 Astera AI Agent Builder - First Look Coming Soon!
Astera AI Agent Builder - First Look Coming Soon!
The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

Traditional Approach vs. Metadata-Driven Data Warehousing

From monolithic Management Information Systems to dimensionally modeled data warehouses and data lakes, we’ve seen massive changes in how organizations collect, process, store, and analyze their data over the years. Each leap forward in technology and techniques has been guided by a conscious effort to introduce greater agility, accessibility, and scalability to their reporting and analytics.
Rightfully so, in an operating environment where customer preferences and prevailing market conditions can change instantly, enterprises often need to visualize and query data within hours to gain that crucial advantage over competitors. An agile data architecture is essential to reach that goal.
Enter the metadata-driven approach. Using Astera DW Builder, you can create comprehensive data models that integrate the design, logic, and related data mappings that make up the bulk of data warehouse development and then replicate the entire schema in a cloud or on-premises database of your choice. From there, you’re ready to populate, consume, or update your data warehouse with ease.
At the end of the day, you have a swift and responsive process built to deliver actionable insights according to your timeline. Compare our approach to how things used to be done, and you can see the advantages of metadata and the enormous value our product brings to the development process.
Why Data Warehousing Needs to Evolve
The Traditional Approach

When we talk about the traditional approach, we refer to waterfall-style development, which has dominated this space since the ’90s. In this process, the data warehouse is built in a meticulously planned sequence of phases which are as follows:
- Requirement Gathering: At this stage, the developers will meet with business analysts and other end-users to document what kind of BI is required.
- Design: After studying requirements, developers will design a prototype architecture that encompasses the physical/logical structure and data mappings required to populate and maintain
- Create Accessibility: Developers must then decide how to access the warehouse data for reporting and analysis. Data could be made available through a front-end BI platform such as PowerBI or Tableau or a custom solution built to fit the organization’s needs.
- Testing: Involves both a QA portion to identify and resolve any bugs which could hamper usability/performance. As well as user acceptance testing to ensure the data warehouse serves its stated purpose.
Your Data Warehouse isn’t a Project. It’s a Process.
The most significant limitation of the waterfall approach is that development is geared towards a finished solution presented as the answer to all of the organization’s BI requirements. This big-ticket approach fails to account for the constantly changing nature of these needs.
- While business requirements are gathered based on end-users ‘ current needs, they must also encompass any possible scenarios that could develop months or even years from now. Of course, trying to predict the future state of your business is easier said than done.
- Because there are so many hand-offs across the development process from business analysts to developers, architects, and ETL specialists, there is always the chance that requirements will be misinterpreted. As a result, the finished solution could be far from what was agreed upon initially, i.e., the Chinese Whisper
- There is also the distinct possibility that end-users might have failed to understand their requirements in the first place. They may have underestimated the data that needs to be integrated.
- Of course, as most of these issues are only identified in the testing phase, any fixes will increase the cost and timelines of the project.
Okay, But What Makes the Metadata-Driven Approach Better?
Let’s start with what we mean by the metadata-driven approach because there are many facets to how we treat data warehouse development in Astera DW Builder.
It All Starts with the Data Model
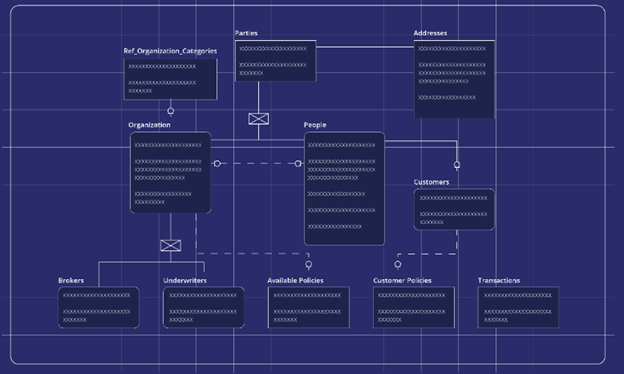
The first thing to note is that we put data modeling at the very front and center of our product. Our comprehensive, code-free data model designer allows users to design every element of their EDW in a single end-to-end process. Immediately, this removes the sequential hand-offs that characterize the waterfall approach. Instead, what you have is a seamless design process that can be initiated and managed by a single person (if required).
You’ll probably want to have technical and non-technical users involved in creating your data models, and ETL flows in practice. This sort of collaboration is intrinsically supported in our product, as all the elements required to design a data model are managed and configured at the metadata level. Whether you’re modeling your source system entities or setting up individual fact and dimension tables, all of this is possible by interacting directly with the data model using business-defined concepts.
The big advantage here is that the end-user can actually translate their conceptual requirements into a physical data model. In this case, all the entity relationships, business rules, and naming conventions are agreed upon during the design phase – rather than clarified at the end when a prototype is actually presented. Another key benefit is that as the model is built, the end-user can provide immediate feedback on any corrections that need to be made or adjust their initial requirements based on the data warehouse’s working design.
The result is a finished data model that is aligned with the organization’s needs.
Work Iteratively to Meet BI Requirements

At this stage, let’s talk about agile development and how it differs from the waterfall approach. A few fundamental values are prized in this methodology — collaboration (which we’ve covered), prioritizing functional software over precise documentation, and the ability to work quickly according to changing requirements rather than a set plan.
The latter two points are critical when discussing how the metadata-driven approach improves data warehouse development. We referenced how hard it is to create precise documentation that perfectly predicts what your BI requirements will be a year or even more from today, so why not begin working immediately on a smaller deployment that answers a current business need.
With Astera DW Builder, you get to add this kind of agility to your data warehouse. As soon as an urgent requirement is identified, your team can get to work creating a data model that reflects the underlying operational systems needed to be analyzed and a schema for the data warehouse used to query those systems. All told, the process can be completed in a matter of days or even hours. In the end, you have a functional architecture that can start delivering actionable insights to your front-end applications right away.
Of course, as these requirements evolve, you can either modify your existing models by adding new entities or fields to your data model. Or you can create an entirely new data model for a different business process that needs to be investigated in-depth. With an agile approach in place, you end up with an iterative development process that is ideal for a rapidly changing business environment.
Say Goodbye to Hand-Coding

ETL is generally the most time-consuming part of the data warehouse development as developers must ensure that any data loaded into the EDW is free of duplication or other data quality issues and that load times are minimized wherever possible. Typically, the process requires significant manual effort, with developers writing their code from scratch to suit the particulars of each data pipeline.
ADWB comes complete with a dataflow component that allows you to design these source-to data warehouse mappings at the metadata level. Starting with the array of out-of-the-box connectors that will enable you to retrieve data from flat file systems and APIs to existing source system schemas built using our data model designer with ease.
This last functionality is essential because it does away with the need to pull data directly from your operational systems, which eats up valuable compute resources on critical database servers. It also creates an additional layer of security between your transactional data and the end-user, as you can construct your data models to reflect on analysis-ready tables and records. Our product also comes with a dedicated Data Model Query builder, enabling you to create a hierarchical source table containing multiple data model entities based on existing relationships defined at the modeling stage. Again, this complex query-building requires no actual SQL. Relevant entities are selected and configured at the metadata level.
The product also has you covered when it comes to preparing and enriching your source data. The dataflow builder offers over a hundred built-in transformations that help you clean, filter, replace, parse, and validate any data moving to your data warehouse. So you can ensure that only high-quality, analysis-ready data enters your BI architecture.
Data mapping is further accelerated by dedicated fact and dimension loaders that truncate time-intensive staging and complex dimension lookup operations (in historical records are maintained) to simple drag-and-drop mapping. Just connect the destination table to the relevant entity in your dimensional model, and you’re good to go.
Once you’re done designing end-to-end data mappings, you can execute the data flow. Our ETL engine will read the metadata and automatically generate the necessary code to bring data from source to destination. We even offer scheduling and workflow orchestration features to help you automate these operations according to your needs.
Test Concurrently Before Deployment

With ADWB, we’ve built ongoing testing into the very architecture of the platform. Before deploying any of your data models, you’ll have to verify the design to ensure that each entity is configured correctly and that there are no blank fields or inconsistent values. With concurrent testing in place, you can quickly identify errors in your build and correct them before they cause issues for the end-user.
Similarly, we’ve implemented real-time logging and error notifications during dataflow execution, so any problems in your ETL processes can be spotted within the metadata. The result is a stress-tested architecture built to handle even the most complex BI use cases with ease.
Replicate Your Schema in any Leading Database.

Because data models are built at the metadata-level, they aren’t hard-coded for integration with any particular platform. Essentially, what you’ve created is a platform-agnostic schema that can be replicated with ease in any destination database. To make things even easier, we provide support for leading on-premises and cloud data warehouses, so you can choose to build your data warehouse on the infrastructure that best fits your BI needs.
Looking to take advantage of the scalability and performance of Amazon Redshift, establish a connection to the database, and forward engineer. Want to keep your reporting in-house? Select an on-premises provider such as SQL Server or Oracle Database — the choice is yours.
Compare this process to the big-ticket implementations favored in waterfall, where any updates or modifications require another end-to-end round of development, and it’s clear which method is better suited for modern BI.
Experience Metadata-Driven Data Warehousing with Astera DW Builder
Do you want to take advantage of our exciting new data warehousing solution? Get in touch with our experts to learn more about how our metadata-driven architecture can help you get the results you need or for a personalized demo for your specific use case.
Authors:
Adnan Sami Khan



