database writing strategies.
Minimize The Time To Build ELT Pipelines With Astera
Astera utilizes a no-code drag-and-drop interface, workflow and dataflow scheduling and automation and connective support to all the popular databases and cloud platforms – making building ELT pipelines easy and superfast!
Try it out now! – Free for 14 days
Astera’s ELT functionalities, coupled with powerful workflow automation and orchestration capabilities, accelerate data integration of large volumes of data while minimizing latency. With Astera, you can harness the power of ELT and optimize the performance of even the most complex data flows.
You can download Astera’s 14-day free trial today to integrate enormous volumes of data at incredible speeds.
Authors:
Mariam Anwar


