 Astera AI Agent Builder - First Look Coming Soon!
Astera AI Agent Builder - First Look Coming Soon! Apr 29th | 11 AM PT
Apr 29th | 11 AM PT

The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

Here’s Why You Need a PDF Extractor
A PDF extraction software can help you convert unstructured data in PDF files to clean, structured data that can be stored in a data warehouse for reporting and business intelligence. The Portable Document Format files (PDFs) are easy to share and view, and they maintain their integrity across all platforms (Windows, macOS, Linux, etc.) As a result, they make up a bulk of sales invoices, legal documents, and other official business documents across the corporate arena.
Despite the fact that PDF file formats hold great business insights, they are not ideally set up for reporting and analysis, i.e., they are unstructured files, so data extraction tools are needed to turn these documents into insight generators.
Data Extraction from PDFs
Extracting data from PDF files is an integral part of the data management workflow. It allows organizations to turn raw, unstructured text in documents into structured data to maintain a centralized data repository for reporting and analysis. However, it’s not a walk in the park because the data in PDFs is not structured, i.e., neatly arranged in columns and rows. PDF extractors use scanned images of pages from the file and perform optical character recognition to extract text from them.
Data Extraction from PDFs: What are Your Options?
When it comes to data extraction from PDF documents, the first instinct is simply hand-keying the data into the systems. That’s fine if you have a couple of documents. But when processing hundreds and thousands of files every day, it becomes a far less viable option even for mid-sized companies.
Let’s compare manual data entry with some of the other available options for data extraction from PDF documents:
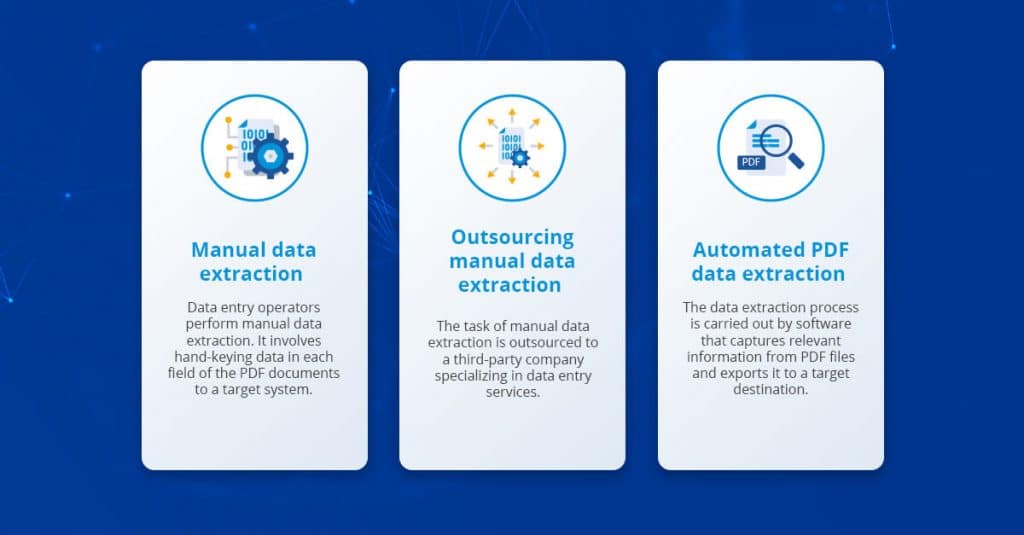
- Manual data extraction is costly, repetitive, and time-consuming. It’s an impractical option for processing large volumes of data. It’s also prone to human errors, which affect data quality.
- Outsourcing can minimize data extraction costs and speed to a certain extent; however, it poses serious data security and quality control concerns that offset these benefits.
- Automated data extraction is the fastest and most efficient way to capture data from PDF files. Modern PDF extractors can process thousands of documents in seconds.
Boost Productivity with Code-Free PDF Extraction
Transform unstructured data into actionable insights effortlessly. With Astera ReportMiner's no-code platform, you can extract data from various sources and streamline your workflows.
Explore Now
AI-Centric Data Extraction vs. Template-Based Data Extraction
There are basically two approaches to data extraction: AI-centric extraction and template-based data extraction.
AI-Centric Data Extraction
AI-centric data extraction is a novel approach in which machine learning and deep learning algorithms are used to establish relationships between datasets and scanned documents. Data scientists train models to recognize key names for key fields in business data based on user input, tag it, and then capture the relevant text from the unstructured document.
This approach offers versatility and scalability to companies and works great for conversational AI, where real-time comprehensibility and responses are required. For instance, trained chatbots can answer anticipated queries from customers very quickly. Moreover, businesses can minimize response time with context-based answers.
However, the AI-centric data extraction process requires considerable dataset training and machine learning proficiencies — as models have to be trained to understand ambiguities, context, and several complex aspects related to language detection.
A data modeler must determine the right volume of data required to train each model to ensure the accuracy and quality of algorithmic output meets the business requirements. When poorly designed or implemented, this process can lead to poor-quality data from text files.
Template-Based Data Extraction
Template-based data extraction is a proven approach to processing digitized PDF documents at scale. It involves creating a data extraction template to isolate specific text sections in the document. The pattern is specified using the position and proximity of the text in the document.
For instance, a user can specify a pattern or multiple patterns to extract data from a specified region of a PDF document. The template would look for the pattern(s) with a specific combination of alphabets, words, numeric, or alphanumeric characters specified by the user to capture information.
It requires relatively low computational capacity compared to its AI-centric counterpart and offers greater accuracy. Also, the templates can be reused for similarly structured PDF documents, making data extraction faster. This scalability is particularly useful when extracting data from large volumes of PDF files.
That said, template-based data extraction also presents some challenges. For instance, a PDF document may contain a floating field, i.e., the field location of a single row is different from the rest of the rows. In some cases, a column is misaligned due to data warping.
Modern template-based data extraction solutions are designed to tackle these challenges and create all possible patterns for seamless data capture from PDF and other unstructured files.
Key Features to Look for in a PDF Extractor
The data extraction requirements of organizations differ from one use case to another. Here are some of the top must-have features in a PDF extractor:
- Connectors to various data sources and destinations
- Automation capabilities
- Workflow orchestration
- Zero-code environment
- Easy-to-learn, intuitive user interface
Astera ReportMiner — The Automated, No-Code PDF Extractor
Astera ReportMiner is an enterprise-grade PDF extractor that automates and simplifies unstructured document processing. Its intuitive, easy-to-learn user interface seamlessly allows business users to extract valuable information from PDF documents. Users can create custom data quality rules to validate extracted data from the PDF files.
Key features of Astera ReportMiner

Automated Data Extraction: Success Stories by Astera Software
Over the years, Astera ReportMiner has helped numerous organizations save time by automating data extraction activities. Here are some success stories of clients using our PDF extractor:
Faster PDF Claims Data Management Processing for Aclaimant
Aclaimant, an advanced risk reduction and incident management system provider, uses Astera ReportMiner to quickly extract pages from PDF files. It uses ReportMiner to capture data from claim forms in PDF format and write it to Excel and CSV reports. It resulted in a 50 percent reduction in time and resources spent manually transcribing claim forms.
Read the full case study here.
Automated PDF Data Extraction for an IT Service Contractor of a Government Organization
Astera ReportMiner allows an IT Services Contractor that handles the work history information of government personnel to simplify PDF data extraction and minimize errors, saving over 1000 manual hours per year.
Read the full case study here.
Data Extraction from Customer Purchase Order PDFs within Minutes for Ciena Corporation
Ciena Corporation, a networking services, software, and equipment provider, uses Astera ReportMiner to extract key data from customer purchase order PDFs in only 2 minutes instead of hours. The company is now able to fulfill customer requests 15 times faster.
Read the full case study here.
Extract Data in a Few Simple Steps
Astera ReportMiner is a PDF Extractor which comes with an intuitive, zero-code user interface with advanced functionalities to capture data from PDF files.
1) Import a PDF File
Upload a PDF from your local or shared directory. The text in the PDF pages will display on the report model’s designer.
*ReportMiner supports various file types, including Excel, RTF, PRN, EDI, etc.
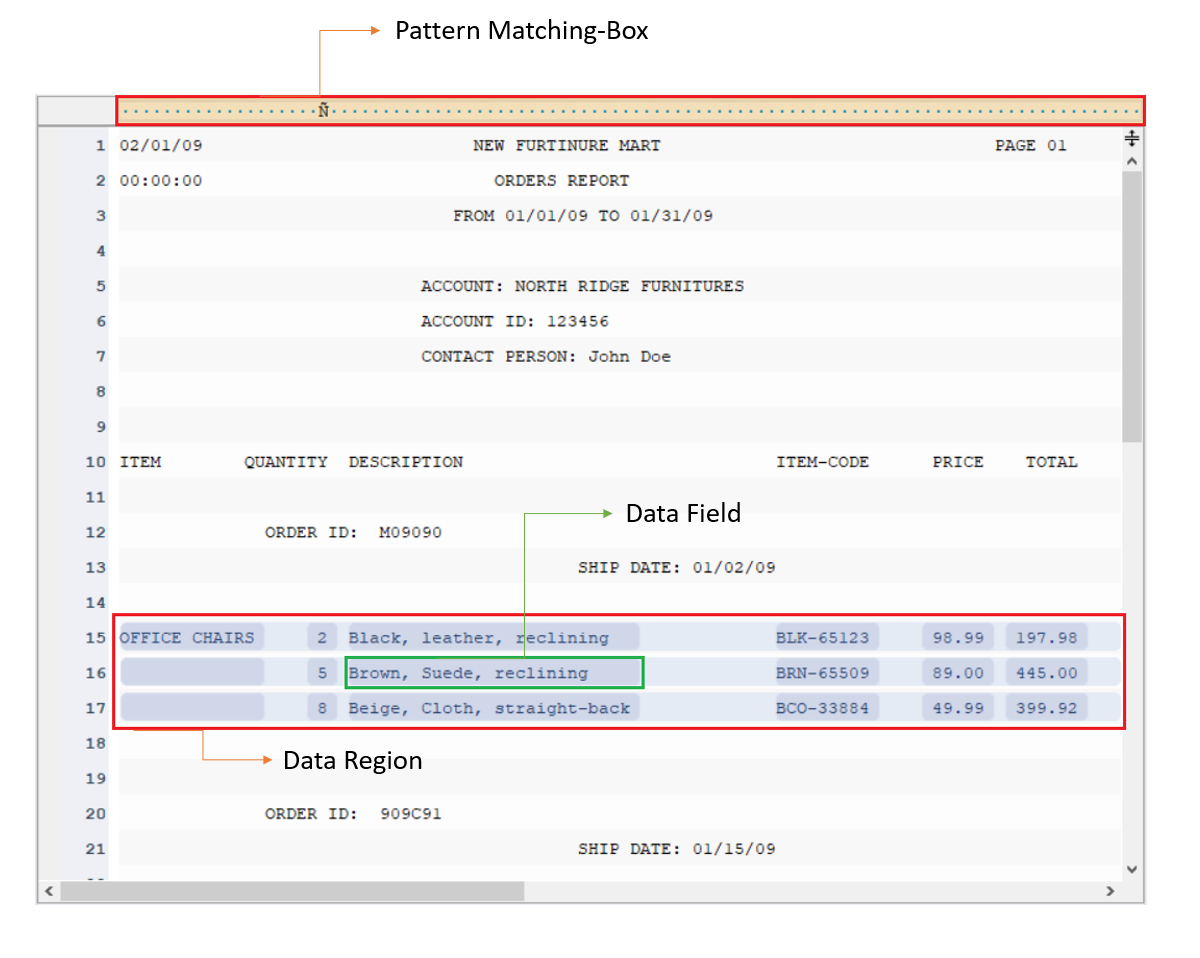
2) Create a Report Model
Using pattern box and region property panels, create a report model by selecting the datasets and pages to extract and specifying a pattern in an intuitive, no-code environment.

Specify the pattern for matching regions for the datasets in the pages you want to extract from the PDF file. Repeat the process to create more data fields to capture all the relevant information in the document.
The extraction template gives you complete control over the data extraction process. Even if you have a multiple-page document, you can capture relevant information from specific pages or a part of it.
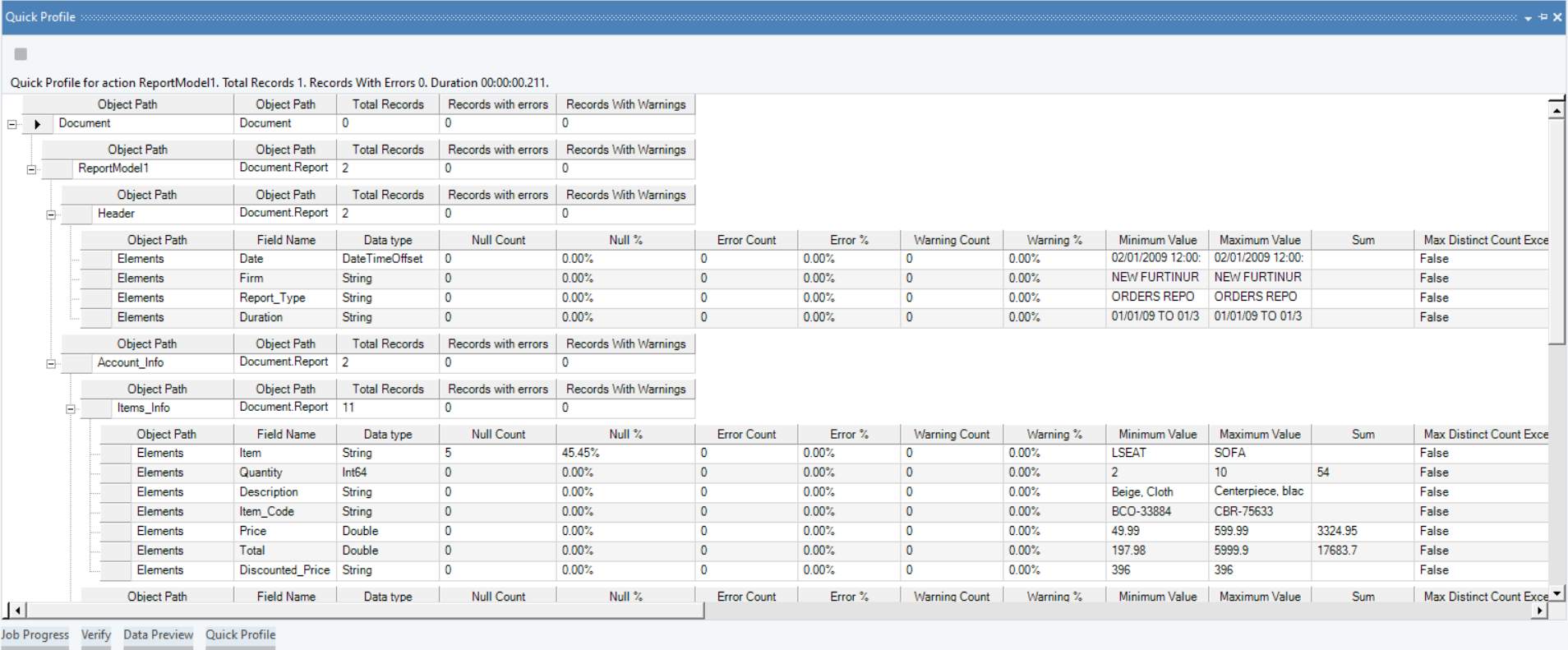
Once the data has been extracted, you can use the data preview feature to ensure the accuracy and completeness of the information.
3) Export Data to Destination
You can export the extracted data from PDF files to an Excel file, CSV, or any database of your choice, whether on-prem or on the cloud. You can also open the report model in a data flow to cleanse data and apply transformations before exporting it to your target destination.
And you’re done. In a few simple steps, you seamlessly structure the unstructured data trapped in PDF business documents.
Ready to Extract PDF Data in Minutes? Start Your Free ReportMiner Trial
Experience the speed and precision of Astera ReportMiner. Sign up for a free trial and see how quickly you can process your PDF data.
Get Started
If you’re looking for a smart and intuitive PDF data extraction tool, download a 14-day free trial of our automated data extraction solution today or call +1 888-77-ASTERA to discuss your use-case.
Authors:
Ammar Ali


