Astera AI Agent Builder - First Look Coming Soon!
Astera AI Agent Builder - First Look Coming Soon! Apr 29th | 11 AM PT
Apr 29th | 11 AM PT

The Automated, No-Code Data Stack
Learn how Astera Data Stack can simplify and streamline your enterprise’s data management.

What is Zero ETL? Components, Benefits & How Does it Work
Zero ETL is a data integration technique where data is transferred from source to destination without the need for a traditional ETL (Extract, Transform, Load) process. Zero–ETL simplifies data accessibility by enabling seamless querying across disparate data sources without necessitating extensive data movement.
Zero-ETL is a relatively newer approach to data integration and management—a move away from the traditional ETL paradigm. In a zero-ETL architecture, data integration take place in real-time or near-real-time, minimizing the latency between data generation and its availability for analysis.
With zero-ETL, the idea is to carry out transformation during the data querying process. It eliminates time-consuming steps and allows businesses to analyze and query data directly from the source in real time. This process also eradicates the need for intermediate data storage in a staging area.
So, let’s dig further and see how zero-ETL works and how it can be beneficial in certain data management use cases.
How does Zero-ETL Work?
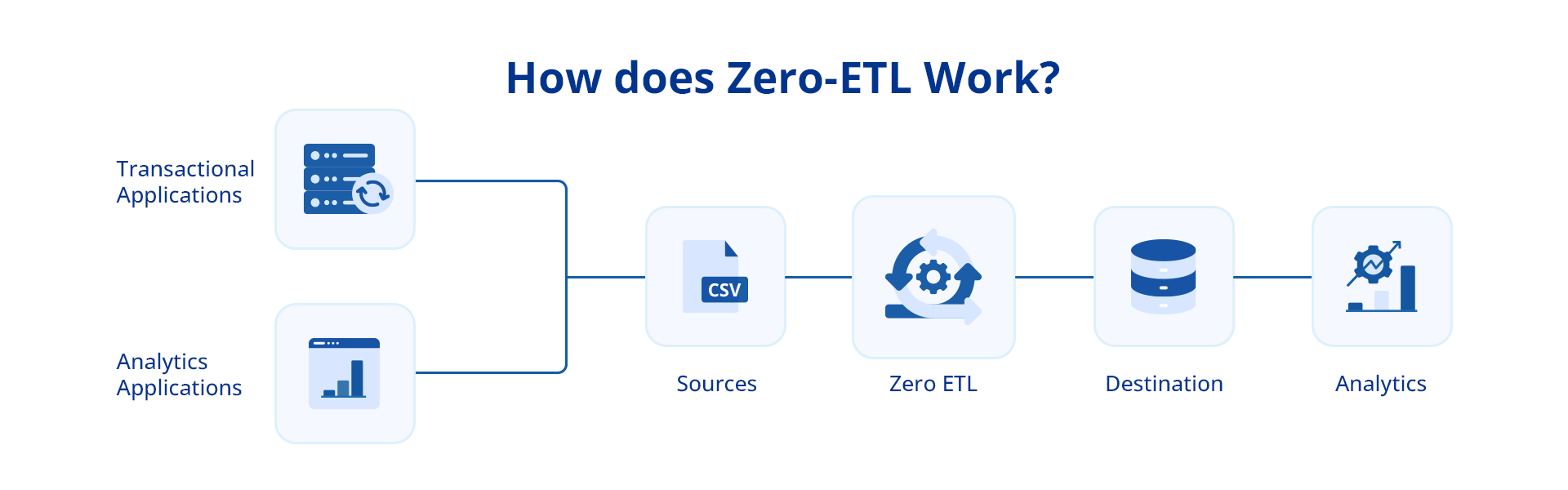
Unlike conventional ETL that revolves around time-consuming data transformation before loading it into the target repository, zero-ETL takes a different approach as it eliminates the reliance on scheduled batch processing in ETL.
It uses technologies like data lakes and schema-on-read (a data storage and processing approach where data is stored in its raw format without needing upfront schema definition) that allow organizations to extract insights from unstructured data sources instantly.
Moreover, zero-ETL also employs data virtualization and federation techniques to provide a unified view without physically moving or transforming it. All this significantly reduces the time spent on data preparation and allows for immediate insights from raw data.
It’s important to consider the key components of zero-ETL to understand how it works. Keep in mind that zero-ETL is not a technology but rather a philosophy and approach to data integration. Therefore, the term “components of zero-ETL” refers to key elements and strategies that contribute to achieving its goals.
So, let’s explore them in detail:
Zero ETL Components
- Real-Time Data Replication
It is a fundamental component of zero-ETL. Organizations use real-time data integration technologies to facilitate the continuous flow of data from source systems to destination repositories. This differs from conventional batch processing methods of ETL, which operate on predefined schedules. Adopting real-time data streaming technologies can also minimize the latency associated with data processing. It also further reduces the dependence on preprocessing and staging of data before analysis.
- Data Lakes and Object Storage
Data Lakes represent another vital component of the zero-ETL framework. They store raw, unstructured, and untransformed data, including diverse types like videos, texts, images, and more. This makes the data immediately available for analysis.
On the other hand, object storage systems allow organizations to directly analyze data stored in its original format and eradicate the need for upfront data transformation. It provides an efficient and scalable way to store and retrieve data as discrete objects, each having the data itself along with associated metadata.
- Data Management Technologies
Data federation and data virtualization are important data management technologies that facilitate the functionality of zero-ETL. They both involve creating a virtual layer that integrates data from diverse sources and provides a unified and abstract view for easier access and querying. All this can be done without the need for physically moving data or transforming it.
- Skilled Employees
Without a skilled team, managing the tools and technologies associated with zero-ETL will be difficult. Therefore, analysts and data scientists require proper training to navigate ETL tools and be able to understand data integration pipelines. Proficiency in SQL is also essential for querying and manipulating data stored in databases or warehouses. All of this is necessary to consider before employing staff on zero-ETL strategy.
- Data Source Diversity
Another component of zero-ETL is the accommodation and integration of a wide range of data sources. Organizations aim to handle diverse data sources without the need for upfront standardization. Data source diversity includes different kinds of information, including structured, semi-structured, and unstructured data.
Zero ETL and Other Non-ETL Data Integration Techniques
Like other non-ETL techniques, Zero ETL prioritizes minimal data movement and transformations for real-time data access and simplicity. However, it’s distinct from other non-ETL methods given their specific approach, level of data processing, and complexity.
Let’s discuss how zero-ETL compares with some of the data integration techniques that don’t primarily involve ETL.
-
ELT (Extract, Load, Transform):
- Similarities:
Both minimize data movement by transforming data after loading.
- Differences:
Staging area: ELT typically uses a staging area for data transformation in the target database, while zero-ETL aims for direct source access.
Complexity: ELT handles complex transformations efficiently in the staging area, while zero-ETL does not involve any transformation.
Latency: ELT introduces some latency due to staging, while zero-ETL prioritizes real-time access.
-
CDC (Change Data Capture):
- Complementary:
CDC can be used with zero-ETL to capture real-time changes efficiently.
- Differences:
Scope: While CDC can be part of an ETL pipeline, it’s not inherently ETL as CDC only captures changes in data. Zero-ETL, on the other hand, aims to eliminate all data movement and transformations.
Initial data: CDC doesn’t handle initial data loads, requiring additional solutions in a zero-ETL context.
-
Data Virtualization:
- Similarities:
Both avoid the physical movement of data, offering virtual access to data.
- Differences:
Performance: Zero-ETL might offer better performance with direct source access compared to virtualization overhead.
Control: Virtualization grants granular control over data access, while zero-ETL relies on source system permissions.
Transformations: May include basic transformations, while zero-ETL minimizes them.
-
API Integrations:
-
Complementary:
APIs can be used within zero-ETL for specific data access needs.
- Differences:
Scope: APIs are targeted access points, while zero-ETL aims for broader data integration.
Complexity: Building and maintaining APIs might be more complex than zero-ETL solutions.
Security: APIs require robust security measures compared to zero-ETL’s reliance on source system controls.
-
Data Federation:
- Similarities:
Both enable querying data across multiple sources without centralizing it.
- Differences:
Control: Zero-ETL focuses on simplicity, while federation offers more granular control over data access and transformations.
Complexity: Setting up and managing federation can be more complex than zero-ETL solutions.
Performance: Depending on the implementation, the data federation process can introduce performance overhead compared to zero-ETL’s direct access.
Zero ETL Benefits
Zero ETL has many benefits that can enhance data integration processes and analytics. Three advantages of zero-ETL are:
Speed
Since there is no data transformation or manipulation involved in the zero-ETL approach, this process tends to be faster than other conventional processes like ETL. In zero-ETL, the emphasis is on direct data movement that enables swift data migrations. Speedy data transfer proves crucial when real-time data delivery is needed, particularly for prompt decision-making.
Streamlined Data Analytics
With zero-ETL, it’s possible to access and analyze data as it flows. Since there is no need for batch transformations and extensive preprocessing, there is reduced latency. Zero ETL ensures the streamlining of data analytics, enabling timely insights and enhancing the overall experience.
Real-time Insights
Zero ETL enables organizations to access and analyze data as it is generated. The data becomes available in real time provided there’s that extensive transformations are not required.
For instance, cybersecurity firms can adopt zero-ETL for real-time threat detection. Since conventional ETL processes introduce delays in processing and analyzing security event logs, firms may experience delays in identifying potential threats. But with zero-ETL, firms can instantly analyze log data as it’s generated and proactively address cybersecurity issues.
Zero ETL Use Cases
ETL is an indispensable approach to data integration, especially when complex data transformation is a requirement. However, there are some scenarios where an organization would be much better off with zero-ETL. Some of these use cases are:
Quick Replication
It refers to the rapid duplication of data from a source to a target system, keeping the target continuously synchronized with the changes in source data. Zero-ETL is well-suited to this scenario as it focuses on real-time data processing and schema-on-read principles. The schema-on-read principles enable on-the-fly interpretation and structuring of data during analysis, thus aligning with the need for quick updates without extensive preprocessing.
Real Time Monitoring & Altering
Zero-ETL proves to be highly effective in cases where continuous monitoring and alerting are required, such as fraud detection applications and network monitoring.
Since it streams data in real-time from different real time sources, zero-ETL allows for instant identification of deviations from expected patterns or suspicious activities. The swift and responsive nature of zero-ETL is advantageous in cases like these where proactive response and timely detection are important.
Customer Behavior Analysis
Customer behavior analysis is another situation where zero-ETL proves more effective than traditional ETL processes. This is due to zero-ETL’s capability of enabling immediate insights without delays. The real-time data streaming feature of zero-ETL ensures that engagement data, customer interactions, and transactions are available for analysis as soon as they occur. This allows businesses to respond instantly to emerging patterns, personalized recommendations, and customer support interactions accordingly.
Zero ETL does not Replace ETL

Zero ETL’s popularity stems from the belief that it is a futuristic approach or even an alternative to traditional data integration processes. The traditional ETL processes have been used in organizations for decades, setting the foundation for many deeper analytics tasks. Since zero-ETL is known for its exceptional speed considering its direct data transfer approach, it still does not completely replace ETL.
Therefore, it’s important to discuss the prevailing misconceptions concerning zero-ETL. Here are some reasons why zero-ETL cannot replace ETL:
Lack of Integration Outside the Ecosystem
Similar to Snowflake with its Unistore, Amazon has been pushing its zero-ETL approach quite a lot lately. For starters, consider its announcement about launching AWS zero-ETL integrations for Amazon Aurora PostgreSQL, Amazon RDS, and Amazon DynamoDB with Amazon Redshift. Accordingly, other players including Google and Microsoft have been following suit.
However, the important thing to note here is that organizations will only be able to realize the gains of zero-ETL as long as they stay within the ecosystem. Since zero-ETL is all about transferring data as quickly as possible, integration with systems outside the ecosystem of, say AWS, can be challenging, if not impossible.
Unable to Handle Complex Transformations
Since the zero-ETL approach depends on in-place processing, it is not ideal for scenarios demanding data transformations or combining data from different sources. Moreover, highly complex data require more development and maintenance resources to maintain zero-ETL solutions.
Compared to zero-ETL, traditional ETL is well-suited for complex data transformations and extensive preprocessing. It allows firms and organizations to structure and clean data before leading it into a target repository.
Lack of Data Quality Assurance
Though zero-ETL is highly responsive and offers an advantage in terms of speed, it may not provide the same level of data quality assurance as ETL. Quality checks must be integrated into the analytics process, introducing the challenge of maintaining data integrity during on-the-fly transformations. This shift in timing and nature of quality checks tells about the need for careful consideration.
Conventional ETL processes include comprehensive data quality checks, like competence consistency, data accuracy, etc., and transformations during the staging phase. This ensures that only accurate data is loaded into the target.
Cost Effectiveness and Batch Processing
Batch processing is often more cost-effective using ETL and it is more practical for handling large volumes of data that can be processed periodically. This is true particularly when real-time or near-real-time data processing is not a restrictive requirement and delays don’t affect important decisions.
Real-time data streaming in zero-ETL incurs higher costs for quick data processing. This makes it less cost-effective in cases where batch processing is ideal for business needs and resource constraints.
Conclusion
Zero ETL can be a viable approach in certain cases due to its swift response and direct transfers. However, it also requires considerable investment in data management technologies and an expert staff to derive actionable insights efficiently.
Both traditional ETL and Zero ETL have their merits and the preference depends on specific use and requirements. When managing data at enterprise level traditional ETL offers a centralised system to not only integrate data from diverse sources but also transform it and improve its quality.
For businesses prioritizing performance and a resource efficient approach, Astera’s merges as a reliable solution for your traditional ETL needs.
Streamline your data handling now with Astera!
Take the Next Step Towards Streamlined Data Operations
For efficient data management, Astera is your go-to choice. Simplify your processes and get reliable results with Astera’s solutions!
Signup Now!
Authors:
Aisha Shahid