 Astera AI Agent Builder Coming Soon
Astera AI Agent Builder Coming Soon Apr 29th | 11 AM PT
Apr 29th | 11 AM PT

The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.
How Automated Financial Data Integration Streamlines Fraud Detection
Do you know proactive fraud detection and prevention could save organizations up to a staggering $5.9 billion annually? However, gathering relevant data for this purpose is no easy task. Financial data integration plays a crucial role in the fight against fraud, enabling organizations to merge data from various sources and formats into a unified, consistent view.
However, gathering relevant data for this purpose is no easy task. Financial data integration faces many challenges that hinder its effectiveness and efficiency in detecting and preventing fraud.
Challenges of Financial Data Integration
Data Quality and Availability
Data quality and availability are crucial for financial data integration project, especially detecting fraud. Fraudsters often exploit data quality issues, such as missing values, errors, inconsistencies, duplicates, outliers, noise, and corruption, to evade detection and carry out their schemes.
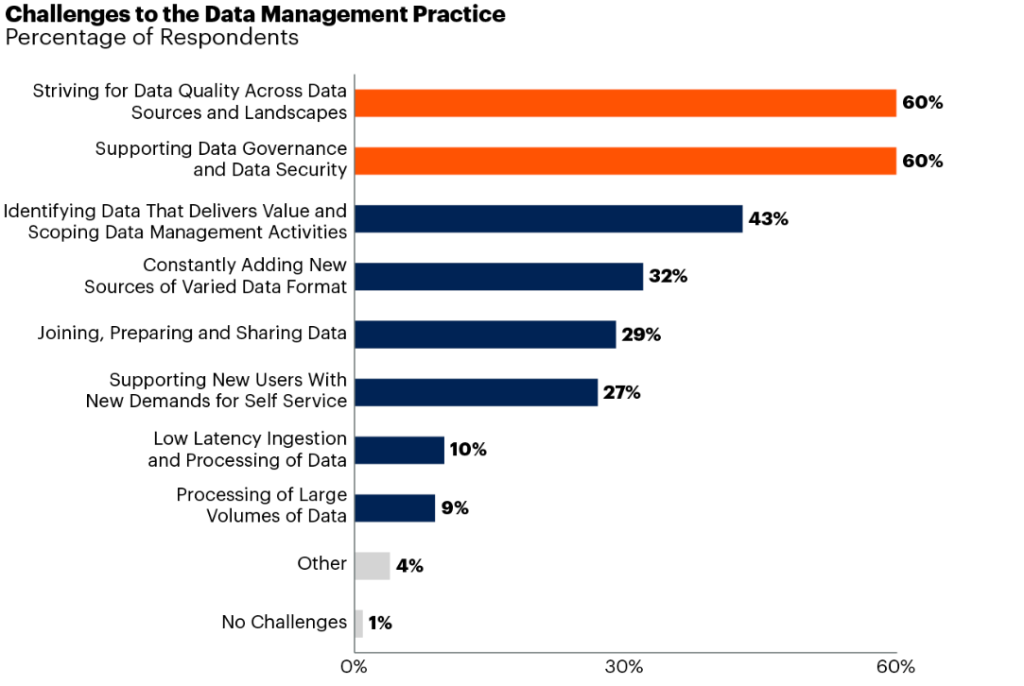
According to Gartner, 60% of data experts believe data quality across data sources and landscapes is the biggest data management challenge.
Additionally, some data sources may be hard to access, unreliable, or outdated, which may compromise the completeness and timeliness of the financial data integration process.
Therefore, data quality management is essential to ensure that the data is accurate, consistent, and reliable. Data quality management involves various techniques, such as data cleansing, validation, verification, and reconciliation, to identify and resolve data quality problems. Data quality management can have significant benefits for organizations, such as:
- Reducing wasted resources lost revenue, and increased risk. According to a survey by Experian, 95% of organizations see negative impacts from poor data quality, such as increased costs, lower efficiency, and reduced customer satisfaction.
- Saving money and boosting the economy. According to a report by IBM, poor data quality costs the US economy $3.1 trillion a year, which is equivalent to 17% of the US GDP. Improving data quality can help reduce these losses and increase productivity and innovation.
- Enhancing data governance and customer insights. According to a study by SAS, only 35% of organizations have a well-established data governance framework, and only 24% have a single, integrated view of customer data. Data governance is the process of defining and implementing policies, standards, and roles for data management. Data governance can help improve data quality, security, and compliance, as well as enable better decision-making and customer service.
Data Integration and Transformation
The financial data integration process consists of two core tasks: extracting data from multiple sources and converting it into a unified and consistent view. These tasks are challenging, as they involve various issues, such as:
- Data heterogeneity: Data sources may have different structures, formats, and semantics, which need to be reconciled and aligned.
- Data mapping: Data sources may have different identifiers, values, and units, which need to be translated and standardized.
- Data transformation: Data sources may have different quality, granularity, and complexity, which to be cleaned, validated, aggregated, filtered or transformed in any other way.
- Data consolidation: Data sources may have redundant, conflicting, or missing data, which need to be resolved and integrated.
- Data integration testing: Data sources and transformations may have errors, bugs, or anomalies, which need to be detected and corrected.
These tasks also require high performance and efficiency, as they may deal with large volumes and varieties of data. According to a report by Gartner, data integration and transformation account for 60% of the time and cost of data warehouse projects.
How Automated Data Pipelines Assist in Financial Data Integration for Fraud Detection
Automated data pipelines enable the creation, execution, and management of financial data integration workflows without requiring extensive coding or manual intervention. They offer many features that make financial data integration for fraud detection easier:
- Drag-and-drop interface: Automated data pipelines provide a user-friendly and intuitive drag-and-drop interface that allows users to design and configure financial data integration workflows with ease and flexibility. Users can simply drag and drop pre-built data sources, transformations, destinations, and other components onto a graphical canvas and make mappings to create customized data pipelines. Users can also customize the properties and parameters of each component and preview the results of each step.
- Connectivity to a diverse range of sources: Automated data pipelines support connectivity to a diverse range of data sources, such as databases, structured and unstructured files, web services, cloud platforms, and applications. Users can easily access and extract data from various sources regardless of their location, format, or structure. Users can also use pre-built connectors or create custom connectors to integrate with any data source.
- Pre-built transformations: Automated data pipelines offer a rich set of pre-built transformations that can perform various data manipulation and processing tasks, such as data cleansing, data validation, data conversion, data aggregation, data filtering, data sorting, data joining, data splitting, data pivoting, and data enrichment. These transformations help address errors, ensure conformity, facilitate interoperability, provide summaries, focus on relevant subsets, organize data, integrate diverse sources, extract specific information, restructure for different perspectives, and augment datasets with additional context. Users can also create custom transformations, write expressions, or use scripting languages to perform complex or specific data transformations.
- Data quality management: Automated data pipelines facilitate data quality management, which is the process of ensuring that the data is accurate, complete, consistent, and reliable. Data quality management involves various tasks, such as data profiling, data cleansing, validation, verification, reconciliation, and auditing.
- Workflow automation: Automated data pipelines enable workflow automation. This allows users to not only create self-regulating data pipelines, but automate tasks that typically require manual interference.
- Change data capture (CDC): Automated data pipelines support change data capture (CDC), which is the process of capturing and transferring only the changes made to the data sources rather than the entire data sets. CDC is useful for financial data integration for fraud detection, as it enables the detection of fraud in near real-time and reduces the data volume and latency.
- Managed file transfer (MFT): Automated data pipelines support managed file transfer (MFT), which is the process of securely and reliably transferring files between different systems and locations. MFT is useful for financial data integration for fraud detection, as it enables the exchange of data with various stakeholders, such as customers, partners, vendors, and regulators.
- Security: Automated data pipelines ensure security, allowing you to protect the data and the data integration workflows from unauthorized access, use, modification, disclosure, or destruction. Security is vital for financial data integration, as it involves sensitive and confidential data that may have legal or regulatory implications.
Protect Yourself Against Fraud using Astera’s Automated Data Pipeline Builder
Astera’s Automated Data Pipeline Builder simplifies the Financial Data Integration process using a super-simple no-code drag-and-drop interface.
Book Your Free Trial Now!
Best Practices and Tips for Optimizing and Troubleshooting Financial Data Integration
Optimize Data Sources
You must take some strategic measures to improve your data sources. First, you should refine your selection process and opt for only relevant data fields. Second, you should use filters to exclude irrelevant information and reduce overall data volume.
For instance, in the analysis of credit card transactions, you should focus on essential data fields like transaction amount, date, time, location, merchant, and customer. To further streamline, you should consider excluding transactions falling below a specific threshold or those from trusted sources through the application of targeted filters.
This not only trims unnecessary data but also directs attention to transactions with a higher likelihood of being fraudulent. Third, you should employ techniques such as indexing and partitioning the data tables based on transaction date, time, or location. This can boost data retrieval performance and expedite fraud detection.
Leverage Data Transformations Efficiently
You need to make thoughtful choices in both method and mode to efficiently leverage data transformations. You can consider in-memory, pushdown, bulk, and parallel processing options. To streamline the process, you should avoid unnecessary or redundant transformations and enhance performance by implementing caching and buffering techniques during data processing.
For instance, if you’re consolidating data from multiple sources, it’s advisable to conduct transformations within the source or target system, opting for pushdown/ELT processing. Doing so minimizes data movement, reduces latency, and boosts overall processing speed.
Moreover, if your data types, formats, or units are already consistent across sources, you should skip unnecessary transformations. To further enhance performance and prevent redundant operations, you should store intermediate transformation results in memory or on disk using caching and buffering techniques.
Automate Data Mapping
Automating data mapping can help you save considerable time and effort and create complex expressions for data mapping. One of these features is the auto-mapping feature, which can automatically map your data elements if they have the same or similar names. This feature helps you reduce human errors and speed up the process.
You can also leverage the expression mapping feature to create complex expressions for data mapping, such as concatenating, splitting, or calculating data elements. This can help you create new and useful data elements. For example, you can create a unique identifier for the customer by concatenating their first name and last name.
In addition, you can use some features that can help you map your data elements based on a lookup table or a similarity score. One of these features is the lookup mapping feature, which can map your data elements based on a reference table that contains the list of valid or invalid merchants or customers. This can help you identify and flag transactions that involve suspicious parties.
Another feature is the fuzzy mapping feature, which can help match similar strings. This can help you deal with data elements that are not the same but close enough, such as misspelled or abbreviated names.
Enhance Data Quality
Data quality is important for fraud detection, as it affects the accuracy, consistency, and reliability of the data. To optimize the data quality, you can use various tools and techniques, such as:
- Data quality rules: These are rules that check and enforce the data quality standards, such as completeness, uniqueness, validity, consistency, and accuracy. You can use the pre-built data quality rules or create your own data quality rules by using the data quality wizard or the data quality editor. For example, you can create a data quality rule that checks if the transaction amount is within a reasonable range and, if not, rejects or flags the transaction as potentially fraudulent.
- Data quality reports: These reports illustrate the data health of a particular dataset. You can use the data quality reports to visualize and communicate the data quality status and trends and to support data quality analysis and decision-making.
- Data quality alerts: These are alerts that receive notifications and alerts when the data quality rules are violated and take appropriate actions, such as correcting or discarding the data or notifying the data owners or stakeholders. You can use the data quality alerts to ensure data quality compliance and accountability and to prevent or mitigate data quality risks.
Load and Sync Data Optimally
Data destination is important for fraud detection, as it affects the delivery and storage of the data. To optimize the data destination, you can choose the most suitable and efficient options, such as:
- Destination type and format: These are the type and format of the data destination, such as the database, the file, web services such as APIs, the cloud platform, or the application. You can choose the destination type and format depending on the data usage and consumption. For example, you can consume APIs as a data source to access real-time data required for fraud detection.
- Load mode: This is the mode of loading the data to the data destination, such as the full load, the incremental load, the upsert, or the insert. You can choose the load mode depending on the data volume and frequency. For example, if you want to load the complete data from the source to destination, you can choose full load. If you want to load it incrementally since the last load, you can choose incremental load. If you want to insert new records in the destination database, choose insert. If you want to insert new records in case they don’t exist in the database and update records in case they do exist, we would choose upsert. Note that incremental-load/full load are not alternatives of upsert/insert. The choice between incremental and full load is separate from that of insert and upsert.
- Change data capture (CDC): This is a feature that captures and transfers only the changes made to the data sources rather than the entire data sets. You can use the CDC feature to reduce the data transfer and storage costs, and to improve the data freshness and timeliness for fraud detection.
Configure Workflow Automation
Enhancing workflow automation ensures your data pipeline workflow is optimized for fraud detection. You can configure workflow triggers based on pre-defined frequencies or events, such as data arrivals, changes, quality violations, or fraud alerts. This feature helps you activate and respond to changes that affect fraud detection processes. For instance, you can use this feature to start a workflow when a new file arrives in a folder, when a data quality rule is violated, or when a fraud alert is generated by another system or application.
Once the workflow is established, you must monitor the pipeline. You need to set up metrics to review your pipeline’s performance. For instance, you should monitor how long your data pipeline workflow takes to run, how many records it processes, how many errors or warnings it encounters, and how many actions it performs. You can also use this feature to optimize your data pipeline workflow by changing the parameters, variables, or settings, as needed, to improve the data processing speed, accuracy, and reliability for fraud detection.
Configure Workflow Log
If you’re creating a fraud detection workflow, it’s essential to configure, view, and export the log of your data pipeline using filters, preview, and export functions. This helps you review and analyze the details and history of your data pipeline workflow, and to support your data pipeline workflow audit and evaluation. For instance, you can use this feature to see the start and end time of your data pipeline workflow, the parameters and variables used, the input and output data sets, the data quality rules applied, and the data destination details.
You can also use this feature to optimize your data pipeline workflow by checking the data pipeline workflow execution and results and by finding and correcting any data quality issues for fraud detection.
Set Up Alerts
Your data pipeline needs to send you notifications and alerts when the workflow is completed or failed, using email, SMS, or push notifications. This makes sure that your data pipeline workflow is finished and successful, and to take appropriate actions, such as correcting or discarding the data or notifying the data owners or stakeholders in case of any failures or errors.
For instance, you can use this feature to receive an email, an SMS, or a push notification when your data pipeline has executed successfully or run into an error and to see the summary and status of your data pipeline.
You can also use this feature to optimize your data pipeline by reducing the data pipeline latency and downtime and by improving the data pipeline responsiveness and reliability for fraud detection.
Optimize Exception Handling
Exception handling helps you resolve errors and exceptions that occur during your data pipeline using error codes, error messages, and error actions.
You can use this feature to troubleshoot and fix the errors and exceptions and to prevent or reduce the data pipeline risks and impacts. For example, you can use this feature to see the error codes and error messages that explain the cause and type of the errors and exceptions and to perform the error actions that tell you the steps and solutions to resolve the errors and exceptions.
You can also use this feature to optimize your data pipeline by avoiding or minimizing the data pipeline failures and errors and by enhancing the data pipeline quality and security for fraud detection.
Workflow Recovery
This feature lets you recover and resume your data pipeline workflow from the last successful point using checkpoints, snapshots, and rollback functions. You can use this feature to restore and continue your data pipeline workflow and to avoid losing or repeating any data or work. For example, you can use this feature to see the checkpoints and snapshots that save the state and progress of your data pipeline workflow and to use the rollback function to go back to the last successful point. You can also use this feature to optimize your data pipeline workflow by preserving and recovering the data pipeline workflow data and work and by improving the data pipeline workflow efficiency and continuity for fraud detection.
How Astera Enables Financial Data Integration
Financial data integration for fraud detection requires careful planning and execution. With the help of automated data pipelines, such as Astera Automated Data Pipeline Builder, you can achieve data integration for fraud detection with ease and efficiency.
Automated data pipelines assist in financial data integration for fraud detection in several ways, such as a drag-and-drop interface, connectivity to a diverse range of sources, pre-built transformations, data mapping, data quality management, workflow automation, CDC, MFT, security, and analytics add-on.
Astera automated data pipeline builder is a powerful tool that can help you streamline financial data integration. With Astera, you can:
- Connect to various data sources and destinations, such as databases, files, APIs, cloud services, and more without writing any code.
- Transform and enrich your data with built-in functions, expressions, and business rules using a drag-and-drop interface.
- Automate and schedule your data pipelines to run on-demand or at regular intervals with advanced error handling and monitoring features.
- Monitor and manage your data pipelines with real-time insights and alerts.
Whether you need to integrate your financial data for reporting, analysis, compliance, or other purposes, Astera can help you achieve your goals faster and easier.
If you want to see how Astera can work for your specific use case, you can sign up for a free 14-day trial or schedule a custom demo with our experts. Don’t miss this opportunity to take your financial integration to the next level with Astera!
Authors:
Fasih Khan



