Astera AI Agent Builder Coming Soon
Astera AI Agent Builder Coming Soon Apr 29th | 11 AM PT
Apr 29th | 11 AM PT

The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

What is an ETL Pipeline? A Comprehensive Guide
What is an ETL Pipeline?
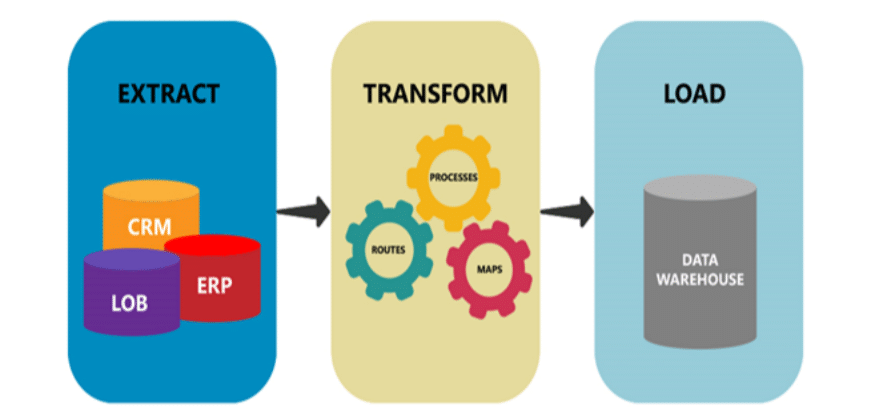
An ETL pipeline is a set of processes and tools that enables businesses to extract raw data from multiple source systems, transform it to fit their needs, and load it into a destination system for various data-driven initiatives. Therefore, an ETL pipeline is a type of data pipeline that includes the ETL process to move data. The target system is most commonly either a database, a data warehouse, or a data lake.
ETL pipelines are crucial for maintaining data quality during data integration and, ultimately, enabling organizations to make informed decisions based on a unified and well-organized dataset.
ETL Pipeline Example
ETL pipelines are all about transforming the data to meet the requirements of the target system. For example, your website could have data spread across various databases, including customer information, order details, and product information. To ensure that the data is consistent with the destination, you will need to transform the data—typically using ETL tools.
Transformation usually involves cleaning the data, enriching it for additional context, removing duplicates, etc. Once your data is in the required format, it moves along the ETL pipeline and is loaded into the destination tables. This centralized website data with a consistent format allows you to conduct accurate data analysis and make better, more informed decisions.
Looking for the best ETL Tool? Here's what you need to know
With so many ETL Pipeline Tools to choose from, selecting the right solution can be overwhelming. Here's a list of the best ETL Pipeline Tools based on key criteria to help you make an informed decision.
Learn More
ETL vs. ELT Pipeline
ETL and ELT (extract, load, transform) pipelines are similar in the context that both involve data extraction, transformation, and loading. However, the primary difference between an ELT and ETL pipeline is the sequence of the transformation and loading steps. The choice between ETL vs. ELT depends on factors such as data volume, structure, and the capabilities of the target storage and processing systems.
ETL pipeline extracts data from different sources and then stores it in a staging area where you can apply complex transformations. Only once the data is transformed can it be moved from the staging area to a target database or data warehouse. Use an ETL pipeline when you need to cleanse, enrich, or aggregate data before it reaches its final storage, ensuring that the data in the destination is already refined and ready for analysis. ETL pipelines are often preferred when dealing with structured data and when the target system requires a specific format.
On the other hand, an ELT pipeline is geared towards loading data into the destination system as quickly as possible. The data is then transformed using the destination system’s processing capabilities when required. An ELT pipeline is well-suited for big data scenarios where the target system, such as a cloud data warehouse, is capable of handling large-scale transformations efficiently. ELT pipelines are more flexible in dealing with raw or semi-structured data and leverage the computational power of modern data warehouses for on-the-fly transformations during analysis.
ETL Pipeline Components
The following key components are characteristic of a typical ETL pipeline:
Data sources
Data is pulled from different sources, such as databases, APIs, files (PDFs, CSV, JSON, etc.), cloud storage, or any other storage system. To be able to extract relevant data accurately, your data team needs to be up to date on the data formats, schema types, and the relationships.
Data extraction
Data extraction is the process of retrieving data from various data sources. Given the disparate nature of sources, the process involves reading data from different formats and structures. Some key considerations during extraction include data structure and size, frequency of extraction, and data consistency and quality.
Data transformation
The extracted data undergoes transformation to make it suitable for analysis. Data cleansing, normalization, aggregation, and filtering are some of the most common steps necessary at this stage of an ETL pipeline.
Data loading
An ETL pipeline typically terminates with loading data into the destination system, such as a data warehouse, where data becomes readily accessible for business intelligence (BI) and analytics. Your data teams will either load data incrementally or do a full load, depending on requirements.
Target system
This is the final storage location where your data resides. The target system will depend on your use case, data size, and query performance requirements.
Orchestration
An ETL pipeline must be scheduled and managed in a way that all data movement tasks are taken care of in the desired manner. Workflow automation and orchestration execute these tasks at the right time and in the right order to deliver data timely.
ETL Pipeline vs. Data Pipeline
ETL pipelines are a subset of data pipelines. While both pipelines move data from source to target systems, what separates an ETL pipeline from a data pipeline is that a data pipeline doesn’t always involve data transformation. In fact, you can say that an ETL pipeline is a type of data pipeline that involves data extraction, transformation, and loading as the core processes.
The table below summarizes the ETL pipeline vs. data pipeline:
| ETL Pipeline | Data Pipeline | |
|---|---|---|
| Focus | Emphasizes data extraction, transformation, and loading processes. | Focuses on data movement. It may or may not involve data transformation. |
| Purpose | Extract data from various sources, transform it, and load it into a destination for analysis. | The end goal is to transport data efficiently. |
| Processes | Extraction, transformation (data cleansing, normalization, etc.), and loading into a target system. | Data movement, organization, and structuring. |
| Scope | Specifically deals with processes related to ETL. | Has a much broader scope, covers a range of data handling tasks. |
| Data Transformation | Involves significant data transformation to make it suitable for analysis. | May involve minimal transformation, mainly for organization. |
Build Fully Automated ETL Pipelines in Minutes
Building and maintaining ETL pipelines does not have to be complex or time-consuming. Astera offers a 100% no-code solution to build and automate ETL pipelines.
Learn More
Benefits of ETL Pipelines
ETL pipelines make data more accessible, especially when built and maintained via ETL pipeline tools. The following benefits together contribute to improved decision-making:
Integrated Data
Your data resides in various formats across databases, spreadsheets, and cloud storage. One significant advantage of ETL pipelines is that they bridge the gap between different data repositories. These data pipelines extract relevant data, transform it into a consistent structure, and load it into a destination where it can be seamlessly integrated with existing datasets. In essence, ETL pipelines break down data silos and lead to a unified view of company-wide data, whether in traditional relational databases or scattered across cloud-based platforms.
Enhanced Data Quality
ETL pipelines can be used to identify and rectify discrepancies in your data. The “T” in ETL pipelines stands for transformation, and this step facilitates data quality management. Through predefined rules and algorithms, the transformation phase addresses issues such as missing values, duplicate entries, and format inconsistencies. Transformation not only cleanses the data but also enriches and standardizes it, ensuring uniformity that is essential for robust analytics and decision-making.
High Compatibility
As your business evolves, so do your data needs. ETL pipelines are designed with a modular and scalable architecture that enables you to incorporate new data sources. This adaptability ensures that the ETL framework remains compatible with emerging technologies and diverse data formats. Furthermore, the transformative nature of the ETL pipelines allows for the modification of data formats and structures to meet evolving analytical needs. For example, ETL pipelines continue to incorporate newer data storage systems, such as data lakes, for data consolidation.
Regulatory Compliance
The transparency and traceability inherent in ETL pipelines contribute significantly to regulatory compliance. These pipelines often incorporate features that allow you to track and audit the entire data lifecycle and provide a comprehensive record of data lineage. Data lineage is invaluable in regulatory audits, where organizations are required to demonstrate the integrity and security of their data processes.
Automation
Automated ETL pipelines serve as a robust strategy for minimizing the risk of human errors, especially since manual data handling is inherently susceptible to inconsistencies due to oversights and inaccuracies. The automation of repetitive and time-consuming tasks, such as data extraction and transformation, also enables you to streamline workflows and allocate resources more strategically. It accelerates the pace at which you process data while reducing operational costs associated with manual labor.
Take The First Step To Building ETL Pipelines. 100% No-Code!
Astera empowers users to build and maintain high-performance ETL Pipelines without writing a single line of code. Download a 14-day free trial and start building your ETL Pipelines.
Download Trial
ETL Pipeline Use Cases
Data Warehousing: Loading data from multiple operational systems into a central data warehouse is a classic ETL pipeline use case. It enables you to prepare and consume data for analytics and reporting.
Data Migration: ETL pipelines facilitate data migration from one source system to another where it is temporarily stored for further processing, or a final destination for consumption.
Data Integration: Businesses frequently use ETL pipelines to integrate company-wide data and build a single source of truth (SSOT).
Business Intelligence: It includes leveraging ETL pipelines for business intelligence (BI) by connecting them directly to BI tools, such as Power BI, and generating insights.
Legacy System Modernization: In this scenario, ETL pipelines play a critical role in streamlining the transition. They allow organizations to incorporate modern systems into their technology and data stack without losing valuable historical data.
How to Build an ETL Pipeline
There are two ways to build an ETL pipeline—you can either write code using languages like Python or use a dedicated ETL tool, such as Astera. The choice between writing custom code and using an ETL pipeline tool depends on various factors, such as the complexity of your ETL pipelines, the scale of your data, the required flexibility, and the skill set of your team.
Building an ETL Pipeline: Python
Python ETL pipelines provide flexibility and customization as you can tailor the process to your specific needs by modifying the ETL script. So, this method is suitable when have a team with strong Python programming skills and experience, you require greater control over your data sources, or when you regularly deal with complex data transformations. Here is a high-level view of the process of building an ETL pipeline using Python:
- Define Requirements: Identify the data sources you need to extract data from, the required transformation logic to make it consistent, and the destination where the processed data will be stored.
- Install Necessary Libraries: Ensure you have the required Python libraries installed, such as Pandas for data manipulation and transformation, and any database connectors if needed.
- Extract Data: Write code to extract data from data sources such as databases, APIs, file formats, etc.
- Transform Data: Apply necessary transformations to the extracted data. Use Pandas or other libraries to clean, filter, and manipulate the data as required.
- Load Data: Write code to load the transformed data into the destination system.
- Schedule and Automate: Implement scheduling to automate your ETL pipelines. You can use tools like Apache Airflow or create your own scheduling mechanism using Python cron jobs.
- Logging and Monitoring: Implement logging to track, debug and monitor your pipeline’s health.
- Error Handling: Make sure to include error handling mechanisms to deal with issues during extraction, transformation, or loading. These mechanisms protect your pipelines and allow them to recover from failures.
- Testing: Test your ETL pipeline thoroughly with different scenarios and edge cases to ensure its reliability.
- Documentation: Document your ETL pipeline, including details about data sources, transformation logic, and destination. Documentation makes it easier for others to understand and maintain the pipeline.
The downside to this manual method is that it requires more development effort and time. Writing custom Python code for ETL pipelines means that you have to handle all aspects of the process, including data extraction, transformation, and loading, as well as error handling and monitoring. Unlike dedicated ETL pipeline tools with graphical interfaces, custom Python code might not be as user-friendly for non-technical users involved in designing or monitoring ETL workflows.
Simplify Data Integration with No-Code ETL Pipelines
Astera empowers you to combine all your data, whether on-premises or in the cloud. Sign up for a free demo and see what it takes to build and maintain ETL Pipelines in a no-code environment.
View Demo
Building an ETL Pipeline using No-Code Tools
Dedicated ETL pipeline tools, such as Astera Data Pipeline Builder, come with graphical interfaces and pre-built connectors and transformations, making it easier to design and manage ETL workflows without coding. Once you’ve decided on a tool, the next step is to build the ETL pipeline.
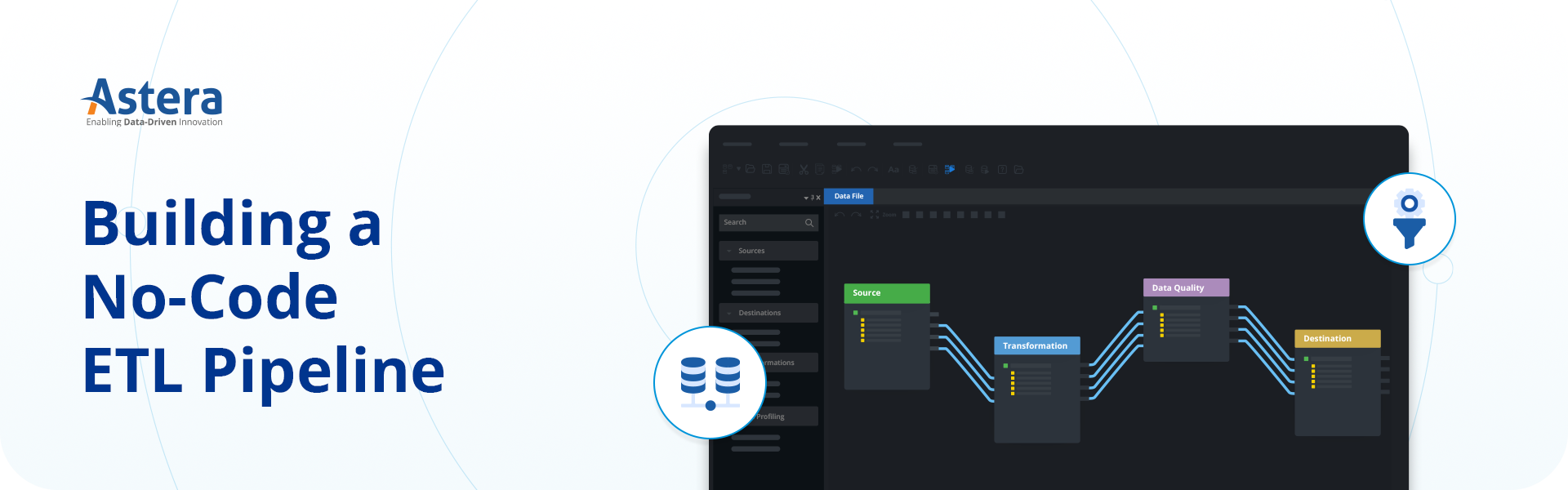
Building an ETL Pipeline using Astera Data Pipeline Builder
While the specific steps can vary depending on the actual tool, the high-level process remains the same:
- Connect to Data Sources: Drag and drop the connectors onto the dataflow and connect to the data sources from which you want to extract data. These could be databases, APIs, flat files, or any other supported source.
- Extract Data: Use the ETL tool’s graphical interface to design the extraction process. Configure connectors and settings to pull data from the defined sources.
- Transform Data: Implement data transformations built into the ETL pipeline tool. These might involve applying filters, aggregations, or other transformations to clean and prepare the data for the destination.
- Connect to the Destination: Specify and establish connectivity to the destination where the transformed data will be loaded. ETL tools feature capabilities like AI auto data mapper to make the process effortless.
- Configure Loading Process: Use the ETL tool to configure the loading process. Define how the transformed data will be written to the destination, including any formatting or schema considerations. You can also configure whether the data will be loaded in batches, as well as the size of the batches.
- Schedule and Automate: Set up scheduling to automate the execution of your pipeline. Define when and how often the pipeline should run. The ETL pipeline can be configured to run at specific intervals or events, such as when an e-mail is received or a file is dumped into a folder.
- Error Handling and Logging: Configure error handling mechanisms within the ETL tool. Define how the tool should handle errors during extraction, transformation, or loading. You can also implement logging to track the execution and identify issues.
- Test the Pipeline: Thoroughly test the ETL pipeline with sample data to ensure that it functions as expected. Verify that data is extracted, transformed, and loaded accurately.
- Deployment: Deploy the ETL pipeline to your production environment. Monitor its performance and make any necessary adjustments.
Using an automated tool can be beneficial when you need to quickly set up ETL pipelines, especially in scenarios where there’s a need to involve a non-technical user or a business professional in designing, using, maintaining, or monitoring the pipeline. Additionally, custom code requires ongoing maintenance—you’ll need to update and test the code every time there are changes in data sources, transformation logic, or destination formats.
Take The First Step To Building ETL Pipelines. 100% No-Code!
Astera empowers users to build and maintain high-performance ETL Pipelines without writing a single line of code. Download a 14-day free trial and start building your ETL Pipelines.
Download Trial
ETL Pipeline Best Practices
Promote Modularity: Design modular and reusable components in your ETL pipeline. Breaking down the process into reusable components, each responsible for a specific task, makes the overall system more flexible and easier to manage. The modular approach simplifies updates to individual components without affecting the entire ETL pipeline, fostering consistency across the workflow.
Implement Incremental Loading and CDC: If you don’t deal with real-time data streaming, consider implementing incremental loading and change data capture (CDC) to process only the changed data. It enables you to reduce processing time and unnecessary resource utilization. This technique is particularly effective for large datasets where processing the entire dataset in each run is not practical.
Optimize Performance: You can employ several strategies to optimize the performance of your ETL pipelines. For example, consider partitioning and parallelizing data processing tasks to distribute the workload across multiple resources and enhance overall speed. Utilize indexing and proper data structures to expedite data retrieval and transformation processes. Additionally, you can leverage caching mechanisms to store and reuse intermediate results and reduce redundant computations.
Implement Error Handling and Logging: Enable swift identification and resolution of issues during data processing via error handling. Comprehensive logging provides insights into the pipeline’s behavior, facilitating troubleshooting and auditing processes. This tandem approach enhances the reliability and maintainability of the ETL pipelines.
Metadata Management: Organize and document metadata about data sources, transformations, and destinations to track changes and dependencies within your ETL pipeline. Metadata management enhances traceability and simplifies the process of understanding the lineage of data. This, in turn, makes it easier to troubleshoot issues, ensure data quality, and implement changes.
Astera—The No-Code Way to Build Automated ETL Pipelines
Astera Data Pipeline Builder is a 100% no-code solution for building fully automated ETL pipelines. Whether your data is on-premises or in the cloud, Astera empowers you to combine and move it to the destination of your choice. Astera offers native connectivity to a range of data sources and destinations with its pre-built connectors, including Amazon Redshift, Google BigQuery, Snowflake, Microsoft Azure, etc.
With Astera, you can:
- Build fully automated ETL pipelines
- Accelerate data mapping with AI Auto Mapper
- Connect to multiple data sources and destinations
- Improve the quality of your data for a reliable single source of truth
- Handle large volumes of data effortlessly with a parallel processing ETL engine
And much more—all without writing a single line of code. Ready to build end-to-end ETL pipelines with a 100% no-code data pipeline builder? Download a 14-day free trial or sign up for a demo. Alternatively, you can get in touch with our data solution experts directly at +1 888-77-ASTERA.
What is Astera Data Pipeline Builder?
What is ETL?
What are ETL pipelines?
What is an ETL data pipeline?
Is integrating data the same as building ETL pipelines?
What is a reverse ETL pipeline?
Authors:
Khurram Haider